

以下内容均部署在 OceanBase Desktop服务端所在的wsl上,无需在搭建更多的虚拟机,也算是对OceanBase Desktop充分利用了。
如果不知道wsl或者不知道如何登录wsl,可以参考我的博客 OceanBase Desktop的非正确打开方式
1. 什么是Ollama
Ollama 是一个**开源的轻量级大语言模型(LLM)部署工具,**它的核心价值在于降低了大模型本地部署的技术门槛,让开发者无需复杂的环境配置,就能在普通电脑、服务器甚至边缘设备上运行各类开源大模型。
Ollama的优点:
- 部署简单,不依赖复杂的AI框架,一条命令即可安装。
- 支持多种模型,如DeepSeek-R1, Qwen 3, Llama 3.3, Qwen 2.5‑VL, Gemma 3。
- 资源使用少,可以使用量化后的模型。
1.1 如何安装Ollama
登录OceanBase Desktop所在服务的wsl
curl -fsSL https://ollama.com/install.sh | sh
安装完成后,会自动启动ollama服务,执行systemctl status ollama 出现以下信息表示安装并启动成功。
# systemctl status ollama
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; preset: enabled)
Active: active (running) since Tue 2025-06-17 21:28:39 CST; 19min ago
Main PID: 172 (ollama)
Tasks: 12 (limit: 37058)
Memory: 66.1M (peak: 146.1M)
CPU: 416ms
