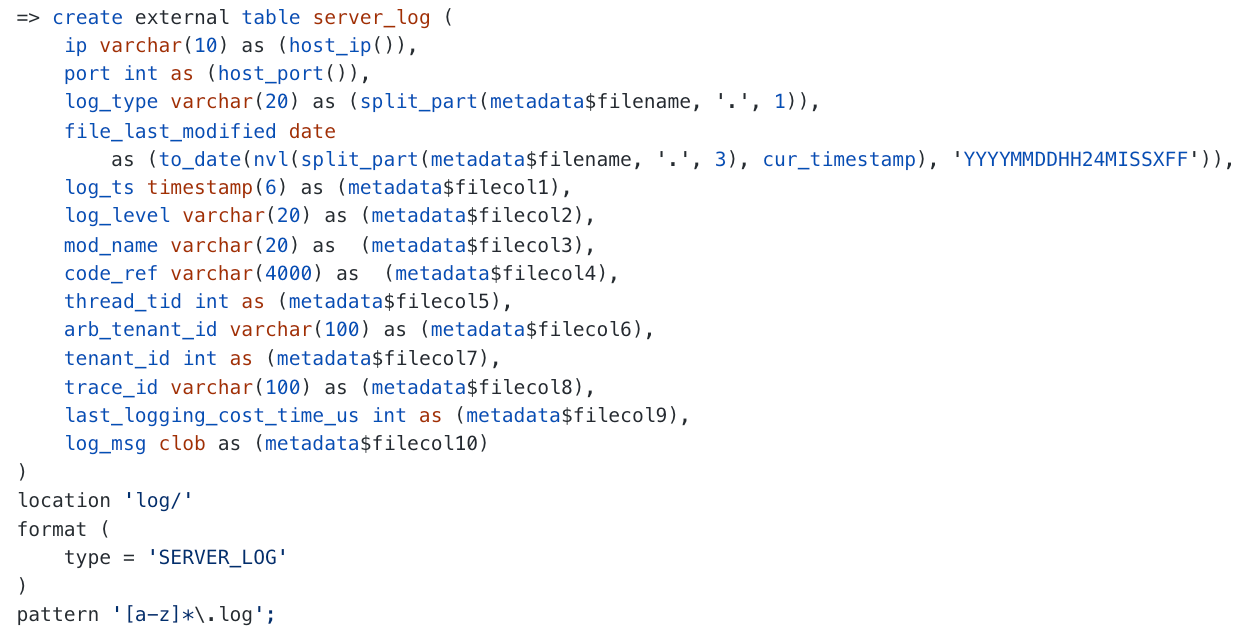
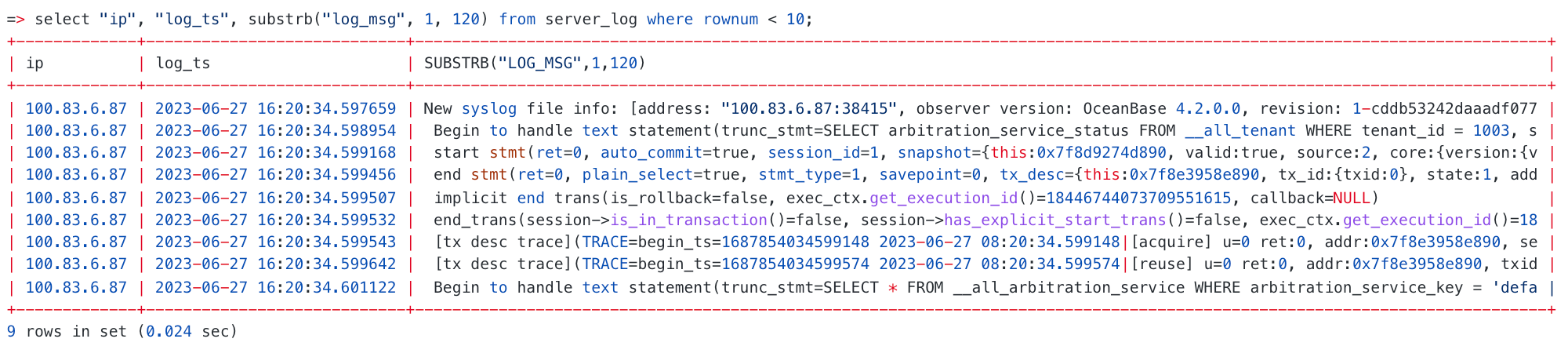
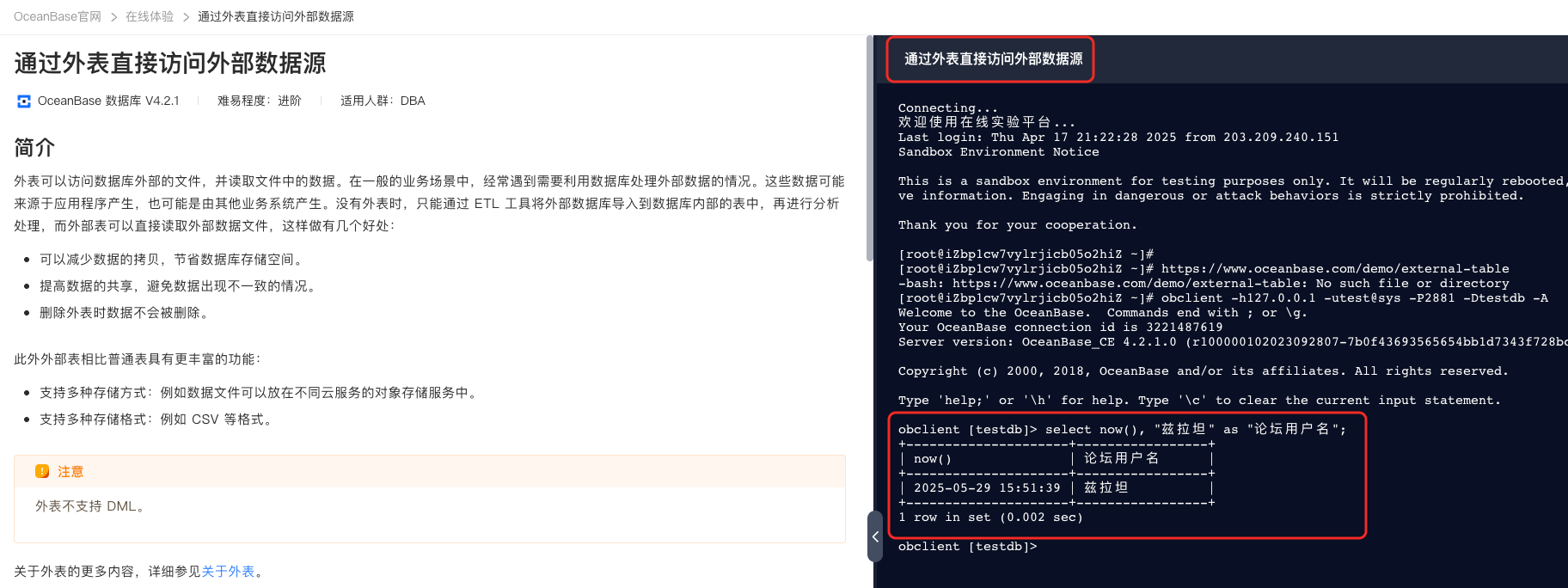
最后再为大家介绍一个和外表相关的特性(4.3.5 版本开始支持)—— 通过 Select Into 导出 Parquet 和 ORC 文件 作为本次课程内容的一个补充(外表是导入,下面这个是导出),欢迎感兴趣的同学进行阅读。
导出Parquet
数据类型映射
目前 OceanBase 通过 Select Into 导出 Parquet 格式支持了 MySQL 和 Oracle 数据类型,数据类型的映射表如下:
| Parquet物理类型 |
Parquet 逻辑类型 |
Hive数据类型 |
OB-MySQL数据类型 |
OB-Oracle数据类型 |
备注 |
| INT32 |
INT(8,TRUE) |
TINYINT |
TINYINT |
\ |
|
| INT32 |
INT(16,TRUE) |
SMALLINT |
SMALLINT |
\ |
|
| INT32 |
INT(32,TRUE) |
INT |
INT |
\ |
|
| INT64 |
INT(64,TRUE) |
BIGINT |
BIGINT |
\ |
|
| INT32 |
INT(8,FALSE) |
TINYINT(超限为null) |
TINYINT UNSIGNED |
\ |
|
| INT32 |
INT(16,FALSE) |
SMALLINT(超限为null) |
SMALLINT UNSIGNED |
\ |
|
| INT32 |
INT(32,FALSE) |
INT(超限为null) |
INT UNSIGNED |
\ |
|
| INT64 |
INT(64,FALSE) |
BIGINT(超限为null) |
BIGINT UNSIGNED |
\ |
|
| FLOAT |
NONE |
FLOAT |
FLOAT |
BINARY_FLOAT |
|
| DOUBLE |
NONE |
DOUBLE |
DOUBLE |
BINARY_DOUBLE |
|
| FIXED_LEN_BYTE_ARRAY |
DECIMAL |
DECIMAL |
DECIMAL, DECIMAL UNSIGNED |
NUMBER |
必须指定precision和scale |
| BYTE_ARRAY |
STRING |
CHAR |
CHAR, BINARY |
CHAR |
Parquet的string类型都是utf8编码 |
| BYTE_ARRAY |
STRING |
VARCHAR |
VARCHAR, VARBINARY |
VARCHAR2 |
|
| BYTE_ARRAY |
STRING |
STRING |
TINYTEXT, TEXT, MEDIUMTEXT, LONGTEXT, TINYBLOB, BLOB, MEDIUMBLOB, LONGBLOB |
RAW, BLOB, CLOB |
|
| INT64 |
TIMESTAMP(is_adjusted_to_utc=true, parquet::LogicalType::TimeUnit::MICROS) |
TIMESTAMP |
