

这篇教程文档,相比前面几篇,可能会稍微偏底层实现原理一点儿。
大家可以根据需求,选择性地阅读感兴趣的部分。
在这篇文档中,我打算简单介绍一下 OceanBase 在 4.x 版本中,相较于 3.x 版本,对 truncate table 做的两个比较重要的优化:
- 第一个优化是 truncate table 实现方式的变更,这里会牵扯出一丁点儿 OceanBase 数据库大版本的进化史。
- 第二个优化是 DDL 变更的并行架构优化,主要也是为了能让 truncate table 操作变得更快。
边学边练,效果拔群
正所谓 “纸上得来终觉浅,实践才能出真知”,强烈推荐大家点击下面的链接,根据在线体验页面左边的实验文档,亲手体验一把并行 DDL 带来的性能提升!
-
在线实验地址:《通过并行 Truncate Table 提升大批量清空表的性能》
- 这个实验可以使用以下连接串连接数据库:
obclient -h127.0.0.1 -uroot@sys -P2881 -Dtestdb -A
说明:
因为是实验环境,所以可以偷懒使用 sys 租户。
但生产环境中尽量不要在 sys 租户里直接创建数据库对象,尽量在用户租户里进行相关操作。
- 在进行实验的过程中,建议大家尝试通过 oceanbase.__all_ddl_operation 系统表,自行探索和分析一下 truncate table 这个 DDL,在 4.x 中实现方式和 3.x 中实现方式的不同点。
- 下图是在 ODC 中,用 3.x 版本执行 truncate table,并查看系统表记录的 DDL 执行序列:
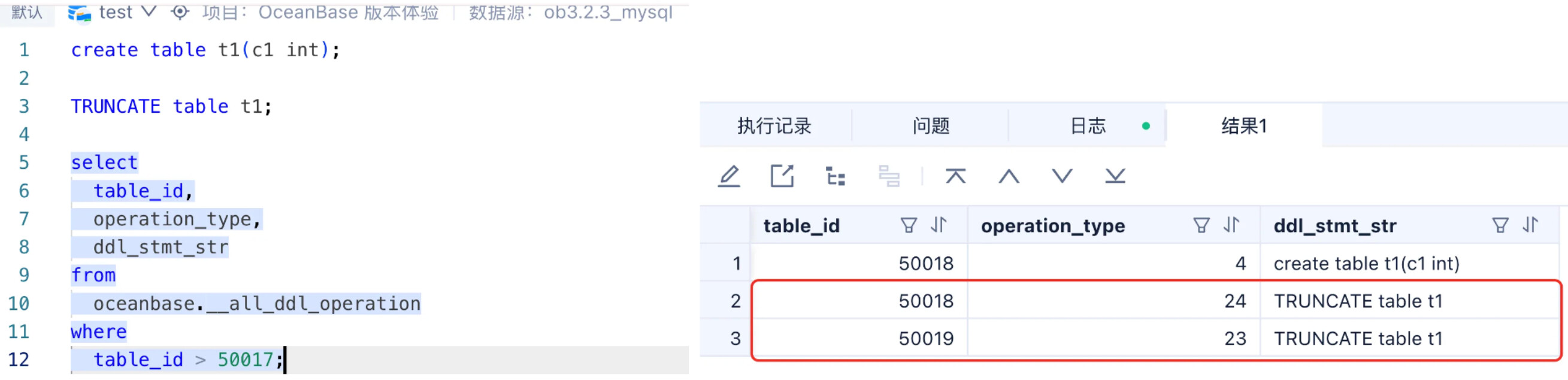
在上图中,大家可能会发现一个有趣的地方,就是在 OceanBase 3.x 及更早的版本中,我只执行了一条 truncate table,但系统记录的 DDL 中却有两条 truncate table,而且 table id 好像还在执行 truncate table 的过程中,发生了变化?
是不是感觉 operation_type = 24 的这行数据,像记录的是把 t1 表给 drop 的动作,然后 operation_type = 23 的这行数据,像记录的是重新创建了一个新 t1 表的动作?(Operation Type 是个枚举值,详见:ob_schema_service.h)
大家可以到在线体验的 4.x 环境中,也执行一下这个同样的 SQL 序列,拿结果和上面那张截图对比下,看看能获得什么样的发现?