CGroup: /system.slice/ollama.service
└─172 /usr/local/bin/ollama serve
1.2 拉取并运行模型
官网模型仓库有众多的模型可以选择,可根据自己的需求和机器性能选择不同的模型,这里我选择的是qwen3:14b。官网模型仓库点这里![]() 模型仓库
模型仓库
-- 拉取模型
ollama pull qwen3:14b
--运行模型
ollama run qwen3:14b
2. OceanBase Desktop桌面版配置
启动服务后,点击“启动”启动服务端。
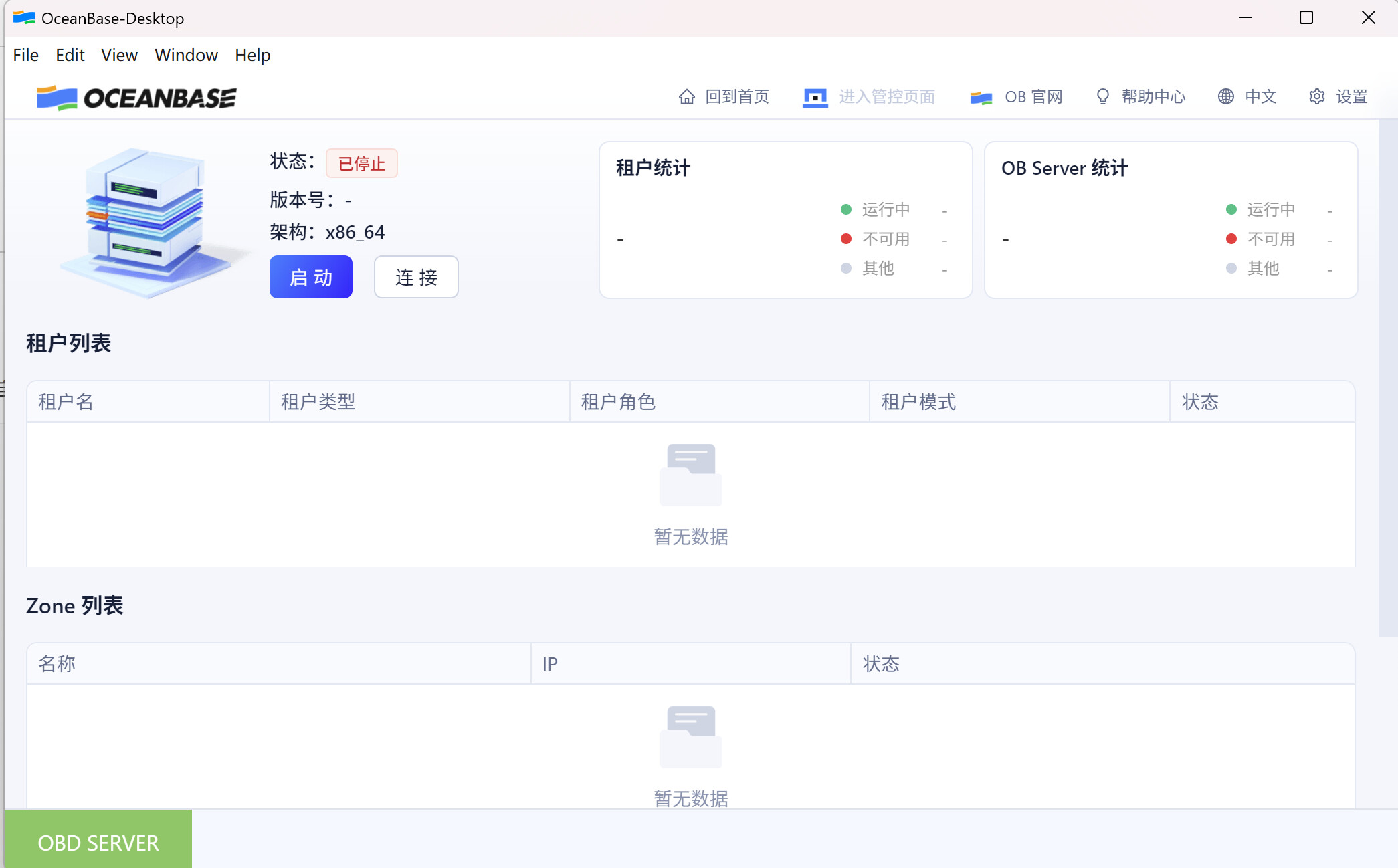
点击“进入管控页面”->“租户管理”。出现租户列表,点击业务租户进入租户。
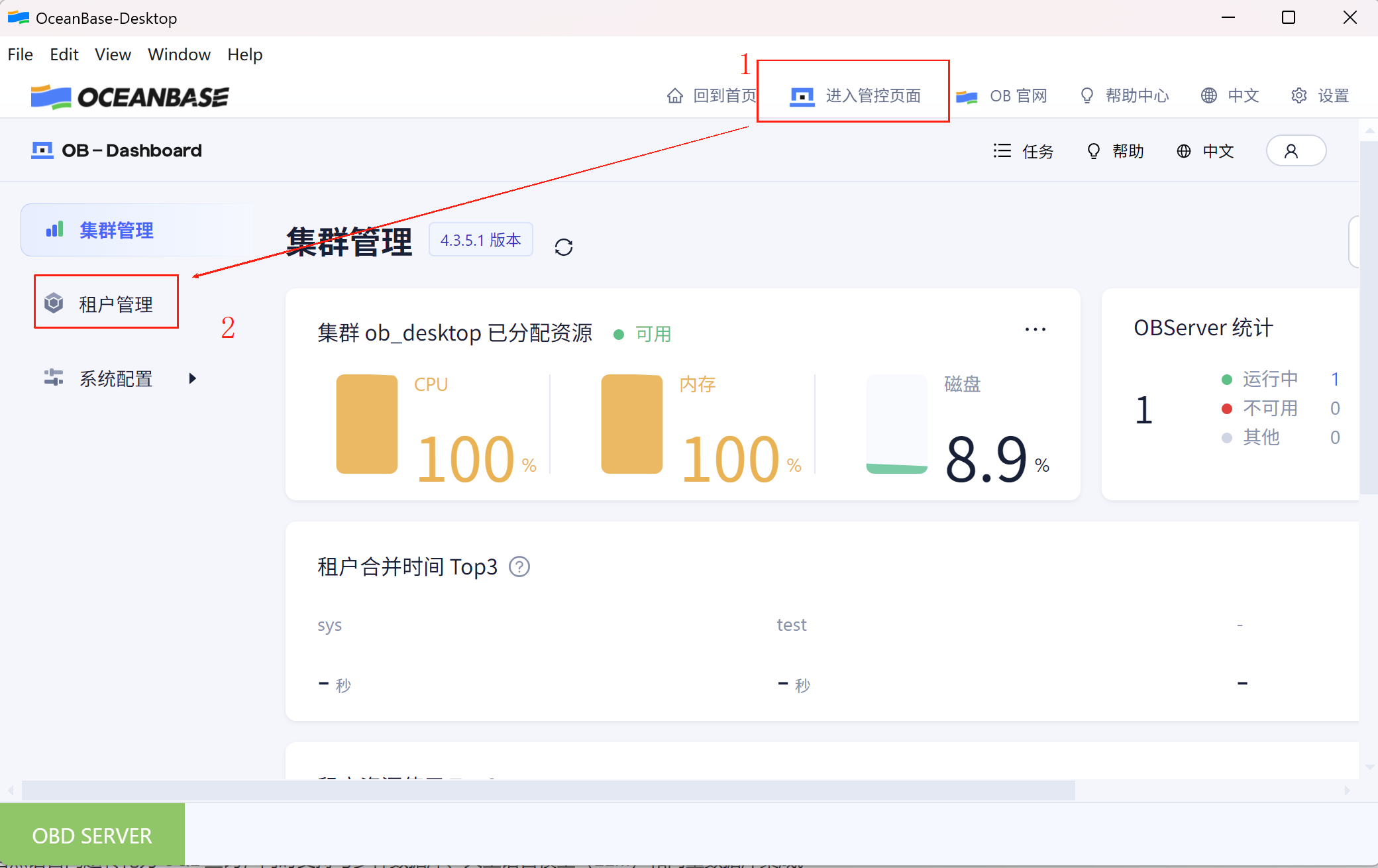
进入租户后,点击“用户管理”,创建业务用户和分配权限。
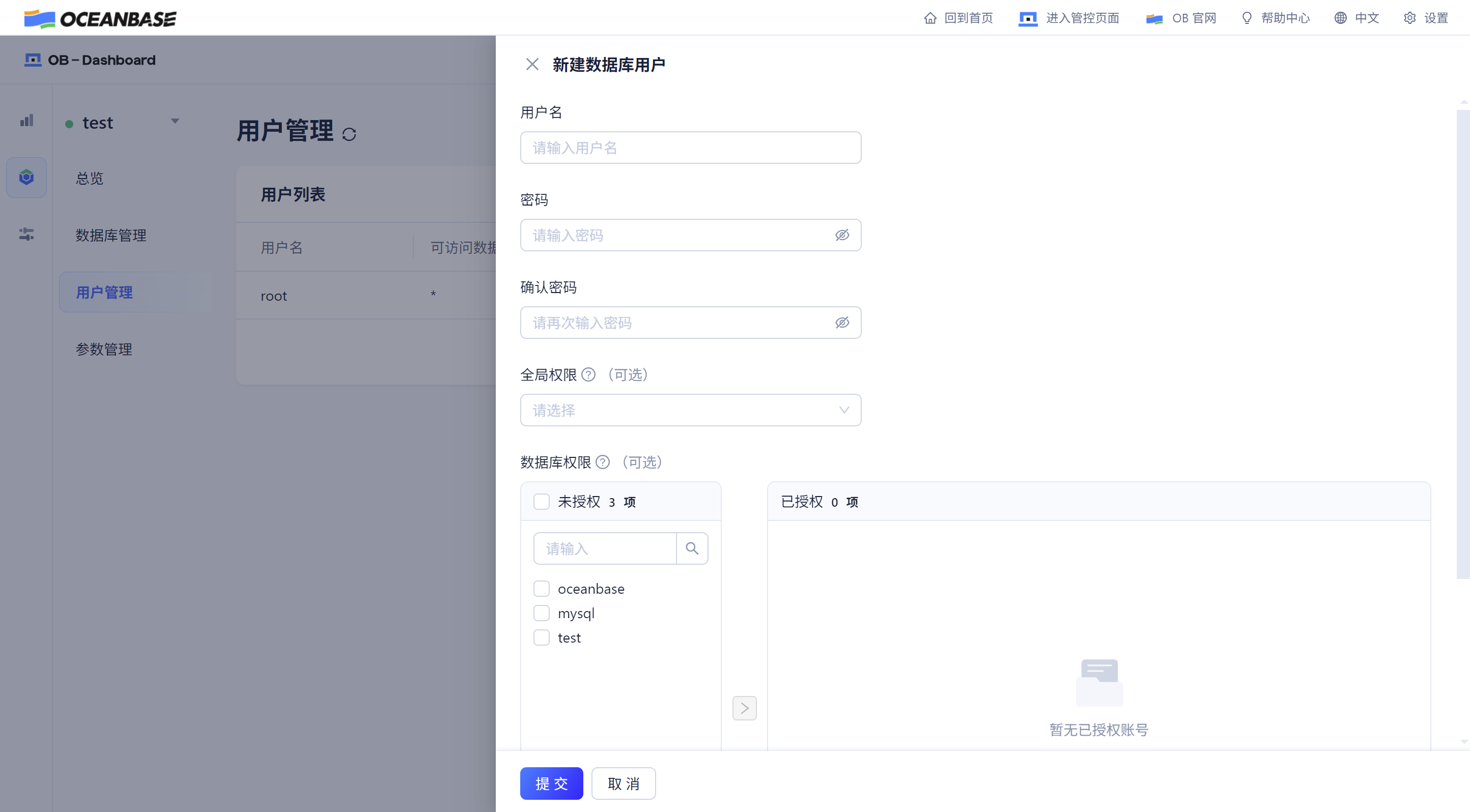
创建完成后使用业务用户登录数据库,创建数据库、表和插入数据。
obclient -utest@t1 -ppasswd
CREATE DATABASE test;
USE test;
-- 用户表
CREATE TABLE t_user (
uin BIGINT UNSIGNED PRIMARY KEY COMMENT '用户唯一标识',
name VARCHAR(50) NOT NULL COMMENT '用户姓名',
email VARCHAR(100) UNIQUE COMMENT '电子邮箱',
phone VARCHAR(20) UNIQUE COMMENT '手机号码',
register_time DATETIME DEFAULT CURRENT_TIMESTAMP() COMMENT '注册时间',
