【 使用环境 】生产环境
【 OB or 其他组件 】OCEANBASE、OMS
【 使用版本 】OB4.3.4.1、OMS4.2.9
【问题描述】
如图,12点之前迁移速率约为125000KB/s。 在之后突然暴跌到40000KB/s

如何排查问题
@论坛小助手
【 使用环境 】生产环境
【 OB or 其他组件 】OCEANBASE、OMS
【 使用版本 】OB4.3.4.1、OMS4.2.9
【问题描述】
如图,12点之前迁移速率约为125000KB/s。 在之后突然暴跌到40000KB/s
如何排查问题
@论坛小助手
根据您提供的信息,OMS 增量迁移速度在 12 点前后发生了显著变化。以下是一些可能的排查步骤和建议,基于 OMS 社区版的功能和使用限制:
enable_rebalance 参数以避免性能问题。可以通过以下命令检查并修改该参数:SHOW PARAMETERS LIKE 'enable_rebalance';
ALTER SYSTEM SET enable_rebalance = false;
memory_limit 和 cpu_count,确保它们的配置适合当前的工作负载。根据文档库中的信息,您可以按照上述步骤逐步排查 OMS 增量迁移速度变慢的原因。重点在于检查日志、监控资源使用情况、调整 OceanBase 参数配置以及确保迁移任务的正确配置。如果问题仍然存在,建议联系 OceanBase 的技术支持团队获取进一步帮助。
详情请参考:
根据文档库中的信息,可以明确回答:目的端未开启日志归档不会直接影响增量同步速率,但可能间接影响整体迁移任务的稳定性与数据一致性。
以下是详细分析和依据:
根据文档片段 5 的描述:
因此,日志归档的主要目的是为了长期保存日志以供恢复或审计使用,而不是直接服务于增量同步任务。
增量同步依赖于主库(源端)的日志流,通过解析这些日志来捕获数据变化并将其应用到目标端。具体来说:
因此,目的端未开启日志归档不会直接影响增量同步速率。
尽管目的端未开启日志归档不会直接影响增量同步速率,但可能存在以下间接影响:
为了确保增量同步任务的稳定性和数据一致性,建议如下:
archive_lag_target 参数(如文档片段 3 所述),以减少日志延迟。GV$OB_LOG_ARCHIVE_STATUS 等视图,监控日志归档和同步的状态,及时发现潜在问题。根据文档库中的信息,目的端未开启日志归档不会直接影响增量同步速率,但可能间接影响任务的稳定性和数据一致性。如果您的场景对数据恢复或审计有需求,建议开启目的端的日志归档功能。
详情请参考:
可以把metrics.log日志发一下 按照官网的可以分析一下 看看性能在哪里 是源端还是目标端
https://www.oceanbase.com/docs/community-oms-cn-1000000002947453
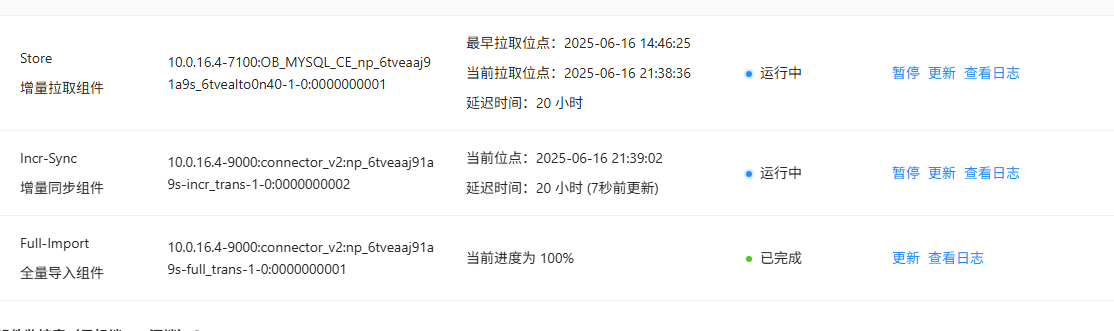
根据您提供的信息,目前遇到的问题是由于 NTP 攻击导致网络流量异常,并且 OMS 的 Store 组件拉取位点停滞在昨晚 9 点。以下是针对该问题的排查和解决建议:
iftop 或 nload 工具监控网络流量,确认是否有异常流量占用带宽。根据文档片段 6 和 8 的描述,Store 组件负责增量数据的拉取和解析。如果拉取位点停滞,可能是以下原因导致:
排查步骤:
libobcdc.log 或 connector/connector.log),确认是否有错误信息。根据文档片段 10 的描述,可以通过以下 SQL 查询各 OBServer 节点的 SQL 流量分布情况,定位潜在的性能瓶颈:
SELECT/*+ PARALLEL(15)*/t2.zone, t1.svr_ip, COUNT(*) AS RPC_COUNT,