# 数据库的连接串
obclient -h127.0.0.1 -uroot@sys -P2881 -Dtestdb -A
create table t1(c1 int);
TRUNCATE table t1;
select table_id, operation_type, ddl_stmt_str
from oceanbase.__all_ddl_operation
where table_id > 500000
and ddl_stmt_str != '';
小提示:
- 需要先登录 OceanBase 账号,才能初始化屏幕右边的实验环境进行实验。
- 在实验环境里,干什么都可以。大家不要受限于屏幕左边的实验手册,可以天马行空地做一些你感兴趣的事情,或者验证一些你对 OceanBase 官网文档的疑问、以及自己的猜想等等(甚至可以尝试怎么搞能把这个实验环境里的 OBServer 给弄崩)。
- 欢迎大家平时在学习 OceanBase 的过程中,也都能充分利用在线体验页面为您提供的一些实验环境,来体验 OceanBase 中您感兴趣的新特性。
2025.07.30 更新
今天教程交流群里有老师提问说:“truncate partition,是否也是 drop 掉分区,然后再 add 回来呢?”

drop partition 不需要像删表那样去处理表上的那些附属对象,所以个人理解 truncate partition 无论是实现成 drop partition + create partition,还是实现成只替换分区对应的 tablet id,不改 partition id,影响都不大。
欢迎大家在实验环境里也自行设计一个实验,验证一下这个猜想是否是正确的。
附上一个简单的 SQL 执行序列供大家参考(需要自行替换其中的 table id):
CREATE TABLE t_log_part_by_range (
log_id bigint NOT NULL
, log_value varchar(50)
, log_date timestamp NOT NULL
) PARTITION BY RANGE(UNIX_TIMESTAMP(log_date))
(
PARTITION M202001 VALUES LESS THAN(UNIX_TIMESTAMP('2020/02/01'))
, PARTITION M202002 VALUES LESS THAN(UNIX_TIMESTAMP('2020/03/01'))
, PARTITION M202003 VALUES LESS THAN(UNIX_TIMESTAMP('2020/04/01'))
, PARTITION M202004 VALUES LESS THAN(UNIX_TIMESTAMP('2020/05/01'))
, PARTITION M202005 VALUES LESS THAN(UNIX_TIMESTAMP('2020/06/01'))
);
select table_id from oceanbase.__all_table
where table_name = 't_log_part_by_range';
select table_id, part_id, part_name, is_deleted, gmt_modified
from oceanbase.__all_part_history
where table_id = xxxx order by gmt_modified;
ALTER TABLE t_log_part_by_range TRUNCATE PARTITION M202001, M202002;
select table_id, part_id, part_name, is_deleted, gmt_modified
from oceanbase.__all_part_history
where table_id = xxxx
order by gmt_modified;
如果被 truncate 的 partition 的 part_id 发生了变化,说明就是 drop + create。
大家不妨也直接通过实验,来验证下这位老师的猜想是否是正确的。大家还可以继续添油加醋,例如也加上 oceanbase.__all_ddl_operation 之类的东西看看能有什么其他的发现~
-
课后小测地址:【DBA 实战营】并行 DDL 课后小测
- 大家完成课后小测,并在小测中上传实验截图,就可以自动从社区论坛中获取 10 积分,并自动获得抽奖资格,有机会获得实体礼物或积分奖励。
- 本期临时改下规则,抽奖中的积分奖励,从 200 积分 * 1 变成 50 积分 * 4,并行发给四个通过小测的用户。

大家如果都不来做实验的话,老板以后就不会再让兹拉坦更新这些教程文档了。大家的对在线实验的支持,是兹拉坦的老板让兹拉坦更新这些教程内容的动力!
