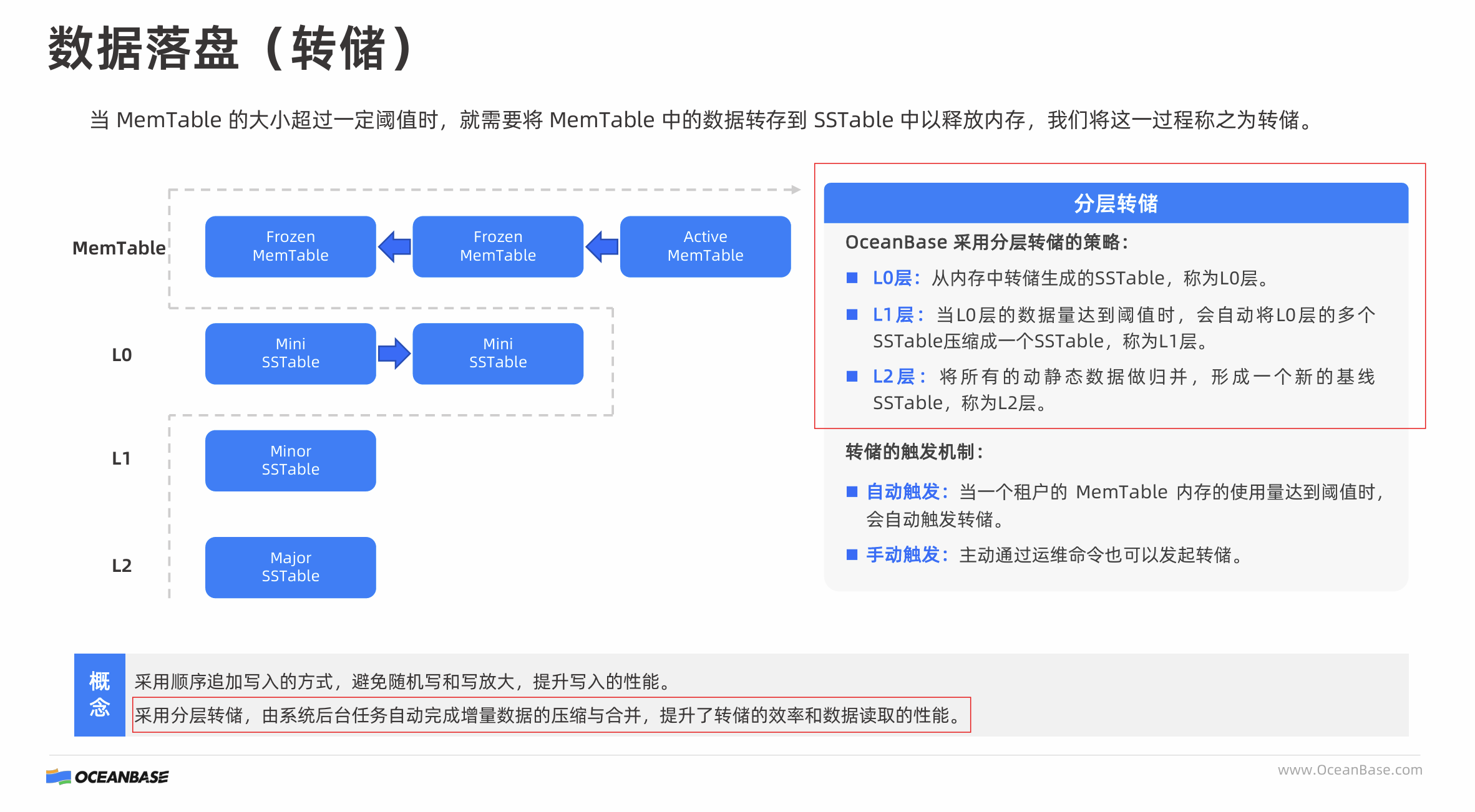
在OceanBase数据库中,多层转储机制有哪些特点?(多选题)
A、通过分层转储,提高了数据读取的性能
B、通过合并操作,减少了磁盘空间的使用
C、通过减少随机写入,延长了存储设备的寿命
D、通过增加数据版本,提高了数据查询的实时性
看模拟题答案是选的BC,网上一些资料把A也选入,看ppt“采用分层转储,由系统后台任务自动完成增量数据的压缩与合并,提升了转储的效率和数据读取的性能。” 那么应该是有提高数据读取性能,A应该也要选上吧?