AVG(t1.elapsed_time), AVG(t1.queue_time)
FROM oceanbase.GV$OB_SQL_AUDIT t1, __all_server t2
WHERE t1.svr_ip = t2.svr_ip
AND tenant_id = 1001
AND SQL_ID = 'BF7AA13A28DF50BA5C33FF19F1DBD8A9'
AND IS_EXECUTOR_RPC = 0
AND request_time > (time_to_usec(now()) - 1000000)
AND request_time < time_to_usec(now())
GROUP BY t1.svr_ip;
RPC_COUNT 或 elapsed_time 明显高于其他节点,可能是该节点存在性能瓶颈。如果 Store 组件拉取位点停滞时间较长,可以尝试以下方法恢复增量同步:
archive_lag_target 参数,避免日志丢失。根据文档库中的信息,当前问题的主要原因是 NTP 攻击导致网络流量异常,进而影响了 Store 组件的增量同步性能。建议按照上述步骤逐步排查并解决问题,同时采取预防措施避免类似问题再次发生。如果问题仍未解决,建议联系 OceanBase 技术支持团队获取进一步帮助。
具体信息可参考以下文档:
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
ntp服务配置加上以下内容,仅允许内网ip访问,忽略其他ip访问。同时nomodify(禁止修改) notrap(禁止放大):
restrict default ignore
restrict 172.168.0.0 mask 255.255.0.0 nomodify notrap
restrict 10.0.0.0 mask 255.0.0.0 nomodify notrap
restrict 127.0.0.1
restrict ::1
目前流程正常么?是否解决了
您是怎么发现是攻击的。分享下! 非常感谢!
之前部署集群,创建ntp服务的时候。把原始自带的配置清空了。
没了以下配置项
restrict default kod nomodify notrap nopeer noquery
restrict -6 default kod nomodify notrap nopeer noquery
导致源端proxy开放外网的时候。有很多陌生ip来试探。
昨天排查的时候,发现源端和目的端的出网流量和入网流量差异太大,应该是有问题的
就去分析源端入网ip和出网ip。发现存在国外的陌生ip出网流量特别高。
就意识到是被攻击了。
当时还很慌,怕数据流失。赶紧关了外网。
最后排查端口,这个陌生ip使用的ntp服务的端口入网。
目前临时把VPN流量升上去了,使用了VPN网络进行的连接。没有继续使用外网。
之前是因为阿里云VPN流量最高200Mb。想升上去还需要人工申请,觉得麻烦就搞了个外网。还特意仅对指定ip开放入网白名单,以为这样就安全了。
建议在部署教程里,加上ntp服务配置安全性强调。
好示例,学习了!!充实了数据安全的考虑面
你说的是oms部署的时候么?
在oceanbase部署时。 前置准备的ntp部署文档中
部署ntp时。
配置直接这样改:
#禁止所有ntp访问
restrict default ignore
#只允许自己配置的上级ntp服务访问
restrict xxx.xxx.xxx.xxx nomodify notrap nopeer noquery
#配置自己的上级ntp服务
server xxx.xxx.xxx.xxx iburst
好的 我们也反馈一下 感谢你的反馈