TIMESTAMP |
\ |
|
| INT64 |
TIMESTAMP(is_adjusted_to_utc=false, parquet::LogicalType::TimeUnit::MICROS) |
TIMESTAMP |
DATETIME |
DATE |
|
| INT96 |
NONE |
TIMESTAMP |
|TIMESTAMP, TIMESTAMP WITH LOCAL TIME ZONE |
|
|
| INT32 |
DATE |
DATE |
DATE |
\ |
|
| INT64 |
TIME |
\ |
TIME |
\ |
|
| INT32 |
INT(8,FALSE) |
\ |
YEAR |
\ |
|
语法
使用新增的FORMAT语法导出Parquet文件,指定type为Parquet。
SELECT * FROM t1
INTO outfile 'outfiles/data1'
FORMAT (
TYPE = 'PARQUET',
COMPRESSION = '<string>'
ROW_GROUP_SIZE = '<string>' | <int>
);
COMPRESSION 用于指定Parquet文件的压缩格式,ROW_GROUP_SIZE用于指定Parquet文件的ROW GROUP大小。生成的Parquet文件后缀名为.parquet。
COMPRESSION 选项支持的参数:‘UNCOMPRESSED’(表示文件没有压缩), ‘SNAPPY’, ‘GZIP’, ‘BROTLI’, ‘ZSTD’, ‘LZ4’, ‘LZ4_HADOOP’。不指定时默认值为’UNCOMPRESSED’。
ROW_GROUP_SIZE选项可以写数字,单位为字节,或者写形如’64MB’的字符串。不指定时默认值为’256MB’。建议用户使用默认值。
使用示例
-- 将t1表导出为Parquet格式的文件,文件名为data1.parquet
SELECT * FROM t1 into outfile 'data1.parquet'
format = (TYPE = 'PARQUET');
-- 将t1表导出为Parquet格式的文件并指定压缩算法为snappy
SELECT * FROM t1 into outfile 'data1.parquet'
format = (TYPE = 'PARQUET' COMPRESSION = 'SNAPPY');
-- 将t1表导出为Parquet格式的文件并指定row_group大小为128MB
SELECT * FROM t1 into outfile 'data1.parquet'
format = (TYPE = 'PARQUET' ROW_GROUP_SIZE = '128MB');
-- 将t1表导出为Parquet格式的多个文件
-- 导出的文件形如:data1_0_0_0.parquet, data1_0_1_0.parquet
SELECT /*+parallel(2)*/ * FROM t1 into outfile 'data1'
format = (TYPE = 'PARQUET')
single = false;
-- 将t1表按分区导出,以c1列的值作为分区依据
-- 导出的文件形如:
-- oss://bucket_name/test_parquet/1/data_0_0_0.parquet