闲言少叙,正文开始。
truncate table 实现方式变更
3.x 版本的 truncate table
在 3.x 版本, truncate table 在实现上会被转换成 drop table + create table。例如执行一条 DDL truncate table t1,内部会在同一个事务中执行 drop table t1 和 create table t1。
4.x 版本的 truncate table
OceanBase 在 4.x 版本新增加了一个 tablet 的概念,这是一个用户不感知的物理存储层的概念,表示可以迁移的数据块。基于这个 tablet,4.x 的 truncate table 实现上只需要修改分区对应的 tablet,不再复用 3.x 版本的 drop table + create table 的流程。
即在 4.x 版本的 truncate table 中,实现变成了删除旧 tablet + 创建新 tablet,当 table 上的附属对象(例如 column、constraint、foreign key、partition、index 等)较多时,truncate table 性能可以得到巨大的优化。
简单来说,性能得到优化的原因,就是 4.x 上 truncate table 前后 table 的元数据不会发生变更,只需要修改一下和存储相关的 tablet_id 即可。如果没理解前面这句话,下面就为你进行更详细的说明。
4.x 版本为什么要调整 truncate table 的实现方式?
在 OceanBase 还是 3.x 版本时,部分客户会在业务逻辑中大量使用 truncate table 语句,然后会发现 OceanBase 中 truncate table 的性能可能略低于 Oracle。
