【 使用环境 】生产环境
【 OB or 其他组件 】OB、OMS
【 使用版本 】源端OB4.2.1、 OMS4.2.9社区办、 目标端OB4.3.4.1
【问题描述】
筛选store组件的libobcdc.log日志中的WDIAG日志显示

过滤 NEED_SLOW_DOWN 显示
【 使用环境 】生产环境
【 OB or 其他组件 】OB、OMS
【 使用版本 】源端OB4.2.1、 OMS4.2.9社区办、 目标端OB4.3.4.1
【问题描述】
筛选store组件的libobcdc.log日志中的WDIAG日志显示
过滤 NEED_SLOW_DOWN 显示
详细介绍下, 源端 数据库类型, 配置链路的jvm 线程 内存 batch大小等情况吧
您的 集群节点现在都正常吧
源端是ob4.2.1-10BP集群。 目的端是ob4.3.4.1集群
OMS机器32C、总内存128G.
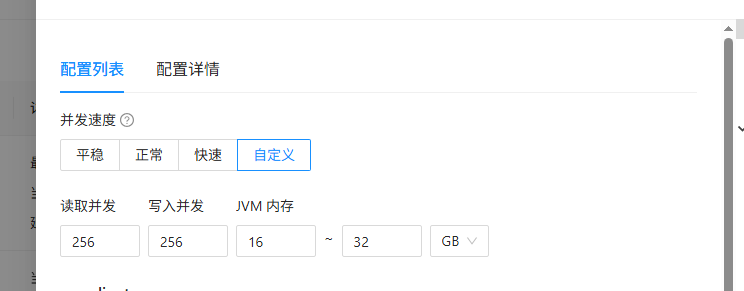
启动时,没有特别指定store组件的JVM。
仅指定了Incr-Sync组件JVM。 如下图
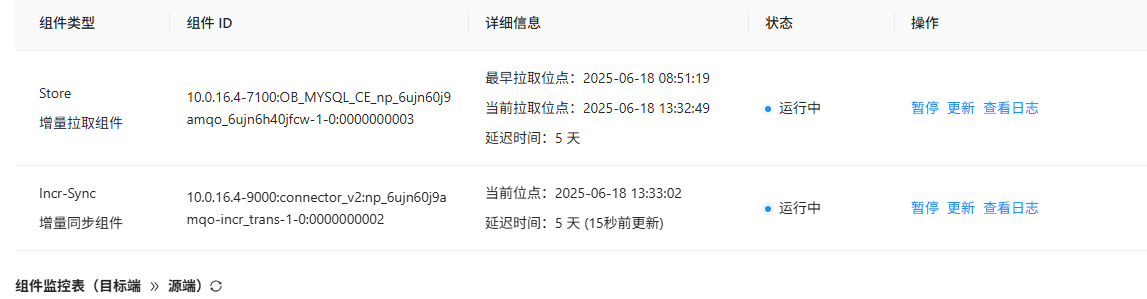
所有集群节点都正常。目前看情况是Store组件拉取日志的速率上不去,没有用满带宽
store组件配置详情:
“root”:{
55 items
“drc_frame.dbversion”:
string"4.2.1.10"
“drc_frame.log4cpp_category”:
string"log"
“drc_frame.log4cpp_cfg”:
string"./conf/logger.conf"
“drc_frame.modules_name”:
string"ob2store"
“drc_frame.modules_path”:
string"./lib64/reader/ob-ce-4.x-reader"
“drc_frame.monitor_port”:
string"0"
“global.config.version”:
string"3"
“global.running.mode”:
string"strict"
“liboblog.cluster_appname”:
string"oa"
“liboblog.cluster_db_name”:
string"oceanbase"
“liboblog.cluster_password”:
string"******"
“liboblog.enable_output_hidden_primary_key”:
string"1"
“liboblog.enable_output_invisible_column”:
string"1"
“liboblog.enable_output_trans_order_by_sql_operation”:
string"1"
“liboblog.first_start_timestamp”:
string"1750644093000"
“liboblog.history_schema_version_count”:
string"16"
“liboblog.instance_index”:
string"0"
“liboblog.instance_num”:
string"1"
“liboblog.progress_limit_sec_for_ddl”:
string"3600"
“liboblog.region”:
string"默认地域"
“liboblog.sort_trans_participants”:
string"1"
“liboblog.target_ob_region”:
string"default"
“liboblog.tb_black_list”:
“liboblog.timezone”:
string"+08:00"
“ob2store.collect_ddl”:
string"true"
“ob2store.dbtype”:
string"oceanbase"
“ob2store.error.level”:
string"WARN"
“ob2store.master.binlog”:
string"1750211196"
“ob2store.master.host”:
string"1.1.1.1"
“ob2store.master.offset”:
string"451758"
“ob2store.master.port”:
string"1"
“ob2store.master.timestamp”:
string"1750211196"
“ob2store.parallelism”:
string"1024"
“ob2store.pipeline”:
string"reset,read,parse,filter|consume"
“ob2store.serialize_pool_size”:
string"16"
“ob2store.subId”:
string"0000000003"
“ob2store.subTopic”:
string"OB_MYSQL_CE_np_6ujn60j9amqo_6ujn6h40jfcw-1-0"
“ob2store.topic”:
string"OB_MYSQL_CE_np_6ujn60j9amqo_6ujn6h40jfcw"
“store.clearer.outdated”:
string"864000"
“store.clearer.period”:
string"3600"
“store.client.wait”:
string"43200"
“store.connection.numLimit”:
string"1000"
“store.drcnet.threadPoolSize”:
string"24"
“store.drcnetListenPort”:
string"17001"
“store.listeningPort”:
string"17000"
“store.queue.forceIndexIter”:
string"1"
“store.queue.threadPoolSize”:
string"36"
“store.reader”:
string"on"
“store.repStatus”:
string"master"
“store.useThreadPool”:
string"true"
“store.writer.threshold”:
string"1"
“store.writer.type”:
string"message"
}
我把整个库的表均分成2个迁移任务同时进行增量。 能否提高速度
store新增参数
liboblog.working_mode=memory
该模式下,会避免logproxy落盘进而避免磁盘I0瓶颈
liboblog.working_mode:memory
ob2store.serialize_pool_size:16
liboblog.queue_backlog_lowest_tolerance=1000
liboblog.memory_limit=24G

这两个时间点 是不是 有啥问题呢 ?? 这昨天是 23号了吧
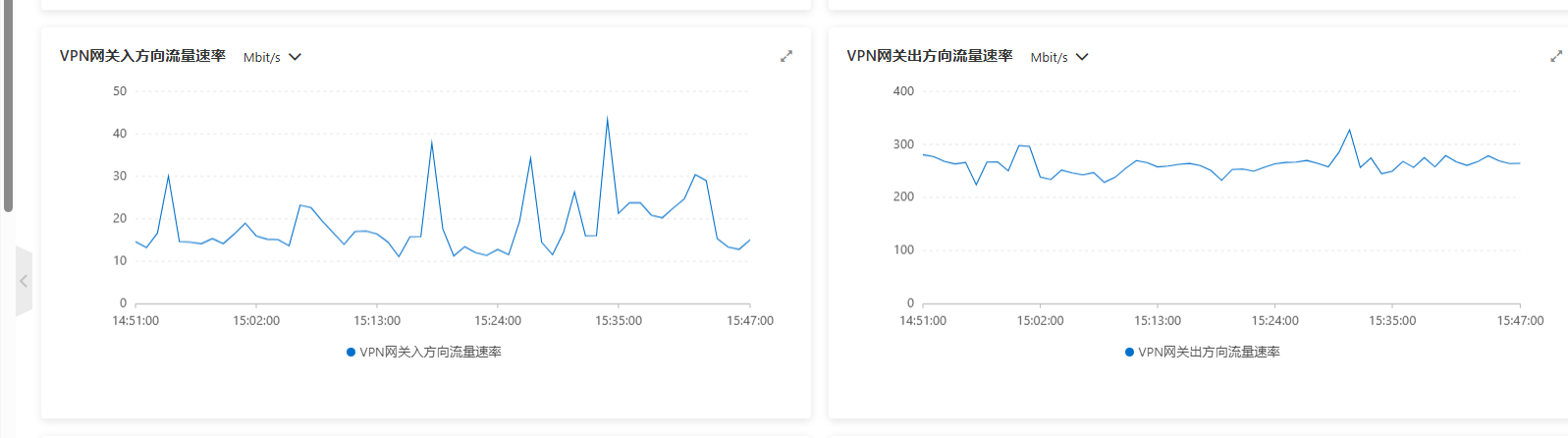
您的 OMS链路的store组件所在的 服务器没有什么 压力吧 ?? IO CPU 和 网络带宽上。截图发下
VPN 上有限制没
机器性能都没有压力。
VPN的限制都去除了。
增量只够消化新产生的日志。不够追之前的延迟。
就是延迟了5天了。。
准备重新全量+增量了。
延迟追不上。
之前全量+增量配置的外网ip。
然后发现全量是走的外网。 日志拉取是走的VPN内网。
当时VPN内网只有200M。拉取日志的速率赶不上源端生成的速度
感觉像是配置类性能问题。
可以根据metrics.log分析一下 看看问题在哪里
slice分片->source读取源端->dispatcher数据分发->sink写入目标
另外一个悬赏贴已经解决问题。
参考