

背景
通常,数据库中的表数据,会存放在数据库自身的存储空间中,而外表的数据,则存储在外部存储服务中。外表可以访问数据库外部的文件,并读取文件中的数据。
在一般的业务场景中,经常遇到需要利用数据库处理外部数据的情况。这些数据可能来源于应用程序产生,也可能是由其他业务系统产生。没有外表时,只能通过 ETL 工具将外部数据库导入到数据库内部的表中,再进行分析处理。而外部表可以直接读取外部数据文件,这样做有几个好处:
- 可以减少数据的拷贝,节省数据库存储空间。
- 提高数据的共享,避免数据出现不一致的情况。
- 删除外表时数据不会被删除。
需要额外说明的是,外表不支持 DML,这个应该很好理解。
示例 1
下面展示一个通过外表读取 OceanBase 日志的小 demo,目的是让大家快速理解外表的作用。
首先来到 OceanBase 的日志目录,里面有一些以 .log 结尾的文件。
外表的数据文件可以放在不同云服务的对象存储服务中。

然后创建一张外表。
目前 OceanBase 支持 CSV、PARQUET、ORC 这几种常用文件格式。
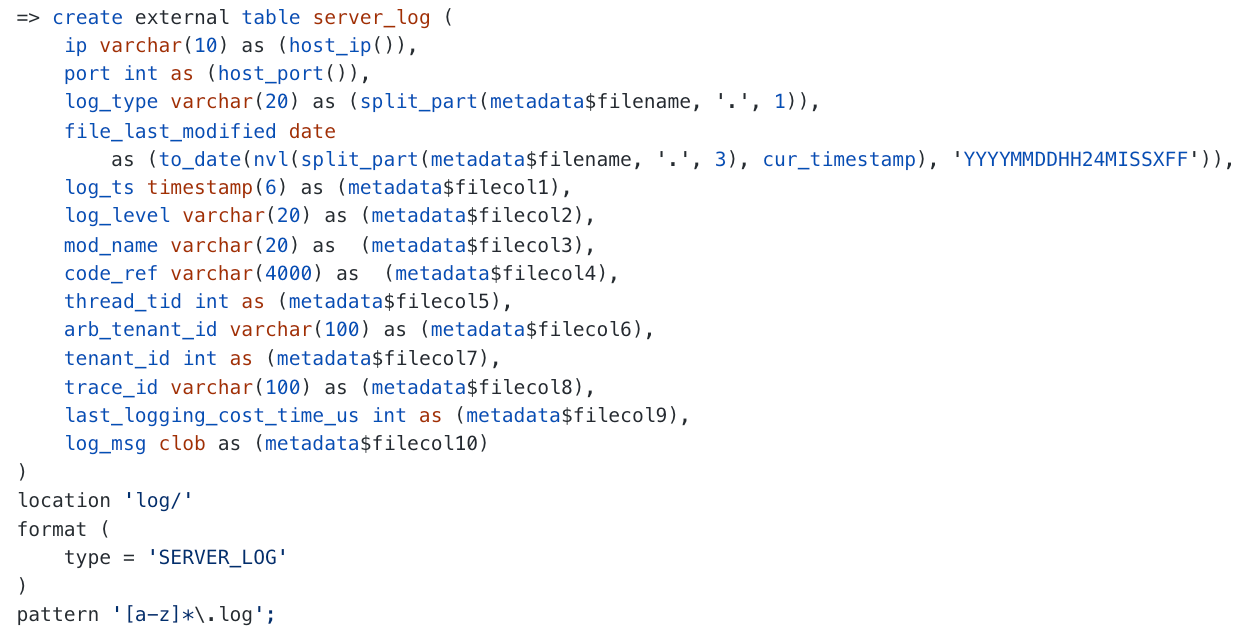
创建好外表之后,就可以像普通表一样进行查询了~
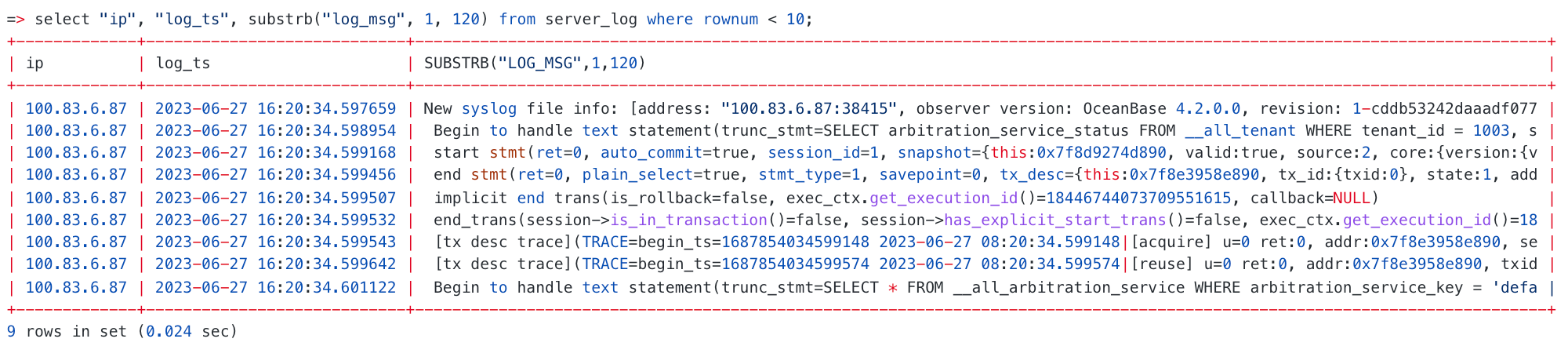
说明:
上面 demo 中的 SERVER_LOG 只是用来作为 demo 示例,并非正式发布的版本中支持的文件格式。
外表可以像普通表一样,与其他表进行链接、聚合、排序等,外表与普通表的差异如下:
- 外表的数据存储在外部文件中,普通表的数据存储在数据库中。
- 外表是只读的,可以在查询语句使用,但不能执行 DML 操作。
- 外表不支持添加约束和创建索引。
通常来说,外表的访问速度会慢于普通表,这个应该也很好理解。
外表存储介质访问速度:
DISK :++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
OSS/COS/S3: ++++
ODPS/DB: +
示例 2
Hive 中的表:
create table score(s_id string, c_id string, s_score int)
partitioned by (month string)
row format CSV;
Hive 分区表存储的目录结构:
> dfs -ls /user/hive/warehouse/myhive1.db/score;
/user/hive/warehouse/myhive1.db/score/month=201803/000000_0
/user/hive/warehouse/myhive1.db/score/month=201804/000000_0
/user/hive/warehouse/myhive1.db/score/month=201804/000001_0
/user/hive/warehouse/myhive1.db/score/month=201805/000000_0
/user/hive/warehouse/myhive1.db/score/month=201806/000000_0
通过外表读取 Hive 的数据。
create external table ex_hive_t1 (
s_id varchar(1000),
c_id varchar(1000),
s_score int,
month varchar(1000)
as (substr(split_part(metadata$fileurl, '/', 6), 7, 6))
)
format (type = 'PARQUET')
location 'hdfs://${namenode}:${port}/user/hive/warehouse/myhive1.db/score'
partition by(month);
边学边练,效果拔群
《通过外表直接访问外部数据源》实验地址:https://www.oceanbase.com/demo/external-table
本实验会为大家提供在线体验的环境,让大家通过 csv 格式的文件,来创建一张外表,简单且直观地体验 OceanBase MySQL 租户下的外表能力。强烈推荐大家来点击上面的链接来亲手实践一把!