truncate table 的性能消耗来自于两部分 —— 系统表数据的更新,以及分区实体的创建。后者在 3.x 版本上是需要创建 paxos 成员组的,步骤较多,但是在 4.x 的日志流架构下,新建分区只是在日志流内数据的操作,性能会有大幅度的提升。而性能消耗的另外一部分是系统表数据的更新,要消除这一部分的开销,就只能改变 truncate table 的实现方式了。
之前接触过一个使用 OceanBase 3.x 版本的金融大客户(四大行之一),他们的业务有上万张表,每张表都有几百个 column 和几百个 check 约束,所以每张表在 oceanbase.__all_column 和 oceanbase.__all_constraint 系统表中都会记录上百行数据。
3.x 版本每次 truncate table 操作都要在 drop table 时对这些元信息执行删除操作,在 create table 时再对这些元信息执行写入操作,当 table 上的附属对象较多时,大量附属对象元信息的删除和写入会让 truncate table 耗费大量的时间。
而 OceanBase 4.x 中 truncate table 的实现不再修改表的元数据信息,所以 oceanbase.__all_column、oceanbase.__all_constraint 等系统表的数据都不会发生改变。数据的清除通过更换 tablet 来实现。oceanbase.__all_table 表内会增加一列 tablet_id 表示一张表对应的 tablet,truncate table 时创建一个新的空 tablet,将新 tablet_id 写入 oceanbase.__all_table 表替换之前的旧值,这样就完成了 truncate 表的操作,之后旧的 tablet 即可删除。
对于分区表,会在 oceanbase.__all_part 表中记录每个分区对应的 tablet_id,truncate table 时将每个分区对应的 tablet 替换成新的空 tablet 即可。