is_active TINYINT(1) DEFAULT 1 COMMENT '用户状态(1=活跃,0=封禁)'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='系统用户信息表';
-- 商品表
CREATE TABLE t_product (
product_id BIGINT UNSIGNED PRIMARY KEY AUTO_INCREMENT COMMENT '商品ID',
product_name VARCHAR(100) NOT NULL COMMENT '商品名称',
price DECIMAL(10,2) NOT NULL COMMENT '商品单价(元)',
stock INT NOT NULL DEFAULT 0 COMMENT '库存数量',
category VARCHAR(50) COMMENT '商品分类',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP() COMMENT '创建时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品信息表';
-- 订单表
CREATE TABLE t_order (
order_id BIGINT UNSIGNED PRIMARY KEY AUTO_INCREMENT COMMENT '订单ID',
uin BIGINT UNSIGNED NOT NULL COMMENT '下单用户ID',
product_id BIGINT UNSIGNED NOT NULL COMMENT '商品ID',
amount DECIMAL(10,2) NOT NULL COMMENT '订单金额(元)',
quantity INT NOT NULL DEFAULT 1 COMMENT '购买数量',
order_time DATETIME NOT NULL COMMENT '下单时间',
status TINYINT(1) NOT NULL DEFAULT 1 COMMENT '订单状态(1=待支付,2=已支付,3=已完成,4=已取消)',
FOREIGN KEY (uin) REFERENCES t_user(uin),
FOREIGN KEY (product_id) REFERENCES t_product(product_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户订单信息表';
-- 插入数据
INSERT INTO t_user (uin, name, email, phone, register_time, is_active) VALUES
(10001, '张三', 'zhangsan@example.com', '13800138001', '2023-01-01 08:00:00', 1),
(10002, '李四', 'lisi2@example.com', '13900139001', '2023-01-02 09:30:00', 1),
(10003, '王五', 'wangwu3@example.com', '13700137001', '2023-01-03 11:15:00', 1),
(10004, '赵六', 'zhaoliu4@example.com', '13600136001', '2023-01-04 13:45:00', 1),
(10005, '钱七', 'qianqi5@example.com', '13500135001', '2023-01-05 15:30:00', 1),
.....