-- oss://bucket_name/test_parquet/2/data_0_1_0.parquet
-- oss://bucket_name/test_parquet/3/data_0_0_0.parquet
-- oss://bucket_name/test_parquet/4/data_0_1_0.parquet
SELECT /*+parallel(2)*/ *
FROM t1
into outfile 'oss://bucket_name/test_parquet/?host=**&access_id=**&access_key=**'
partition by cast(c1 as char)
format = (TYPE = 'PARQUET')
single = false;
导出ORC
数据类型映射
目前OceanBase通过Select Into导出ORC格式支持了MySQL和Oracle数据类型,数据类型的映射表如下:
| ORC类型 |
Hive数据类型 |
OB-MySQL数据类型 |
OB-Oracle数据类型 |
| BYTE |
TINYINT |
TINYINT |
\ |
| SHORT |
SMALLINT |
SMALLINT |
\ |
| INT |
INT |
INT |
\ |
| LONG |
BIGINT |
BIGINT |
\ |
| FLOAT |
FLOAT |
FLOAT |
BINARY_FLOAT |
| DOUBLE |
DOUBLE |
DOUBLE |
BINARY_DOUBLE |
| DECIMAL |
DECIMAL |
DECIMAL |
NUMBER |
| CHAR |
CHAR |
CHAR |
CHAR |
| VARCHAR |
VARCHAR |
VARCHAR |
VARCHAR2 |
| STRING |
STRING |
TINYTEXT/TEXT/MEDIUMTEXT/LONGTEXT |
CLOB |
| BINARY |
BINARY |
TINYBLOB/BLOB/MEDIUMBLOB/LONGBLOB/BINARY/VARBINARY |
BLOB/RAW |
| DATE |
DATE |
DATE |
\ |
| TIMESTAMP |
TIMESTAMP |
DATETIME/TIMESTAMP |
DATE/TIMESTAMP/TIMESTAMP WITH LOCAL TIME ZONE |
语法
使用新增的FORMAT语法导出ORC文件,指定type为ORC。
SELECT * FROM t1
INTO outfile 'outfiles/data1'
FORMAT = (
TYPE = 'ORC'
COMPRESSION = '<string>'
COMPRESSION_BLOCK_SIZE = '<string>' | <int>
STRIPE_SIZE = '<string>' | <int>
ROW_INDEX_STRIDE = <int>
)
COMPRESSION 用于指定ORC文件的压缩格式。
COMPRESSION 选项支持的参数:‘UNCOMPRESSED’(表示文件没有压缩), ‘SNAPPY’, ‘ZLIB’,‘LZ4’,‘ZSTD’。不指定时默认值为’UNCOMPRESSED’。