熟悉 Oracle 的同学可以把 table_id 对应成 Oracle 的 object_id,把 tablet_id 对应成 Oracle 的data_object_id,上述 OceanBase 4.x 版本 truncate table 的实现方式就和 Oracle 的实现逻辑是类似的了。
并行 DDL 优化
原理简述
OceanBase 在从 1.x 到 3.x 的历史上,一直都把 DDL 作为用户低频且需要严格管控的操作来对待,但是随着业务的不断开拓,面对的客户需求越来越复杂,对 DDL(特别是 truncate table)的性能挑战声音也越来越多。
之前 OB DDL 在性能上的主要瓶颈是:数据库对象的变更事务在架构上完全串行执行(由事务内对 oceanbase.__all_ddl_operation 系统表加特殊行锁来保证),因此导致 RS 在 DDL 流程中完全依赖事务处理。
在 4.x 版本中,DDL 请求保持统一转发至 RS DDL 队列,由单个 DDL 调度线程消费处理。但是在这里扩展了一组 DDL 并行子线程,专门处理可并发执行的 DDL 子任务(truncate table)。
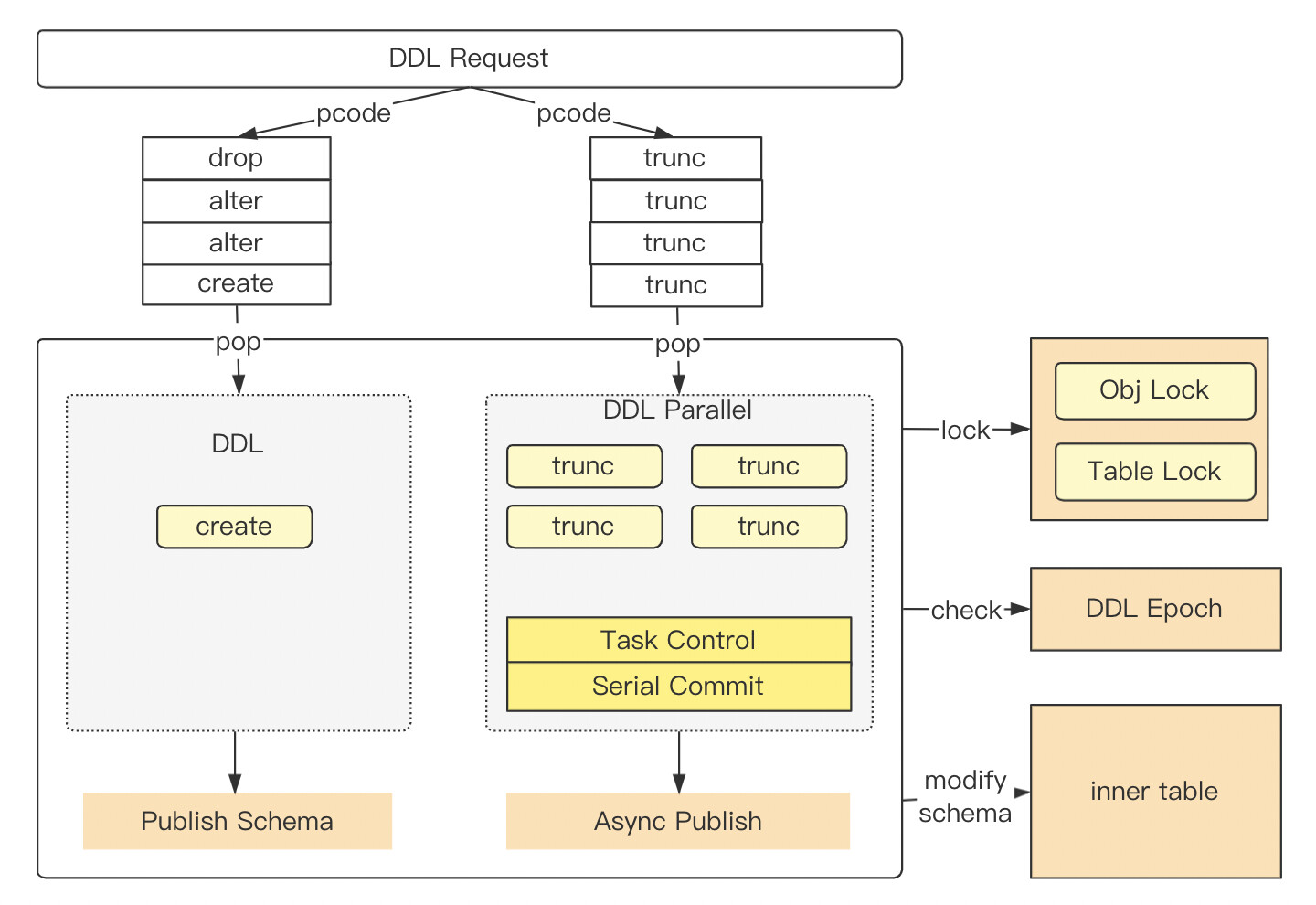
在最新版本中,truncate table 变为了:并行执行,按序(串行)提交。由 task controller 控制事务的提交,保证 schema_version 分配顺序和事务提交顺序一致。
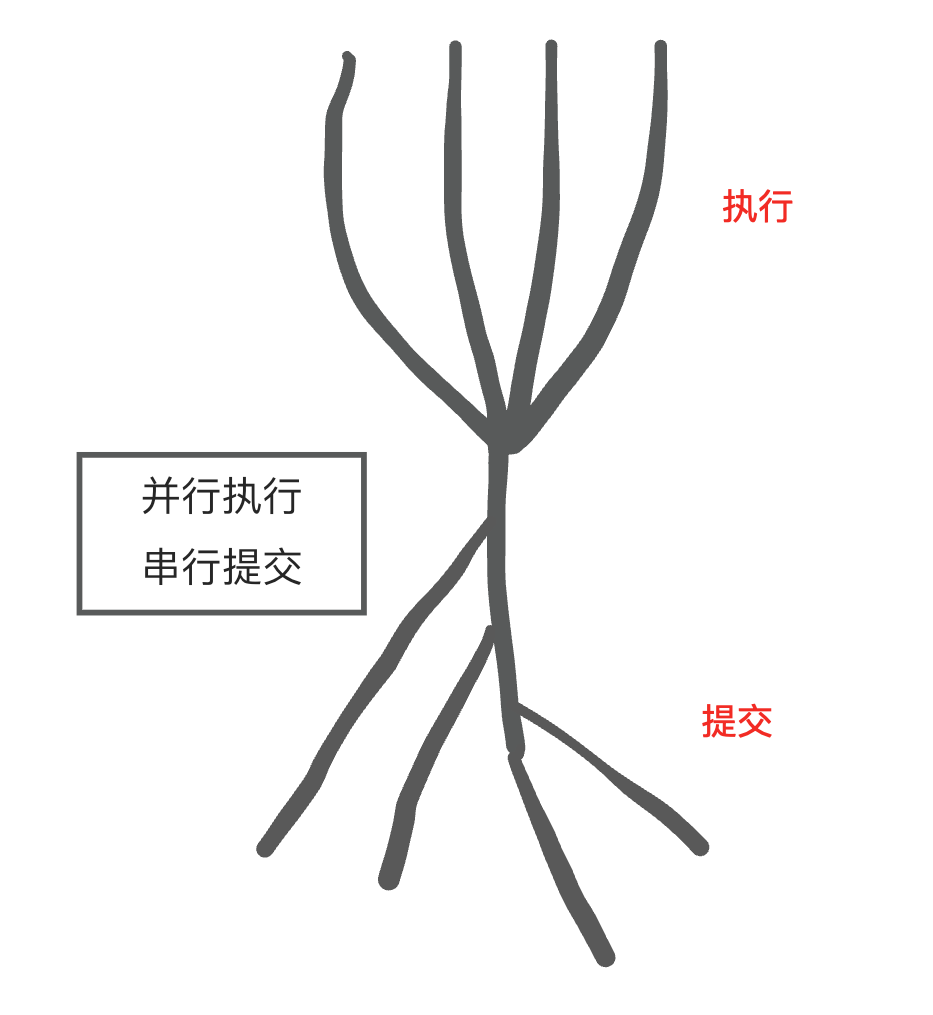
简单来说,truncate table 在支持并行前,和其他 DDL 请求一样,会放在队列中等待串行执行;truncate table 在支持并行后,会有多线程消费并行执行。
个人觉得,大家对 OceanBase 中并行 DDL 的实现原理,了解到这种程度,就已经足够了。更详细的流程,会涉及到更底层的实现逻辑,怕大家不爱读,所以也就不在这里赘述了。
如何开启
4.x 上新建租户的并行 DDL 功能是默认打开的,一般不需要调整。