(10050, '郑五十二', 'zhengshi50@example.com', '13000130050', '2023-02-19 21:00:00', 1);
INSERT INTO t_product (product_name, price, stock, category, create_time) VALUES
('iPhone 14', 7999.00, 100, '手机', '2023-01-01 10:00:00'),
('MacBook Air', 9499.00, 50, '笔记本电脑', '2023-01-02 11:30:00'),
('iPad Pro', 6799.00, 80, '平板', '2023-01-03 14:15:00'),
('AirPods Pro', 1799.00, 120, '耳机', '2023-01-04 16:45:00'),
.....
('小米 13 Pro', 5999.00, 75, '手机', '2023-02-19 18:30:00');
INSERT INTO t_order (uin, product_id, amount, quantity, order_time, status) VALUES
(10001, 1, 7999.00, 1, '2023-01-05 09:20:00', 2),
(10002, 2, 9499.00, 1, '2023-01-06 14:30:00', 3),
(10001, 3, 6799.00, 2, '2023-01-07 16:10:00', 2),
.....
(10050, 1, 7999.00, 1, '2023-03-16 18:20:00', 1);
3. 什么是Vanna
Vanna 是一个开源的、基于 Python 的检索增强生成(RAG)框架,主要用于将自然语言问题转化为 SQL 查询,同时支持与多种数据库、大型语言模型(LLM)和向量数据库集成。
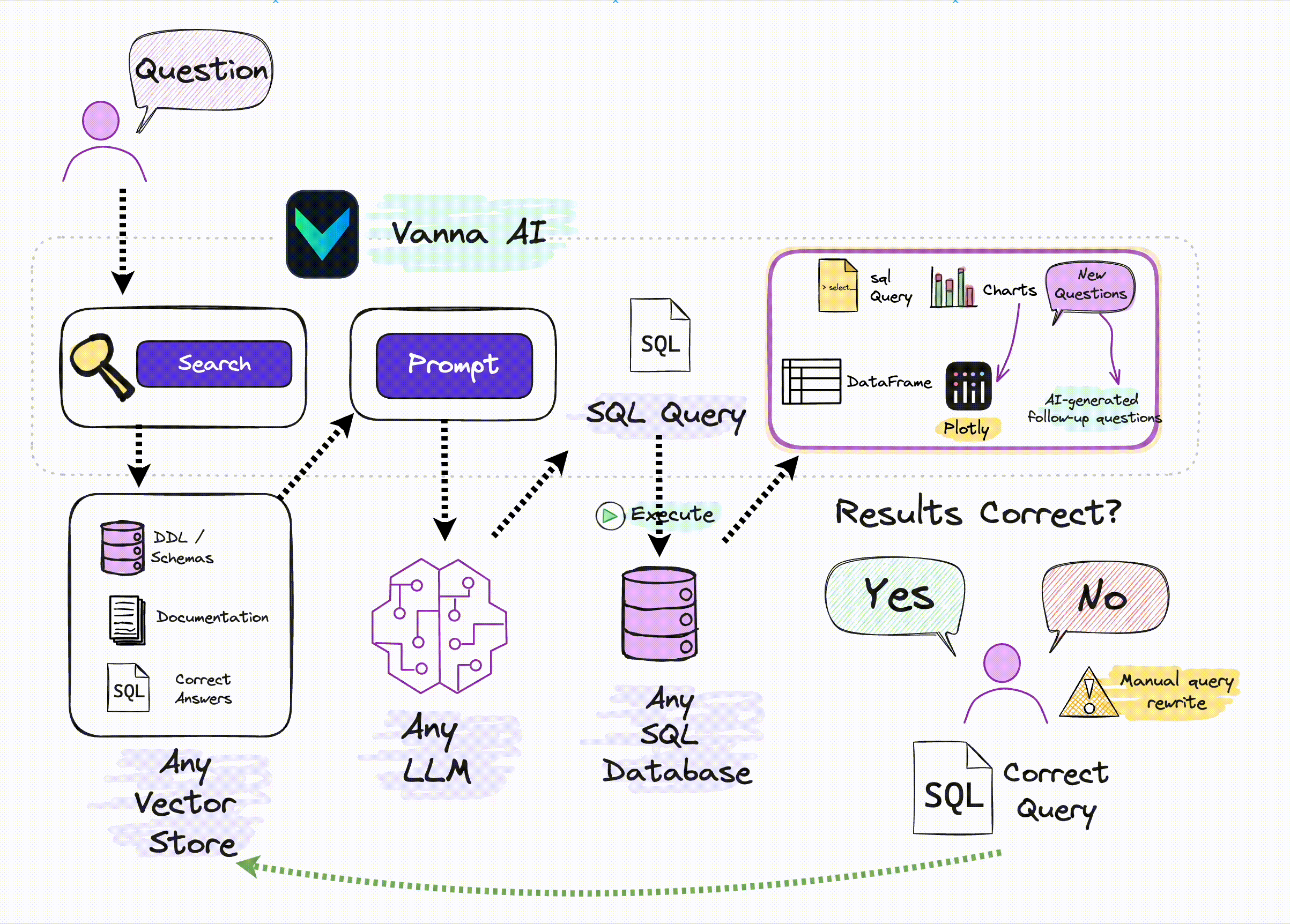
Vanna的工作原理:
1. 用户发起自然语言提问(Question)
流程起点是用户输入自然语言问题(比如 “上个月订单金额超 10 万的客户有哪些?” ),这是触发 Vanna 工作的原始需求,无需用户懂 SQL 语法,降低数据查询门槛。
2. Vanna 的 “Search” 模块:检索上下文信息
用户提问后,Vanna 先通过 Search 模块,从「向量数据库(Any Vector Store)」里检索三类核心信息:
- DDL/Schemas:数据库表结构(字段名、类型、表关系等 ),是生成 SQL 的 “骨架”;
- Documentation:数据库文档、业务说明(比如字段别名、指标定义 ),补充语义理解;
-
