

数据库版本:5.7.25-OceanBase_CE-v4.3.5.0
使用过程出现数据库连接失败的问题,同时观察clog不停增加,目前log_disk_size由开始的50G,调整到300G,又调整到400G,同时租户配置的LOG_DISK_SIZE调整到320G,LOG_DISK_IN_USE查询显示占比已经达到80%,在79.98%和80%之间徘徊,目前数据库可以正常连接,可能是什么原因导致?
1 个赞
根据提供的文档片段,OcenBase数据库连接失败且CLOG不停增加的情况,通常可能由以下原因导致:
- 运维问题:clog 盘所在空间被其他用户的文件占用,导致可以利用的空间不足。
- 转储持续失败:这是clog 满盘最常见的原因。当clog中涉及的分区数据已经全部转储到SSTable中,且元信息已经持久化宕机重启起始位点时,clog文件就可以进行回收。所以,如果转储不成功,宕机重启 clog 起始回放位点不推进,CLOG文件是无法进行回收的。建议联系OceanBase技术支持进行进一步诊断。
-
CLOG 磁盘空间使用接近上限:即使log_disk_size和log_disk_utilization_limit_threshold都进行了调整,但CLOG磁盘空间使用依然接近上限,这可能导致新的事务无法写入,从而引发连接失败。建议检查
log_disk_utilization_threshold的值,确保其合理设置,以避免CLOG磁盘空间过早达到使用上限。 -
租户配置不当:确保租户配置的
LOG_DISK_SIZE和log_disk_size匹配,避免因配置不一致导致的问题。
解决方法:
- 确认clog盘是否有其他文件占用空间,如有请清理。
- 检查并优化转储流程,确保转储成功,以便CLOG文件能够被及时回收。
- 调整
log_disk_utilization_threshold的值,适当放宽阈值,但不要超过95%。 - 确认租户配置的
LOG_DISK_SIZE与实际分配的log_disk_size相匹配。
检索到的文档如下:
- OceanBase 数据库性能的影响因素
- BootStrap
- 集群管理 FAQ
- oceanbase clog盘如何瘦身
- oceanbase数据库运行过程中手动删除clog日志
1 个赞
如何诊断CLOG磁盘空间接近使用上限?
学习了,谢谢论坛助手! ![]()
![]()
![]()
查看当前事务是不是过多了,然后查不日志不释放的原因,比方转储出现问题,有长事务,还有其它参数设置的问题
限制clog大小
我记的有个参数可以限制
学习学习
又有收获
学习
show parameters where name in (‘memory_limit’,‘memory_limit_percentage’,‘system_memory’,‘log_disk_size’,‘log_disk_percentage’,‘datafile_size’,‘datafile_disk_percentage’);
集群 server 级资源分配情况
select zone,concat(SVR_IP,’:’,SVR_PORT) observer,
cpu_capacity_max cpu_total,cpu_assigned_max cpu_assigned,
cpu_capacity-cpu_assigned_max as cpu_free,
round(memory_limit/1024/1024/1024,2) as memory_total,
round((memory_limit-mem_capacity)/1024/1024/1024,2) as system_memory,
round(mem_assigned/1024/1024/1024,2) as mem_assigned,
round((mem_capacity-mem_assigned)/1024/1024/1024,2) as memory_free,
round(log_disk_capacity/1024/1024/1024,2) as log_disk_capacity,
round(log_disk_assigned/1024/1024/1024,2) as log_disk_assigned,
round((log_disk_capacity-log_disk_assigned)/1024/1024/1024,2) as log_disk_free,
round((data_disk_capacity/1024/1024/1024),2) as data_disk,
round((data_disk_in_use/1024/1024/1024),2) as data_disk_used,
round((data_disk_capacity-data_disk_in_use)/1024/1024/1024,2) as data_disk_free
from oceanbase.gv$ob_servers;
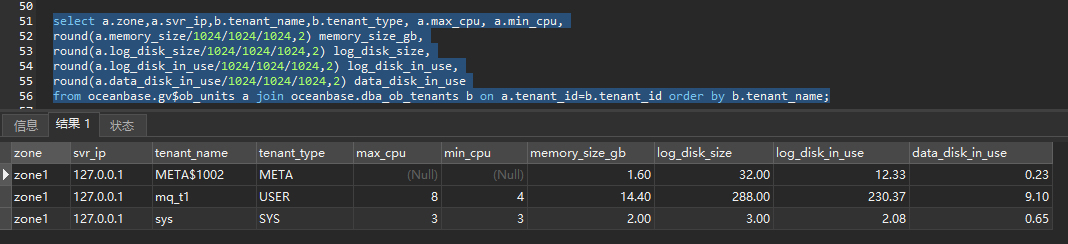
集群租户级资源分配和磁盘使用情况
select a.zone,a.svr_ip,b.tenant_name,b.tenant_type, a.max_cpu, a.min_cpu,
round(a.memory_size/1024/1024/1024,2) memory_size_gb,
round(a.log_disk_size/1024/1024/1024,2) log_disk_size,
round(a.log_disk_in_use/1024/1024/1024,2) log_disk_in_use,
round(a.data_disk_in_use/1024/1024/1024,2) data_disk_in_use
from oceanbase.gv$ob_units a join oceanbase.dba_ob_tenants b on a.tenant_id=b.tenant_id order by b.tenant_name;
如果再出现连接问题 可以使用obdiag诊断一下出现问题前后五分钟的日志
obdiag analyze log
https://www.oceanbase.com/docs/common-obdiag-cn-1000000003607666
alert日志显示:
|ERROR|CLOG|OB_LOG_NEW_DISK_SIZE_NOT_ENOUGH|-4007|0|822017|OmtNodeBalancer|YB427F000001-00063C38E69E266A-0-0|resize_|ob_server_log_block_mgr.cpp:205|“new log_disk_size(51200MB) is not enough to hold all tenants. [suggestion] set log_disk_size greater than 330752MB.”
我设置的log_disk_size为400G,1002租户分配的log_disk_size为320G,数据库无法连接之后,我重启了数据库,重启之后系统的log_disk_size又变成50G了,然后就报这种警报日志,我看文档使用alter system set log_disk_size=‘400G’;改完立即生效,不需要重启了,重启之后是又还原了么?

集群server级资源分配情况
(ZONE, observer, CPU_CAPACITY_MAX, CPU_ASSIGNED_MAX, cpu_free, memory_total, system_memory, mem_assigned, memory_free, log_disk_capacity, log_disk_assigned, log_disk_free, data_disk, data_disk_used, data_disk_free)
(‘zone1’, ‘127.0.0.1:2882’, 16, 11, 5, 24.00, 4.00, 18.00, 2.00, 400.00, 323.00, 77.00, 32.00, 10.15, 21.85);
你应该使用的是obd搭建的 你发一下yaml文件看一下
obd cluster list --查看集群信息
obd cluster edit-config {集群名} --保存到文本里 发一下
看着之前你设置的应该是集群的log_disk_size 看你的memory_limit是42G 基本上要求是内存的三倍 应该是租户的log_disk_size分配的不够 导致的报错
我调整一下,之前一直是通过alter system set log_disk_size=‘400G’;来设置的。
学习一下
如果是obd部署的 麻烦提供一下yaml文件