还可以通过配置项 _parallel_table_creation 以及 _parallel_ddl_control 控制。
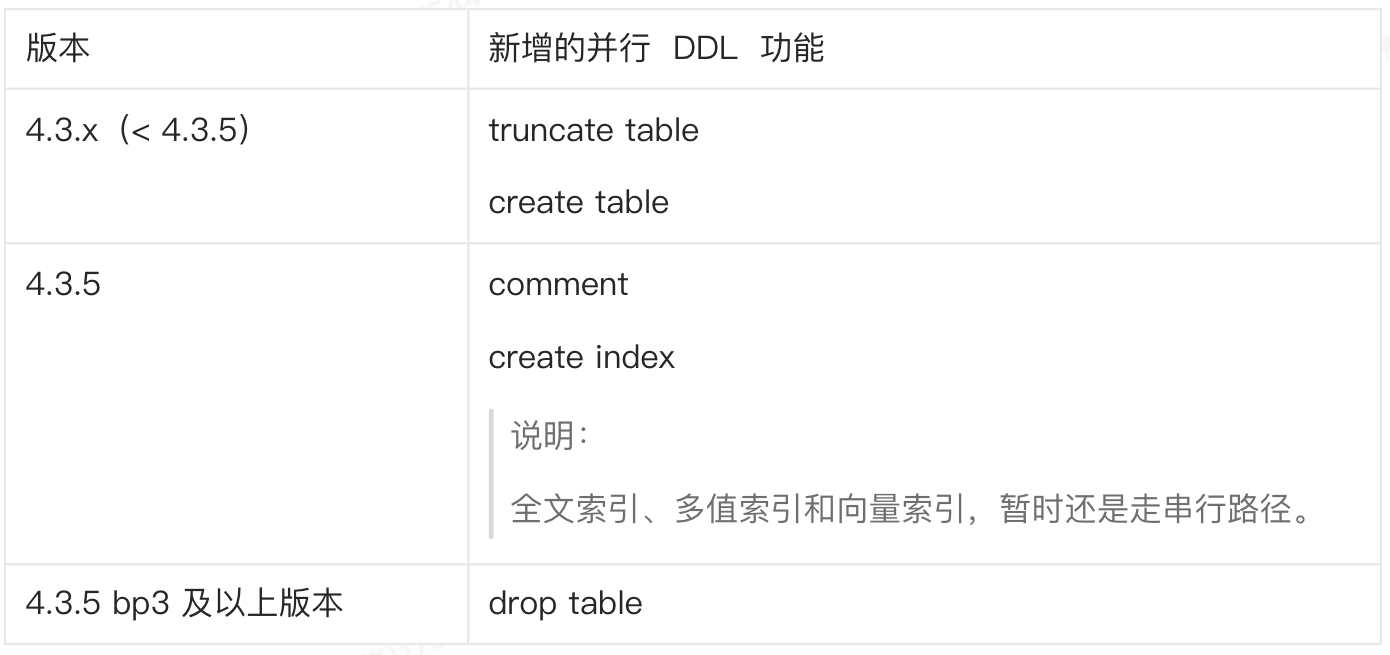
并行 DDL 功能开放进展
4.3 之前版本:
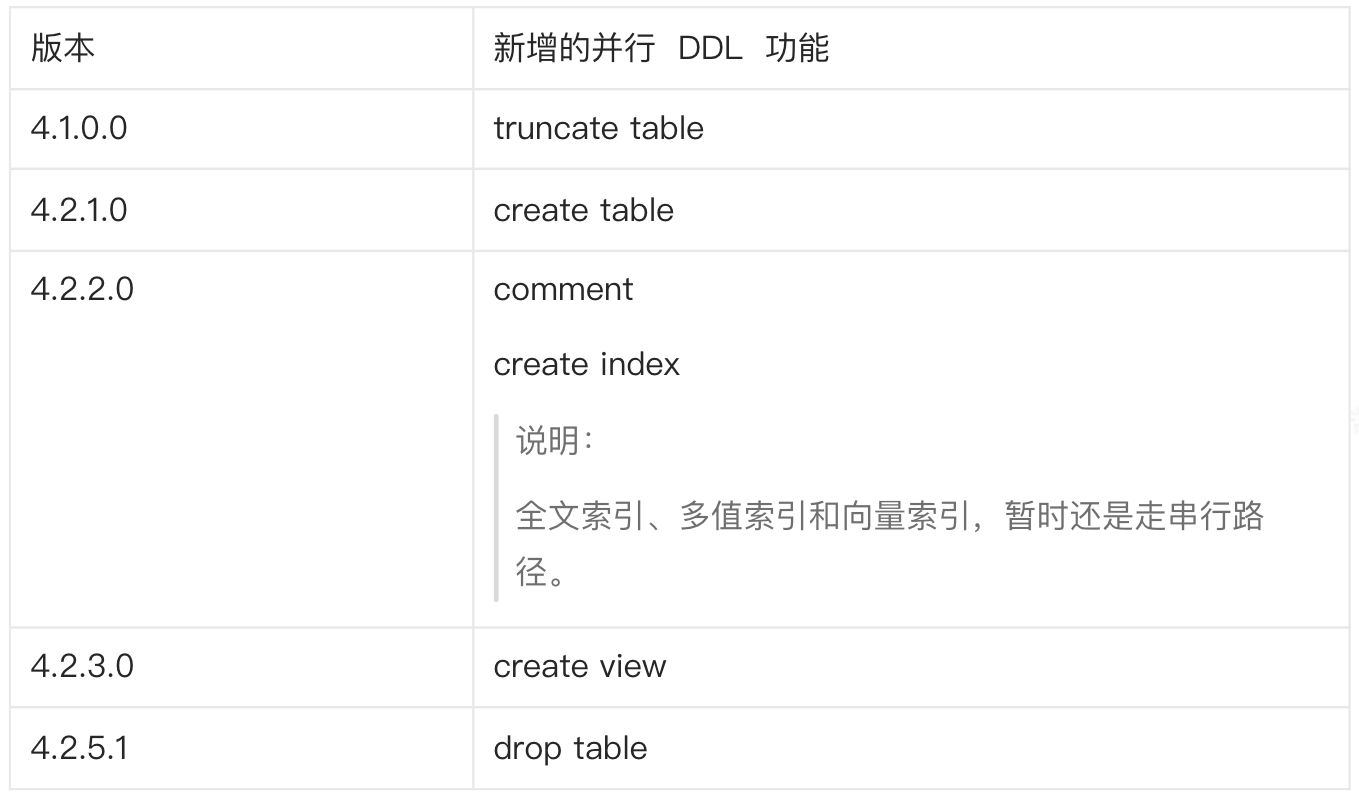
4.3 及之后的版本:
OceanBase 3.x 及更早版本的批量数据清理策略最佳实践
下面这部分内容均摘自 OceanBase 社区公众号 “老纪的技术唠嗑局” 中的一篇文章《OceanBase 批量数据清理突破性能瓶颈》,欢迎大家关注~

说明:
不用 3.x 这种古早版本的用户,可以直接跳过这一部分的内容。
在 3.x 及更早版本中,TRUNCATE TABLE 操作在租户内串行执行,批量清理大量小表时可能成为性能瓶颈。此时,采用并发 DELETE 并分批提交,通常能获得更优的清理效率。
业务场景特点
- 大量小表:典型系统含有数百至数千张表。
- 数据量小:单表数据量通常在几百至几万行。
- 频繁清表:日终、月末等时间点需要批量清理数据。
- 时间窗口要求严格:业务处理时间窗口紧张,数据清理效率直接影响后续业务处理。
问题痛点
- 串行执行限制:OceanBase 3.x 中 TRUNCATE TABLE 操作在租户内不能并行执行。
- 执行效率低:当需要清理数百张表时,串行执行导致总耗时线性增长。
解决方案
清表效率不足将会引发性能瓶颈凸显、批处理窗口延长、系统资源利用率失衡等连锁问题,影响后续业务处理。
常见的解决方案一般包括以下几种:
批处理设计
- 创建临时表存储需要处理的表名。
- 动态生成并执行 DELETE 语句。
-- 创建表存储需要处理的表名
CREATE TABLE tables_to_clean (table_name VARCHAR(100));
INSERT INTO tables_to_clean VALUES