外表的用法示例
步骤 1: 准备外部表数据
我们在阿里云的对象存储 OSS 中存放了 TPCH 1G 的数据,其中 lineitem 的表的数据分成了 10 个文件放在 mydata/tpch_1g_data/lineitem 中。
object list is:
71.96MB Standard oss://mydata/tpch_1g_data/lineitem/lineitem.tbl.1
72.63MB Standard oss://mydata/tpch_1g_data/lineitem/lineitem.tbl.10
72.10MB Standard oss://mydata/tpch_1g_data/lineitem/lineitem.tbl.2
72.57MB Standard oss://mydata/tpch_1g_data/lineitem/lineitem.tbl.3
72.51MB Standard oss://mydata/tpch_1g_data/lineitem/lineitem.tbl.4
72.57MB Standard oss://mydata/tpch_1g_data/lineitem/lineitem.tbl.5
72.72MB Standard oss://mydata/tpch_1g_data/lineitem/lineitem.tbl.6
72.48MB Standard oss://mydata/tpch_1g_data/lineitem/lineitem.tbl.7
72.60MB Standard oss://mydata/tpch_1g_data/lineitem/lineitem.tbl.8
72.53MB Standard oss://mydata/tpch_1g_data/lineitem/lineitem.tbl.9
步骤 2: 创建外表
外表的用法和普通表非常相似,比普通表多了 LOCATION 和 FORMAT 属性。其中 LOCATION 用于指定数据文件所在位置,FORMAT 指定数据文件的格式。
CREATE EXTERNAL TABLE lineitem
(
L_ORDERKEY int,
L_PARTKEY int,
L_SUPPKEY int,
L_LINENUMBER int,
L_QUANTITY DECIMAL(15,2),
L_EXTENDEDPRICE DECIMAL(15,2),
L_DISCOUNT DECIMAL(15,2),
L_TAX DECIMAL(15,2),
L_RETURNFLAG CHAR(1),
L_LINESTATUS CHAR(1),
L_SHIPDATE DATE,
L_COMMITDATE DATE,
L_RECEIPTDATE DATE,
L_SHIPINSTRUCT CHAR(25),
L_SHIPMODE CHAR(10),
L_COMMENT VARCHAR(44)
)
LOCATION = 'oss://$ACCESS_ID:$ACCESS_KEY@$HOST/tpch_1g_data/lineitem/'
FORMAT = (
TYPE = 'CSV'
FIELD_DELIMITER = '|'
);
如果文件中的列顺序和表中的列顺序不一致,可以通过通过 metadata$filecolN 伪列进行对应。
步骤 3: 查看外表的文件
外表创建时,会将 LOCATION 下的文件列表保存在一个文件列表中,外表扫描时只会访问这个列表下的外部文件。
通过以下语句可以查看外表的文件列表:
select * from DBA_EXTERNAL_TABLE_FILES where table_name = 'lineitem';
当外部数据文件有变化时,可以执行以下语句更新外表的文件列表:
alter external table lineitem refresh;
如果文件被删除且未更新文件列表,外表查询时会自动忽略这个文件。
步骤 4: 查询外表
外表查询时,通过外表的驱动层直接读取外部文件,并按照文件格式进行解析,转换成 OceanBase 内部的数据类型后返回数据行。
select L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER
from lineitem limit 1;
+------------+-----------+-----------+--------------+
| L_ORDERKEY | L_PARTKEY | L_SUPPKEY | L_LINENUMBER |
+------------+-----------+-----------+--------------+
| 1 | 155190 | 7706 | 1 |
+------------+-----------+-----------+--------------+
1 rows in set
性能测试示例
下面我们对外表进行简单的性能测试,以本地文件场景和 CSS 文件场景为例,测试环境如下:
- CPU Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz
- DATA:TPCH 1G 的文本文件,文件格式 CSV,每个表的数据拆成 10 个文件
- 兼容模式:Oracle(社区版虽然没有 Oracle 模式,但区别不大,领会精神即可)
- OB 版本:4.2(朝花夕拾版)
场景 1:本地文件场景
串行扫描
select count(*) from LINEITEM;
+----------+
| COUNT(*) |
+----------+
| 6001215 |
+----------+
1 row in set (7.987 sec)
并行扫描
select /*+ parallel(10) */ count(*) from LINEITEM;