Correct Answers(历史 SQL - 问答对):过去已验证的 “问题 + 正确 SQL” 案例,直接复用优质逻辑。
这一步相当于给 LLM 准备 “参考资料”,让生成的 SQL 更贴合实际业务库结构。
3. Vanna 的 “Prompt” 模块:调用 LLM 生成 SQL
带着 Search 模块检索到的上下文,Vanna 进入 Prompt 模块,将「用户问题 + 检索信息」一起投喂给 大语言模型(Any LLM)。LLM 基于这些信息,理解自然语言意图,转化为对应的 SQL 查询语句(比如 SELECT customer_name FROM orders WHERE order_amount > 100000 AND order_month = ‘last_month’; )。
4. 执行 SQL 查询(Execute)
生成的 SQL 会发送到 任意 SQL 数据库(Any SQL Database)(比如 OceanBase、PostgreSQL 等 )执行,数据库返回查询结果(如符合条件的客户名单 )。
5. 结果处理与反馈
查询结果会进一步加工:
- 可视化输出:结合 Plotly 等工具生成图表(Charts ),让数据更直观;
- 拓展交互:基于结果生成后续问题(New Questions ),引导深度分析(比如 “这些客户的复购率如何?” );
- 结果校验:用户判断 “Results Correct?” :
流程核心特点总结
- 解耦灵活:支持任意 LLM(本地 / 云端 )、向量数据库、SQL 数据库,适配私有化部署(如 Ollama + OceanBase Desktop 场景 );
- 自迭代优化:通过用户反馈的 “Correct Query” 持续训练,越用越贴合业务;
- 非技术友好:用自然语言贯穿全流程,让不懂 SQL 的业务人员也能自主分析数据。
简单说,Vanna 就是靠 “检索上下文 + 调用 LLM 生成 SQL + 结果反馈优化” 的闭环,实现 “自然语言提问 → 精准 SQL 查询 → 数据价值挖掘” 的自动化链路,特别适合想让业务人员自主用数据、又要保障查询准确性的场景 。
3.1 部署Vanna
安装依赖环境
pip install vanna
pip install httpx
pip install ollama
pip install 'vanna[chromadb,ollama,mysql]'
3.2 训练数据
vim train.py
from vanna.ollama import Ollama
from vanna.chromadb import ChromaDB_VectorStore
class MyVanna(ChromaDB_VectorStore, Ollama):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
Ollama.__init__(self, config=config)