('fund_daily_position'), ('fund_transaction'), ...;
-- 动态生成并执行 DELETE 语句
BEGIN
FOR r IN (SELECT table_name FROM tables_to_clean) LOOP
EXECUTE IMMEDIATE 'DELETE FROM ' || r.table_name;
END LOOP;
END;
并行度调整
- 设置会话级别并行度。
- 增加工作区内存。
- 设置适当并行度。
-- 设置会话级别并行度
SET ob_sql_work_area_percentage = 30; -- 增加工作区内存
SET parallel_servers_target = 16; -- 设置并行度
会话并行
- 使用多会话并发执行 DELETE 操作。
- 根据表数量动态分配会话组。
事务管理
- 分批提交,避免单个大事务
- 每批处理部分表
- 阶段性提交
-- 分批提交,避免单个大事务
BEGIN
FOR i IN 1..10 LOOP
-- 每批处理部分表
DELETE FROM table_group_1;
DELETE FROM table_group_2;
COMMIT; -- 阶段性提交
END LOOP;
END;
性能测试
测试环境如下:
- OceanBase 4.3.5 版本。
- 集群配置:单节点单副本,每节点 16 核 64G。
- 测试数据集:100 张表,每表 1000 行数据。
- 租户规格:CPU 为 8C,内存为 32G。cpu_quota_concurrency 值为 4。
测试结果如下:
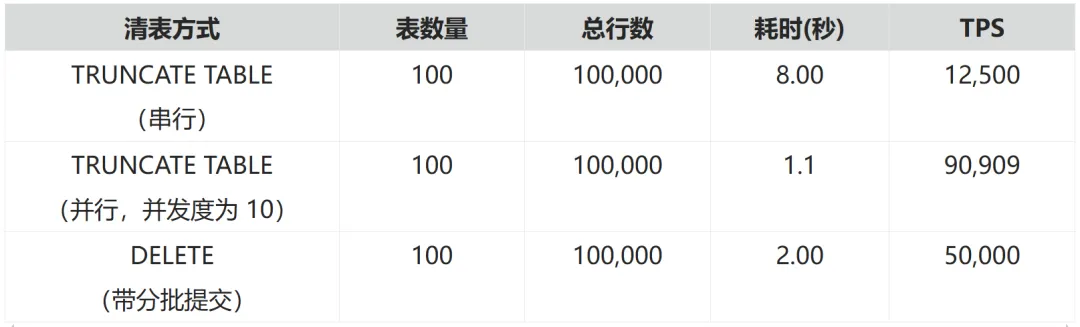
可以看出:
- TRUNCATE TABLE(串行)方式耗时 8 秒。
- TRUNCATE TABLE 方式(并行)耗时 1.2 秒。
- 带分批提交的 DELETE 方式耗时 2 秒。
- TRUNCATE TABLE(并行)的 TPS(83,333)高于其他两种方式。
