背景
当前 OCP(OceanBase Cloud Platform)已配置 278 项告警规则,全面覆盖 OceanBase 数据库的架构运行、性能指标、事务处理、存储系统等核心场景。然而在生产环境实践中,高频次的告警推送已对运维管理效率产生一定影响,主要体现在:
-
告警数量冗余导致关键信息识别成本增加;
-
重复性告警消耗大量人力进行被动响应;
-
缺乏前置性分析工具支撑运维策略优化。
优化目标
基于知识图谱的关联分析、AI 智能降噪算法及趋势预测模型,我们计划实现:
-
告警数量精简化:通过智能过滤与聚合规则降低无效告警干扰;
-
处置流程自动化:为高频告警提供标准化解决方案与自动化修复建议;
-
运维模式升级:推动从 “被动故障响应” 向 “主动风险预防” 的能力转型。
调研需求
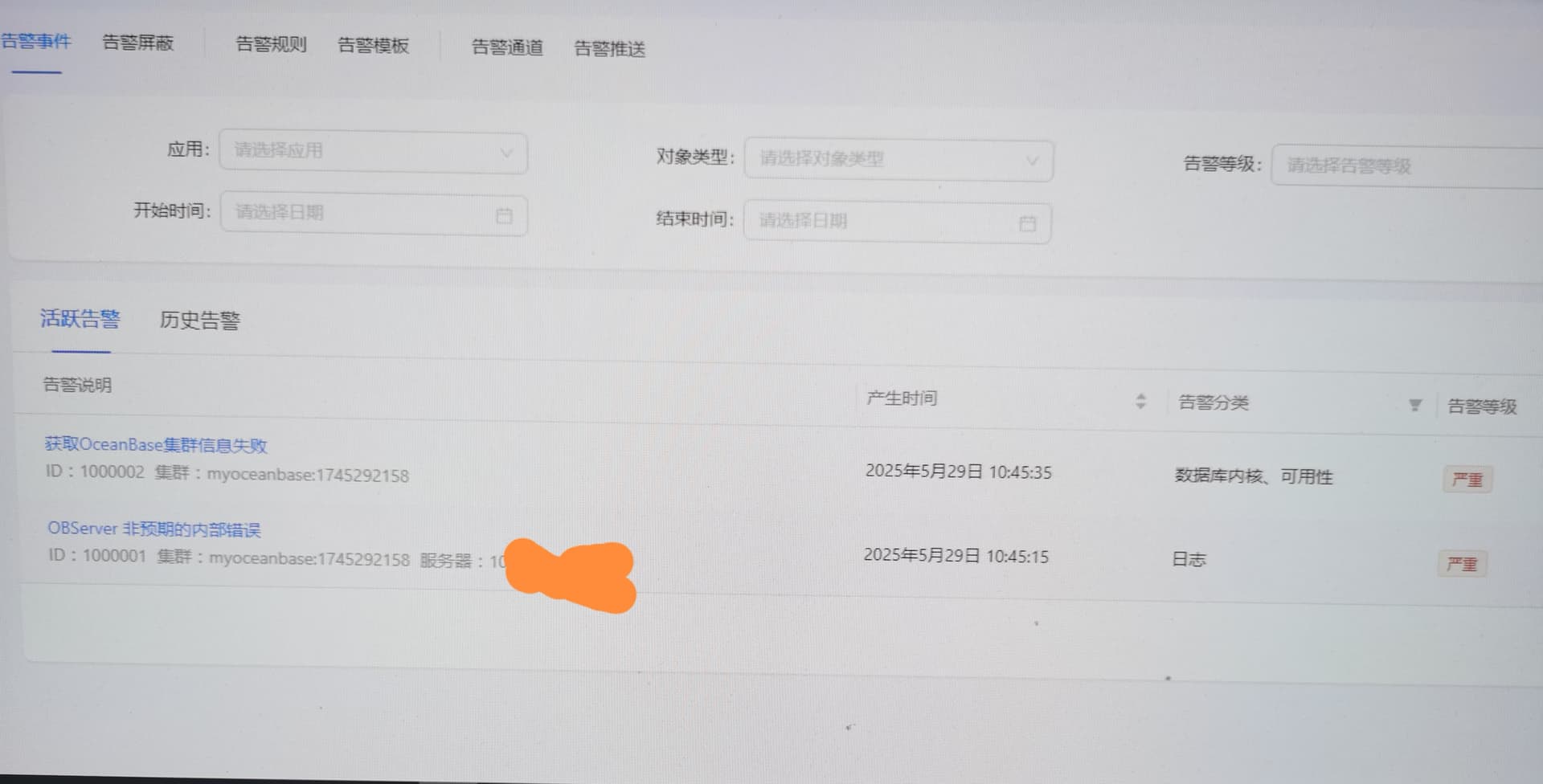
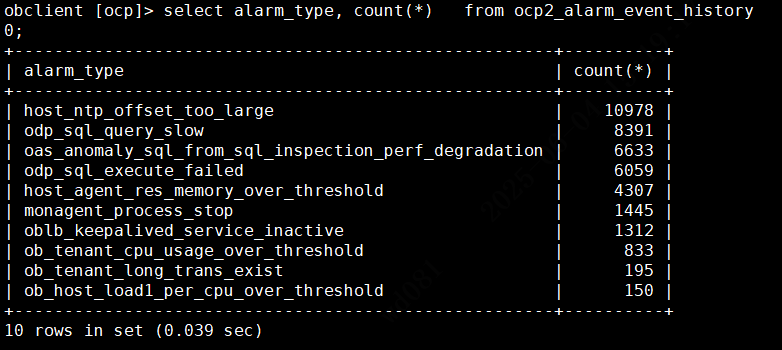
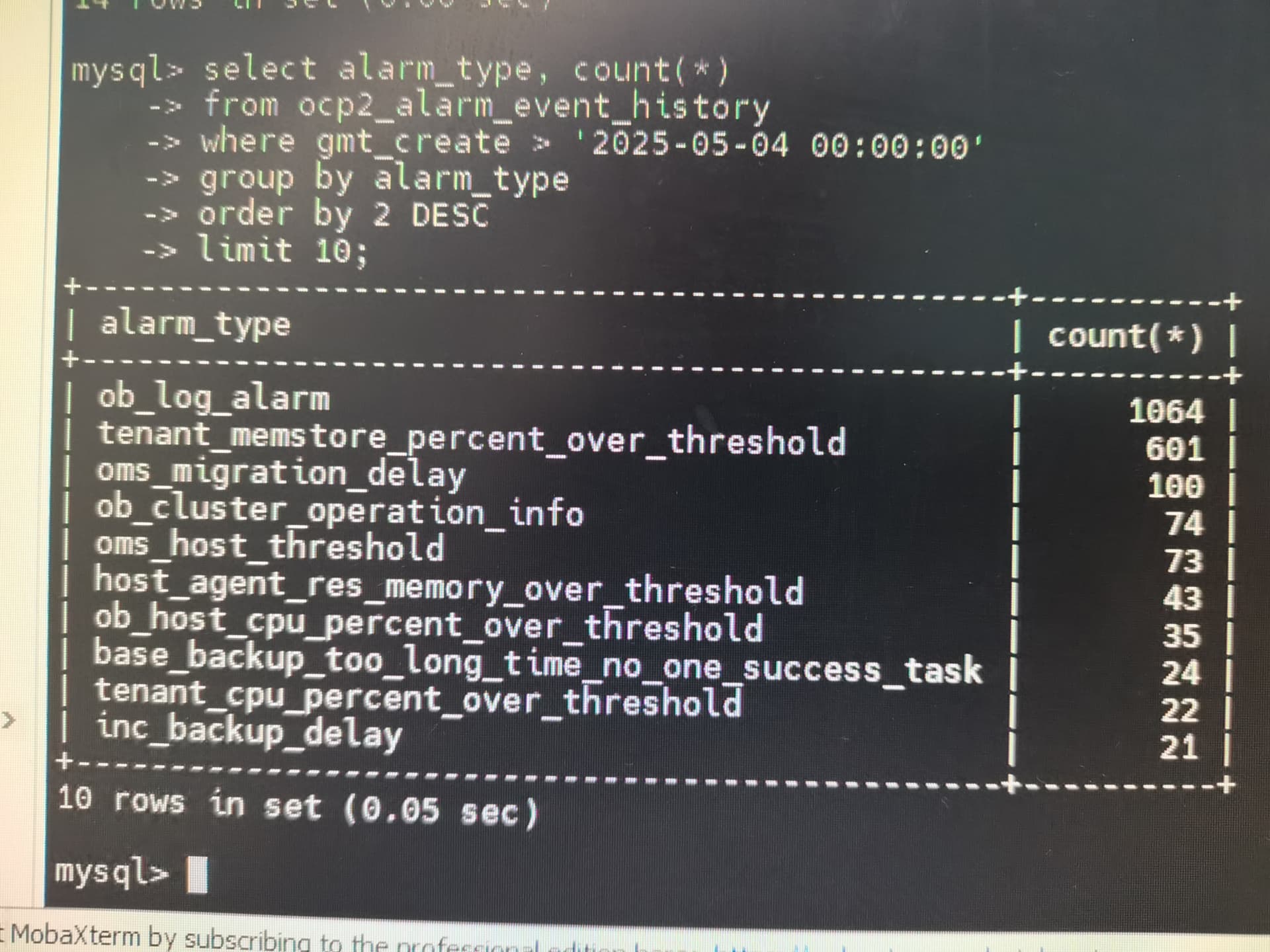
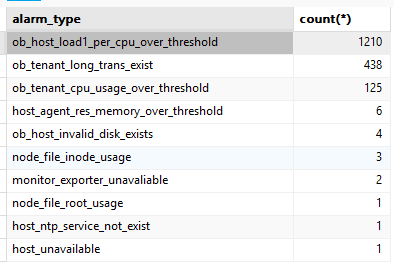
诚邀各位社区伙伴,在本帖中反馈您在生产环境中 TOP 10 高频告警类型(如 “OBServer 节点连接异常”、“日志磁盘使用率超限” 等)。
我们将基于大家真实场景的数据,持续迭代优化模型,目标为用户减少 90% 以上重复性告警处理工作,并优先针对高频问题输出智能化解决方案。
输出示例