在OceanBase数据库中,多层转储机制有哪些特点?(多选题)
A、通过分层转储,提高了数据读取的性能
B、通过合并操作,减少了磁盘空间的使用
C、通过减少随机写入,延长了存储设备的寿命
D、通过增加数据版本,提高了数据查询的实时性
看模拟题答案是选的BC,网上一些资料把A也选入,看ppt“采用分层转储,由系统后台任务自动完成增量数据的压缩与合并,提升了转储的效率和数据读取的性能。” 那么应该是有提高数据读取性能,A应该也要选上吧?
分层转储会降低读的性能,因为分层转储会使读取数据的路径变长,比如读取一条数据,需要去MEM TABLE、MINI SSTABLE 、MINOR SSTABLE、MAJOR SSTABLE 中去查找,查找的层数多了肯定性能就差了,另外分层转储的目的是快速释放memtable中的内存空间,防止内存被写爆,分层转储是在读取和写入之间做了均衡
66
BCD,A如来轩所说是错误的
goody!!
A肯定是不对的
来轩老师总结得比较清楚了,简单说就是分层架构会需要到更多的地方去查数据。合并后缩短了分层导致的路径开销。
因为分层多了性能下降所以得有合并
这个B对吗?我怎么觉得分层转储增加了硬盘空间的使用,分层转储占用的空间肯定比直接从内存一步到位合并到基线数据占用的空间大吧?分层转储主要目的是“小步快跑”,在进行转储合并的时候减少对用户的影响。
答案应该是bc, a答案分层后读取链路变长不利于读取,d答案就不用解释了。b答案虽然分层浪费空间,但是合并会节省空间。c答案转储是顺序写,不是随机写
A的问题是啥,分层转储应该是有利于读的
多层转储将数据分为内存中的活跃数据(如 MemTable)和磁盘上的分层存储(如 SSTable)。系统会定期将增量数据合并为有序的大文件(SSTable),并进行压缩和索引优化。这种分层结构使读取操作能直接定位到有序的磁盘文件,减少随机 IO,同时通过索引快速定位数据,显著提升读取性能。官方 PPT 明确提到 “提升了数据读取的性能”,因此 A 正确。
多层转储的合并过程会将多个小文件(增量数据)合并为大文件,并对数据进行压缩(如行压缩、列压缩),同时清理过期版本数据。这一过程减少了碎片文件和冗余数据,有效降低磁盘空间占用,因此 B 正确。
OceanBase 的转储机制采用 “写时复制” 和批量合并策略,将大量随机小写入转化为批量的顺序大写入(合并到 SSTable)。顺序写入对磁盘(尤其是 SSD)的磨损远小于随机写入,延长了存储设备的寿命,因此 C 正确。
多层转储中,数据版本的增加是为了支持多版本并发控制(MVCC),确保事务隔离性,而非直接提高查询实时性。查询实时性主要依赖内存数据访问和索引优化,与版本数量无关。因此 D 错误。
结论:正确选项为 A、B、C。
得找题库里的答案
非常好
“读取路径变长”这个tradeoff是LSMTree为了解决随机写和写放大问题的同时而引入的问题,不是分层转储引入的;与之相反的,分层转储方案恰恰就是针对“读取路径变长”这个问题而提出的解决方案,其目的就是提升读取效率。在分层转储方案中,MemTable内存访问、L0层转储、L1层压缩、L2层归并合在一起才是完整的分层转储方案,而整个分层转储方案的提出就是为了提升读取速度,用来解决LSMTree引入的“读取路径变长从而读取效率变差”这个问题。所以,如果说“通过分层转储,提高了数据读取性能”是错的,那么整个分层转储方案的提出就没有意义了。
BCD吧
分层转储是 OceanBase 数据库为了优化转储性能和减少内存压力而引入的一种策略。以下是分层转储的主要意义和优势
提高转储速度:
单一转储 SSTable 的问题:在 OceanBase 数据库 V2.1 及之前的版本中,系统在同一时刻只会维护一个转储 SSTable。随着转储次数的增加,转储 SSTable 的大小越来越大,导致转储速度变慢,甚至可能引起 MemTable 内存不足 。
分层转储的优化:通过引入 L0 层,被冻结的 MemTable 会直接 Flush 为 Mini SSTable。当 Mini SSTable 的数量达到一定阈值时,会触发下压合并到 L1 层,形成新的 Minor SSTable。这种方式减少了每次转储需要操作的数据量,提高了转储速度。
降低写放大:
写放大:在传统的转储方式中,MemTable 中的数据与转储 SSTable 中的数据进行归并时,会带来较大的写放大,即需要写入大量数据。分层转储通过 L0 层的多层结构,延缓了到 L1 层的合并,从而降低了写放大
