

1. 三个问题
上来先放三个社区论坛中常见的和分区问题,当做 OceanBase 中使用分区的小经验分享给大家。
1.1. 问题一
问:分区数如何设置?
答:考虑到分区间可能的数据倾斜以及未来可能的扩容性,通常可以将分区数设为一个 Zone 内所有机器 CPU 总数的两倍。
1.2. 问题二
问:如果没有一个维度适合将数据做 range / list 分区,我应该选择哪个列做 hash / key 分区?
答:满足以下条件的列:
- NDV 远大于分区数。
- 此列数据没有倾斜,或只有少量倾斜。
- 优先选择整形列和时间列,再考虑 varchar / char。
1.3. 问题三
问:如果倾向于查最近的数据,且越新的数查询频率越高。如按天导入业务流水,并对最近交易进行分析。这种情况应该如何设计分区?
答:可考虑先对时间做 List 或 Range 分区,再在一级分区内按照 ID 等字段做 Hash 二级分区。
2. 边学边练,效果拔群
《分区表的使用》实验地址:https://www.oceanbase.com/demo/use-partition-tables
本实验会为大家介绍如何使用 OceanBase 数据库创建分区、查询表分区信息、访问指定分区,以及添加分区等常见和分区相关的操作。强烈推荐大家来点击上面的链接来亲手实践一把!
3. partition(分区)设计规范
后面的内容,学习过《OceanBase 进阶教程》的同学可以直接跳过。
分布式数据库的优势在于对于空间问题和请求访问问题分而治之。针对每个分区的访问,由该分区所在的节点响应即可。 即使该 SQL 并发很高,由于访问的是不同的分区,分别由不同的节点提供服务。每个节点自身也有一定能力满足一定的 QPS,所有节点集中在一起就能提供更大的 QPS。这个时候如果扩容节点数量,该 SQL 总的 QPS 也能获得相应的提升,这是分布式数据库里最好的情形。
分区的目标是将大量数据和访问请求均匀分布在多个节点上,一是想充分利用资源进行并行计算,消除查询热点问题;二是想利用分区裁剪来提升查询效率。 如果每个节点均匀承担数据和请求,那么理论上 10 个节点就应该能承担 10 倍于单节点的数据量和访问量。然而如果分区是不均匀的,一些分区的数据量或者请求量会相对比较高,出现数据偏斜(skew),这个可能导致节点资源利用率和负载也不均衡。偏斜集中的数据我们又称为热点数据。避免热点数据的直接方法就是数据存储时随机分配(没有规则)给节点,缺点是读取的时候不知道去哪个分区找该记录,只有扫描所有分区了,所以这个方法意义不大。实际常用的分区策略都是有一定的规则。
用户必须在业务查询条件明确的情况下,根据真实业务场景进行分区规划,不要在场景不明确的情况下随意进行分区规则。 在规划分区时,建议尽量保证各个分区的数据量相对均衡。
最常用的三种分区方式如下:
- HASH 分区:一般适用于分区列 NDV(不同值的种类)较大,且难以划分出明确范围的情况。优点是容易让没有特定规则的数据也能够在不同的分区内均匀分布,缺点是在范围查询时难以进行分区裁剪。
- RANGE 分区:一般适用于分区键容易划分出明确的范围的情况,例如可以把记录流水信息的大表,根据表示信息时间的列做 RANGE 分区。
- LIST 分区:一般适用于需要显式控制各行数据如何映射到具体的某一个分区时,优点是可以对无序或无关的数据集进行精准分区,缺点是在范围查询时难以进行分区裁剪。
为了更好地支持并行计算和分区裁剪,OceanBase 还支持二级分区。OceanBase 数据库 MySQL 模式目前支持 HASH 、RANGE 、LIST 、KEY 、RANGE COLUMNS 和 LIST COLUMNS 六种分区类型,二级分区为任意两种分区类型的组合。
例如在用户账单领域,数据库往往需要按照 user_id 做 HASH 一级分区,然后再在各个一级分区内部,继续按照账单创建时间做 RANGE 二级分区。
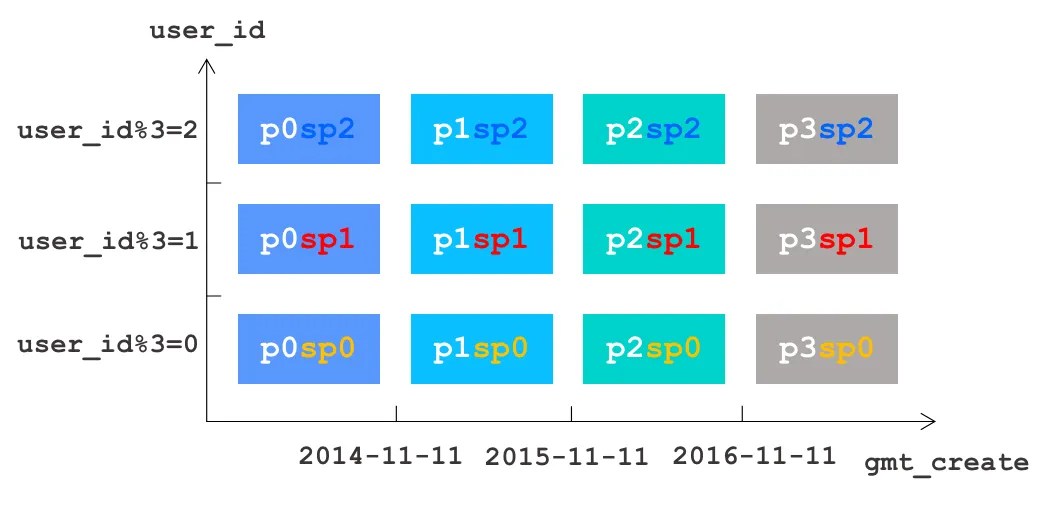
尽管 OceanBase 数据库在组合分区上支持 RANGE + HASH 和 HASH + RANGE 两种组合,但是对于 RANGE 分区的分区操作 add / drop,必须是 RANGE 分区做为一级分区的方式。所以针对例如数据量较大的流水表,为了维护方便(新增和删除分区),建议使用 RANGE + HASH 组合方式。
4. 推荐阅读
- OceanBase 官网文档《创建和管理分区》章节
- 社区博客《如何在 OceanBase 上优雅地使用分区表》
- 社区博客《浅析 OceanBase 中创建分区时常见的几个问题》
- 当分区划分后,数据在各个分区不均衡时,可能会因为数据倾斜导致查询性能不优的问题。推荐大家通过 OceanBase 的 SQL plan monitor 这个工具,来确认查询性能不优是否是由于数据倾斜造成的。工具的使用方法详见:《试用 obdiag 进行信息收集和问题诊断》这篇博客的 “收集 sql_plan_monitor 信息” 部分。