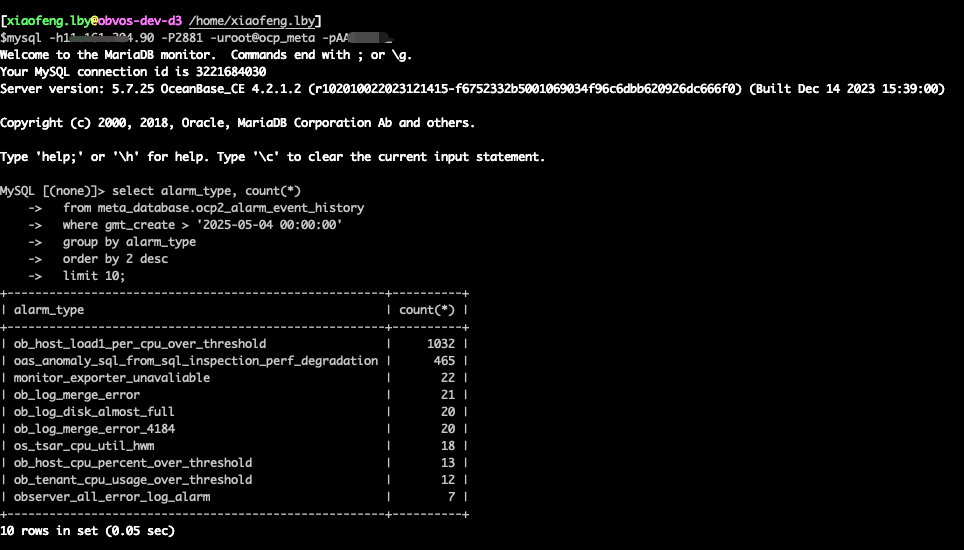
大家可以通过连接 OCP 的 meta 库,然后执行下面这条 SQL 语句获得相应的数据:
select alarm_type, count(*)
from meta_database.ocp2_alarm_event_history
where gmt_create > '2025-05-04 00:00:00'
group by alarm_type
order by 2 desc
limit 10;
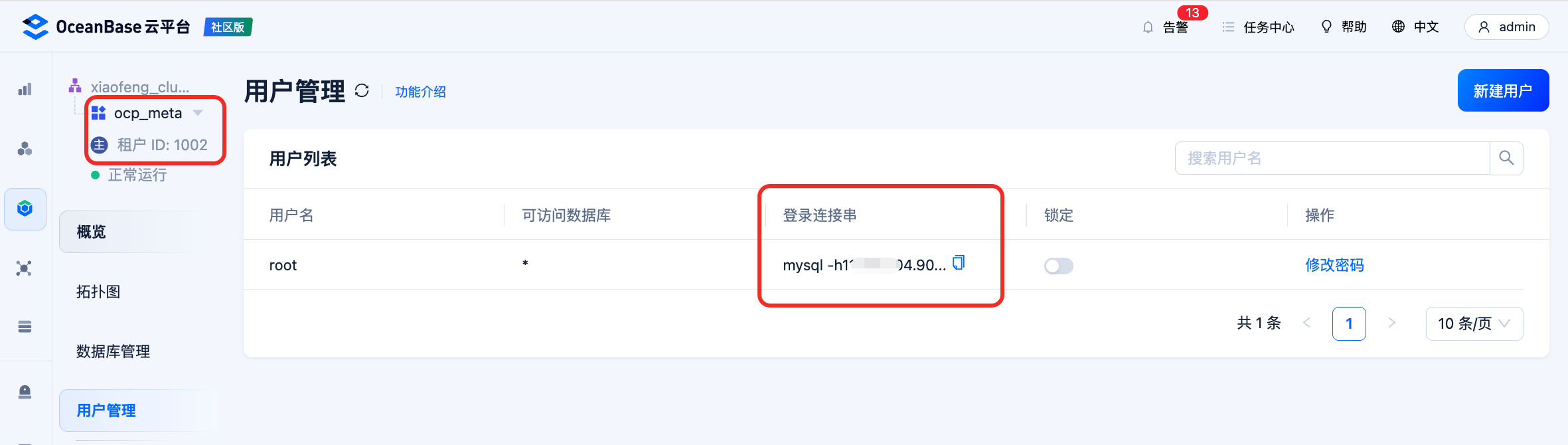
连接 OCP meta 租户的方式:选择 ocp meta 租户 → 用户管理 → 复制登录连接串 → 执行。