写放大系数:__minor_compaction_amplification_factor 参数控制 L0 层内部多个 Mini SSTable 转储的时机,默认为 25。当所有 Mini SSTable 的总行数达到 Minor SSTable 的写放大系数比例后,才会触发 L1 层转储,否则触发 L0 层转储。
优化内存管理:
内存压力:传统的转储方式可能导致 MemTable 内存不足,特别是在高写入负载的情况下。分层转储通过将 MemTable 直接 Flush 为 Mini SSTable,及时释放内存,避免了内存爆满的问题
内存淘汰:即使在转储过程中,OceanBase 数据库的 Row Cache 和 Block Cache 也会根据访问热度进行淘汰,确保内存的有效利用
简化合并逻辑:
合并效率:L0 层的 Mini SSTable 和 L1 层的 Minor SSTable 都是基于 Rowkey 有序的,这简化了后续的合并逻辑,提高了合并效率
合并时机:minor_compact_trigger 参数控制 Mini SSTable 向 Minor SSTable 下压的阈值,默认为 2。当 Mini SSTable 数量达到 2 时,会下压到 L1 层形成新的 Minor SSTable
多副本一致性:
基线数据:L2 层的 Major SSTable 作为基线数据,在合并时产生。为了保证多副本间的基线数据完全一致,Major SSTable 保持只读,不发生实际的合并动作
分层转储虽然在许多方面带来了显著的性能提升和资源管理优化,但也存在一些缺点。以下是分层转储的主要缺点:
读放大:
更长的扫描链路:在分层转储结构中,数据会分布在多个层级(MemTable、Mini SSTable、Minor SSTable 和 Major SSTable)中。在进行数据扫描时,需要依次扫描这些层级,增加了读取路径的长度,从而加剧了读放大。
数据冗余:由于数据会存在于多个 Mini SSTable 中,这可能导致数据冗余,进一步增加读取时的 I/O 开销。
空间放大:
数据冗余:分层转储结构中,数据在多个 Mini SSTable 中存在,导致数据冗余。这不仅增加了读取时的 I/O 开销,还增加了存储空间的需求。
多层存储:L0 层内部可以分裂成多层,每层可以容纳多个 SSTable。在最坏情况下,L0 层可能需要持有大量的 SSTable,进一步增加存储空间的使用。
复杂性增加:
合并逻辑复杂:分层转储引入了更多的合并层次和逻辑,需要确保参与合并的所有 SSTable 的 Version 必须邻接,这增加了系统的复杂性
配置管理复杂:分层转储涉及多个配置项,如 minor_compact_trigger、__minor_compaction_amplification_factor 和 major_compact_trigger,合理配置这些参数需要更多的管理和监控工作
性能波动:
合并任务耗时:虽然分层转储可以降低写放大,但当 L0 层的 SSTable 数量达到阈值时,触发的合并任务可能会耗时较长,尤其是在分区数目很多的表上
内存释放延迟:在某些情况下,转储合并任务耗时较长可能导致 MemStore 内存无法及时释放,从而引发内存不足的问题
首先谢谢您的详细解答!
如此看来,这道题目本身出的是有问题的。因为“提高数据读取性能”这句话并没有设置比较的前提,也就是“相比什么”“提高了数据读取性能”。从整个LSMTree->单一转储->分层转储的优化历程来看,单一转储是为了解决LSMTree的读取性能下降,而其本身又带来了其他的问题,所以又提出分层转储来解决这些问题,但是又造成了读取性能的一些损失,所以才有了合并这个步骤的提出。但以用户角度单从现在4.x的整体“分层转储”机制(MemTable+落盘+压缩+合并)来看,这个机制整体就是为了解决LSMTree带来的读取性能下降这个问题的。至少从教材材料来看,前面一页先提LSMTree解决了写放大和随机写问题,但带来了“读取路径长,读取速度下降”问题,然后用六页讲了OB的存储引擎是如何解决这个读取速度下降问题的(MEMTABLE,SSTABLE,落盘,合并,压缩),且在落盘(转储)这一页专门提出“采用分层存储,由系统后台任务自动完成增量数据压缩与合并,提升了转储的效率和数据读取性能”。那么,除非是教材这句话欠妥应该删除,否则就应该修改这个题目。