- TRUNCATE TABLE(并行)的性能优于其他两种方式。
在真实环境中的性能表现会因以下因素而有显著差异:
- 实际的硬件配置和系统负载
- OceanBase 数据库具体版本和配置参数
- 表结构、索引数量和约束类型
- 实际数据量和数据分布特征
您可以使用以下方式监控性能指标:
-- 监控执行情况
SELECT * FROM gv$session_longops WHERE opname LIKE '%DELETE%';
-- 监控资源使用
SELECT * FROM gv$sysstat WHERE name LIKE '%parallel%';
在您实施任何优化方案前,建议在与生产环境相似的测试环境中进行实际测试,以获取准确的性能数据。
注意:
- DELETE 操作会产生 undo 日志,需确保有足够的 undo 空间。
- 对关联表的清理需考虑引用完整性约束。
- 定期执行 ANALYZE TABLE 维护统计信息。
以上测试结果仅为特定环境下的示例,实际效果需结合您的业务环境和系统配置进行评估。
总结
在 OceanBase 数据库环境下处理批量小表数据清理时,使用并行 TRUNCATE TABLE 策略在 4.x 版本下可以显著提升系统性能和资源利用率。在 3.x 版本中,建议使用带分批提交的 DELETE 方法。通过合理设计批处理逻辑和并行度,可以缩短批量清表操作的时间窗口,为业务处理提供更充裕的时间保障。
具体建议如下:
- OceanBase 4.x:推荐使用并行 TRUNCATE TABLE;
- OceanBase 3.x:推荐使用带分批提交的 DELETE;
- 根据不同版本选择最优清表策略,提升系统整体性能。
此最佳实践特别适用于表数量多但单表数据量小的业务场景,可有效解决 OceanBase 中 TRUNCATE TABLE 操作不能并行的局限性,缩短批处理窗口,为后续业务预留充足时间,最终实现系统资源的均衡利用与业务连续性的可靠保障。