+----------+
| COUNT(*) |
+----------+
| 6001215 |
+----------+
1 row in set (2.035 sec)
场景 2:OSS 文件
串行扫描
select count(*) from LINEITEM;
+----------+
| COUNT(*) |
+----------+
| 6001215 |
+----------+
1 row in set (1 min 24.247 sec)
并行扫描
select /*+ parallel(10) */ count(*) from LINEITEM;
+----------+
| COUNT(*) |
+----------+
| 6001215 |
+----------+
1 row in set (8.790 sec)
其他复杂 SQL 的场景示例
示例 1
外表可以像普通表一样与其他表进行链接,谓词过滤,聚合,排序等操作。
外表可以通过 parallel hint 开启并行查询。
下面例子中,customer/orders/lineitem 均为外表。
obclient> SELECT * FROM
(SELECT /*+ parallel(10) */
l_orderkey,
o_orderdate,
o_shippriority,
sum(l_extendedprice * (1 - l_discount)) AS revenue
FROM customer,
orders,
lineitem
WHERE c_mktsegment = 'BUILDING'
AND c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND o_orderdate < '1995-03-15'
AND l_shipdate > '1995-03-15'
GROUP BY l_orderkey,
o_orderdate,
o_shippriority
ORDER BY revenue DESC, o_orderdate)
WHERE ROWNUM <= 10;
+------------+---------------------+----------------+-------------+
| L_ORDERKEY | O_ORDERDATE | O_SHIPPRIORITY | REVENUE |
+------------+---------------------+----------------+-------------+
| 2456423 | 1995-03-05 00:00:00 | 0 | 406181.0111 |
| 3459808 | 1995-03-04 00:00:00 | 0 | 405838.6989 |
| 492164 | 1995-02-19 00:00:00 | 0 | 390324.061 |
| 1188320 | 1995-03-09 00:00:00 | 0 | 384537.9359 |
| 2435712 | 1995-02-26 00:00:00 | 0 | 378673.0558 |
| 4878020 | 1995-03-12 00:00:00 | 0 | 378376.7952 |
| 5521732 | 1995-03-13 00:00:00 | 0 | 375153.9215 |
| 2628192 | 1995-02-22 00:00:00 | 0 | 373133.3094 |
| 993600 | 1995-03-05 00:00:00 | 0 | 371407.4595 |
| 2300070 | 1995-03-13 00:00:00 | 0 | 367371.1452 |
+------------+---------------------+----------------+-------------+
10 rows in set
示例 2
外表可以与普通表组合进行查询操作。
下面例子中,temp 是普通表,orders 是外表。
SELECT temp.*
from temp, orders
WHERE temp.c1 = orders.O_ORDERDATE and rownum < 5;
+---------------------+
| C1 |
+---------------------+
| 1995-03-05 00:00:00 |
| 1995-02-22 00:00:00 |
| 1995-02-22 00:00:00 |
| 1995-03-13 00:00:00 |
+---------------------+
4 rows in set
示例 3
外表可以实现将外部数据导入普通表的操作。
下面例子中,lineitem_import 为普通表,lineitem 为外部表,通过 PDML 功能可以将外表 lineitem 数据并行导入普通表 lineitem_import。
INSERT /*+ enable_parallel_dml parallel(10) */
INTO lineitem_import
SELECT * FROM lineitem;
What’s more ?
关于外表,OceanBase 官网文档团队为大家整理了一个《外表使用手册》,内容已经足够全面,分为以下四篇内容:
如果大家对外表这个功能感兴趣的话,就请直接阅读上面的几个官网链接吧,我这里就不再啰嗦了,哈哈。这是 DBA 实战营第一季的最后一篇文章了,大家肯定都允许我投个懒,对吧?(虽然之前好像也偷过不少次懒……)
在这里,特别感谢能从坚持从第一期一路坚持到第十期的各位 OceanBase 社区中老师和朋友!个人水平有限,欢迎大家多多批评指正!