COMPRESSION_BLOCK_SIZE 指的是数据在压缩时被分割成的块大小,可以写数字(单位为字节),或者写形如’64KB’的字符串。不指定时默认值为256 KB。建议用户使用默认值。
STRIPE_SIZE用于指定ORC文件的stripe大小,可以写数字(单位为字节),或者写形如’64MB’的字符串。不指定时默认值为64 MB。建议用户使用默认值。
ROW_INDEX_STRIDE是控制索引记录的频率的参数,定义了每隔多少行记录一次索引,不指定时默认值为10000。建议用户使用默认值。
生成的ORC文件后缀名为.orc。
使用示例
-- 将t1表导出为ORC格式的文件,文件名为data1.orc
SELECT * FROM t1 into outfile 'data1.orc' format = (TYPE = 'ORC');
-- 将t1表导出为ORC格式的文件并指定压缩算法为snappy
SELECT * FROM t1 into outfile 'data1.orc'
format = (TYPE = 'ORC' COMPRESSION = 'SNAPPY');
-- 将t1表导出为ORC格式的文件并指定STRIPE_SIZE大小为128MB
SELECT * FROM t1 into outfile 'data1.orc'
format = (TYPE = 'ORC' STRIPE_SIZE = '128MB');
-- 将t1表导出为ORC格式的文件并指定COMPRESSION_BLOCK_SIZE大小为256KB
SELECT * FROM t1 into outfile 'data1.orc'
format = (TYPE = 'ORC' COMPRESSION_BLOCK_SIZE = '256KB');
-- 将t1表导出为ORC格式的文件并指定ROW_INDEX_STRIDE大小为10000
SELECT * FROM t1 into outfile 'data1.orc'
format = (TYPE = 'ORC' ROW_INDEX_STRIDE = 10000);
-- 将t1表导出为ORC格式的多个文件
-- 导出的文件形如:data1_0_0_0.orc, data1_0_1_0.orc
SELECT /*+parallel(2)*/
*
FROM t1 into outfile 'data1'
format = (TYPE = 'ORC')
single = false;
-- 将t1表按分区导出,以c1列的值作为分区依据
-- 导出的文件形如:
-- oss://bucket_name/test_orc/1/data_0_0_0.orc
-- oss://bucket_name/test_orc/2/data_0_1_0.orc
-- oss://bucket_name/test_orc/3/data_0_0_0.orc
-- oss://bucket_name/test_orc/4/data_0_1_0.orc
SELECT /*+parallel(2)*/ *
FROM t1
into outfile 'oss://bucket_name/test_orc/?host=**&access_id=**&access_key=**'
partition by cast(c1 as char)
format = (TYPE = 'ORC')
single = false;