vn = MyVanna(config={'model': 'qwen3:14b'})
vn.train(ddl="""
CREATE TABLE t_user (
uin BIGINT UNSIGNED PRIMARY KEY COMMENT '用户唯一标识',
name VARCHAR(50) NOT NULL COMMENT '用户姓名',
email VARCHAR(100) UNIQUE COMMENT '电子邮箱',
phone VARCHAR(20) UNIQUE COMMENT '手机号码',
register_time DATETIME DEFAULT CURRENT_TIMESTAMP() COMMENT '注册时间',
is_active TINYINT(1) DEFAULT 1 COMMENT '用户状态(1=活跃,0=封禁)'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='系统用户信息表';
CREATE TABLE t_product (
product_id BIGINT UNSIGNED PRIMARY KEY AUTO_INCREMENT COMMENT '商品ID',
product_name VARCHAR(100) NOT NULL COMMENT '商品名称',
price DECIMAL(10,2) NOT NULL COMMENT '商品单价(元)',
stock INT NOT NULL DEFAULT 0 COMMENT '库存数量',
category VARCHAR(50) COMMENT '商品分类',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP() COMMENT '创建时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品信息表';
CREATE TABLE t_order (
order_id BIGINT UNSIGNED PRIMARY KEY AUTO_INCREMENT COMMENT '订单ID',
uin BIGINT UNSIGNED NOT NULL COMMENT '下单用户ID',
product_id BIGINT UNSIGNED NOT NULL COMMENT '商品ID',
amount DECIMAL(10,2) NOT NULL COMMENT '订单金额(元)',
quantity INT NOT NULL DEFAULT 1 COMMENT '购买数量',
order_time DATETIME NOT NULL COMMENT '下单时间',