最后的最后
再为大家附上一个外表文件格式的简介(CSV、PARQUET、ORC)。
很多人在大学期间都已经学习过这部分内容,所以已经了解的同学们可以直接跳过。
外表文件格式
格式简介
CSV

Parquet / ORC
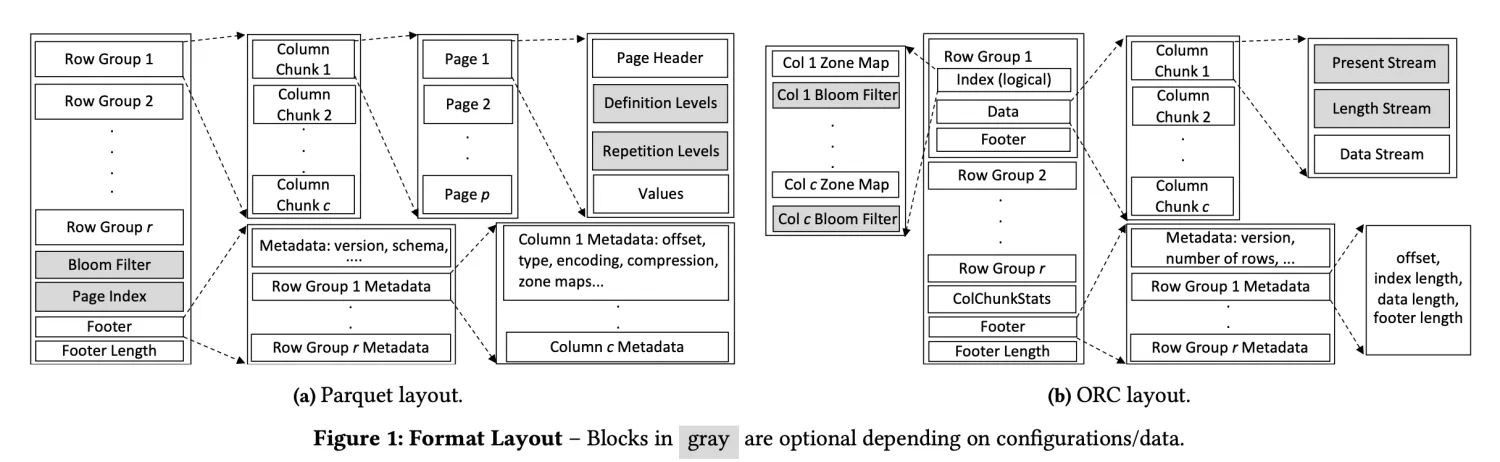
嵌套数据类型的 Schema
Parquet 是一个由 Google Dremel 格式启发而来的列存格式,在大数据领域通常作为存储格式,被 iceberg 等湖、各种查询引擎能够合理的使用。
Parquet schema模型能比较简洁处理嵌套和重复。嵌套关系用“属性组”(groups)表示,重复属性用"重复度"(repeated field)表示。一个属性的"重复度"可以有几种定义:
- required:刚好出现一次
- optional:出现 0 或 1 次
- repeated:出现 0 或多次
Parquet 存储数据的例子
假如有 schema 是:
country_tab {
required string continent,
required group country {
repeated string city,
optional int population
},
required string name
}
country_tab 记录包含 continent、country、name三个属性,其中country是一个属性组,包含 city、population两个属性。city 是一个 repeated 字段,因此可以有多个值,从而表达了数组。
如何存储下面一行数据 ?
country_tab {
"continent": "Europe",
"country": {
"city": [
"Paris",
"Nice",
"Marseilles",
"Cannes"
],
"population": 1000000
}
"name": "France"
}
其中,city 是个数组,数组中元素可以是任意个,假设 population 可能是未知的,可以被设置为 NULL,其他属性都是不能为 NULL 的。
Parquet 认为以上 schema 有 4 列(仅存储叶子结点)
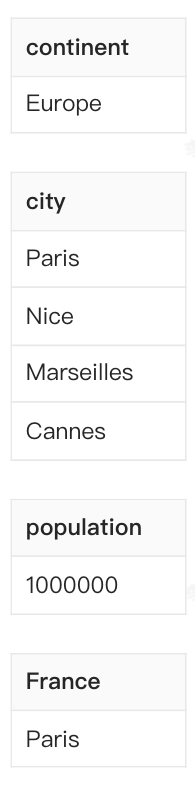
假如有 2 行数据,因为一行中的数据可以 repeat,也可以为 null,如何区分一个 column chunk 中的数据到底是属于哪一行的?
通过数据上定义的 defination level 和 repetitive level。
类似地,Maps, List or Sets 都可以用重复和属性组(groups + repeated field)表达出来。
相比之下,ORC 使用一个单独的 bitmap 来存储节点是否存在,比较容易理解。
-
Struct 只记录 Struct 本身的 PRESENT。
-
List = Present Stream + Length Stream。
-
Map = Map 等价于一种很奇怪的 List 和 List 表现一样,但后面有一组 Key 一组 Value。
-
Union 分成 PRESENT + Tag,后面接不同种类的 Stream。