status TINYINT(1) NOT NULL DEFAULT 1 COMMENT '订单状态(1=待支付,2=已支付,3=已完成,4=已取消)'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户订单信息表';
""")
3.3 执行训练
python train.py
训练只需要进行一次,不需要每次启动服务都执行。
3.4 设置及启动
-- 设置相关信息
vim run.py
from vanna.ollama import Ollama
from vanna.chromadb import ChromaDB_VectorStore
class MyVanna(ChromaDB_VectorStore, Ollama):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
Ollama.__init__(self, config=config)
vn = MyVanna(config={'model': 'qwen3:14b'})
vn.connect_to_mysql(host='localhost', dbname='test', user='test@t1', password='passwd', port=2881)
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()
-- 启动
# python run.py
-- 出现以下信息表示启动成功
Your app is running at:
http://localhost:8084
* Serving Flask app 'vanna.flask'
* Debug mode: on
4. 使用Web UI
浏览器中访问 http://localhost:8084 ,在new question中可以输入问题。
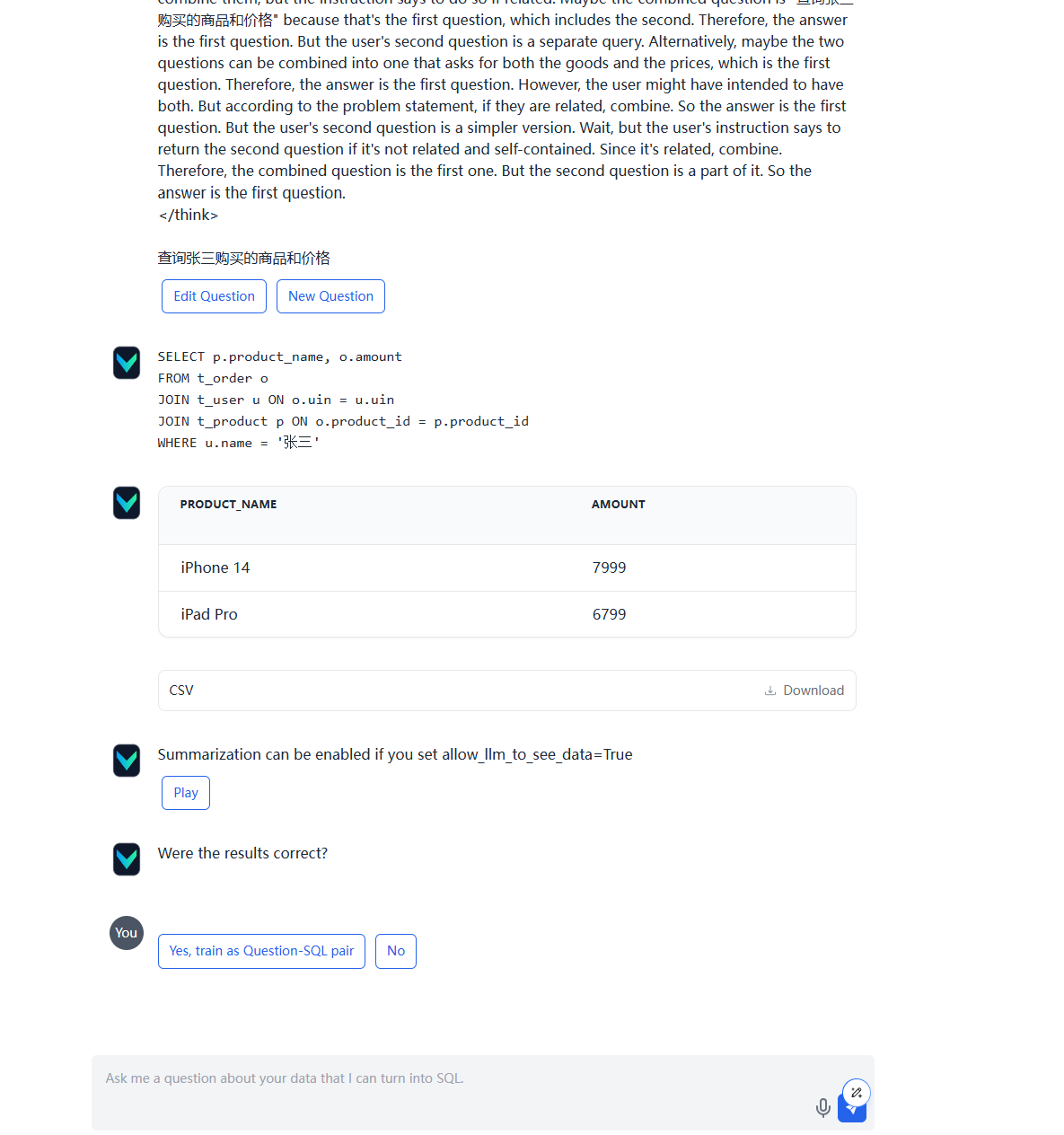
输入“查询张三购买的商品和价格”后,vanna输出了查询的SQL语句,结果,还可以保存为CSV格式。
总结:
通过本次 Ollama、Vanna 与 OceanBase Desktop 的本地 NLP-SQL 部署实战,我们成功搭建了从自然语言交互到数据库操作的闭环生态。Ollama 的轻量化模型部署赋予了 AI 灵活的本地响应能力,Vanna 则作为自然语言与 SQL 间的 “翻译官”,将用户指令精准转化为可执行语句,而 OceanBase Desktop 提供的高效数据管理与存储支持,进一步保障了查询与数据导出(如 CSV 格式输出)的流畅性。三者协同不仅降低了 SQL 使用门槛,还为数据探索、业务分析提供了本地化解决方案。无论是技术爱好者的能力拓展,还是企业低成本的数据处理需求,该组合都展现出强大的潜力。未来,随着模型优化与功能迭代,这种本地化部署模式有望在更多场景中释放价值,感兴趣的读者不妨基于本文实践,探索更丰富的应用场景!