【 使用环境 】 测试环境
【 使用版本 】OBServer
5.7.25-OceanBase_CE-v4.3.5.0
【问题描述】连续插入一天数据后崩溃。
【复现路径】
【附件及日志】observer日志和obdiag日志见附件。貌似没有产生coredump。
observer.log.zip (28.0 MB)
gather_scene_20250603100931.zip (28.7 MB)
【 使用环境 】 测试环境
【 使用版本 】OBServer
5.7.25-OceanBase_CE-v4.3.5.0
【问题描述】连续插入一天数据后崩溃。
【复现路径】
【附件及日志】observer日志和obdiag日志见附件。貌似没有产生coredump。
observer.log.zip (28.0 MB)
gather_scene_20250603100931.zip (28.7 MB)
obdiag发现有句这个,不知道是什么原因
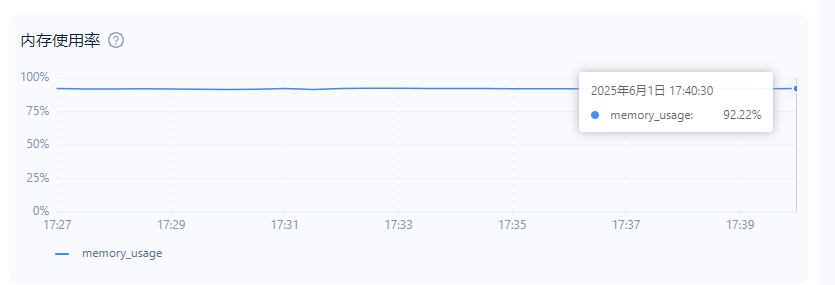
[日 6月 1 17:41:43 2025] Out of memory: Killed process 2196804 (observer) total-vm:32695856kB, anon-rss:31240376kB, file-rss:0kB, shmem-rss:0kB
系统内存如下,分配给oceanbaser的memory_limit_percent为80%
[root@localhost log]# free -h
total used free shared buff/cache available
Mem: 41Gi 39Gi 269Mi 1.2Gi 2.1Gi 799Mi
Swap: 5.9Gi 5.9Gi 0B
ob集群怎么部署的 是obd部署的么?如果是请提供一下
obd cluster list --查一下集群名
obd cluster edit-config {集群名} --保存配置文件到文本上 提供一下
看着像是配置的ob内存超过了物理机的内存 导致的
是OBD部署的,一开始给的9G,后来通过ocpexpress修改为0M后,修改memory_limit_percent为80%。
enable_syslog_wf: false
max_syslog_file_count: 4
production_mode: false
memory_limit: 9G
datafile_size: 24G
system_memory: 1G
log_disk_size: 24G
cpu_count: 22
datafile_maxsize: 1T
datafile_next: 149G
depends:
上面的日志 是ob宕机时候的日志么?
是的,6.1日宕机的,2天了,后面没重开过直接取的日志
服务器上还有其它应用程序,会不会分配了80%内存后,ob占用到了80%,而其它应用程序内存又在涨,总量达到OOM KILLER的限值导致杀掉了OB?
下面的信息查一下
show parameters where name in (‘memory_limit’,‘memory_limit_percentage’,‘system_memory’,‘log_disk_size’,‘log_disk_percentage’,‘datafile_size’,‘datafile_disk_percentage’);
select zone,concat(SVR_IP,’:’,SVR_PORT) observer,
cpu_capacity_max cpu_total,cpu_assigned_max cpu_assigned,
cpu_capacity-cpu_assigned_max as cpu_free,
round(memory_limit/1024/1024/1024,2) as memory_total,
round((memory_limit-mem_capacity)/1024/1024/1024,2) as system_memory,
round(mem_assigned/1024/1024/1024,2) as mem_assigned,
round((mem_capacity-mem_assigned)/1024/1024/1024,2) as memory_free,
round(log_disk_capacity/1024/1024/1024,2) as log_disk_capacity,
round(log_disk_assigned/1024/1024/1024,2) as log_disk_assigned,
round((log_disk_capacity-log_disk_assigned)/1024/1024/1024,2) as log_disk_free,
round((data_disk_capacity/1024/1024/1024),2) as data_disk,
round((data_disk_in_use/1024/1024/1024),2) as data_disk_used,
round((data_disk_capacity-data_disk_in_use)/1024/1024/1024,2) as data_disk_free
from oceanbase.gv$ob_servers;
查询如下(重启后的)。
zone |observer |cpu_total|cpu_assigned|cpu_free|memory_total|system_memory|mem_assigned|memory_free|log_disk_capacity|log_disk_assigned|log_disk_free|data_disk|data_disk_used|data_disk_free|
-----+----------------+---------+------------+--------+------------+-------------+------------+-----------+-----------------+-----------------+-------------+---------+--------------+--------------+
zone1|172.16.0.65:2882| 22.0| 20.0| 2.0| 29.34| 1.00| 28.00| 0.34| 100.00| 80.00| 20.00| 1024.00| 9.11| 1014.89|
你发的ERROR提示是set log_disk_size greater than 94208MB,即92GB,但现在这个log_disk_size是obd部署的时候默认值100G,提示是否有问题?
zone |svr_ip |tenant_name|tenant_type|max_cpu|min_cpu|memory_size_gb|log_disk_size|log_disk_in_use|data_disk_in_use|
-----+-----------+-----------+-----------+-------+-------+--------------+-------------+---------------+----------------+
zone1|172.16.0.65|META$1002 |META | | | 1.00| 0.60| 0.43| 0.28|
zone1|172.16.0.65|META$1004 |META | | | 2.40| 7.20| 5.75| 0.23|
zone1|172.16.0.65|ocp_meta |USER | 1.0| 1.0| 1.00| 5.40| 4.29| 0.36|
zone1|172.16.0.65|sys |SYS | 3.0| 3.0| 2.00| 2.00| 1.59| 0.23|
zone1|172.16.0.65|wisdom |USER | 16.0| 16.0| 21.60| 64.80| 51.78| 10.54|
这是查询的结果,wisdom租户是实际使用的租户
这个查询一下
show parameters where name in (‘memory_limit’,‘memory_limit_percentage’,‘system_memory’,‘log_disk_size’,‘log_disk_percentage’,‘datafile_size’,‘datafile_disk_percentage’);
资源不足吧
资源的问题
信息反馈内存不足
学习一下
zone |svr_type|svr_ip |svr_port|name |data_type|value|info |section |scope |source |edit_level |default_value|isdefault|
-----+--------+-----------+--------+------------------------+---------+-----+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------+-------+-------+-----------------+-------------+---------+
zone1|observer|172.16.0.65| 2882|log_disk_percentage |INT |0 |the percentage of disk space used by the log files. Range: [0,99] in integer;only effective when parameter log_disk_size is 0;when log_disk_percentage is 0: a) if the data and the log are on the same disk, means log_disk_percentage = 30 b) if the data and|LOGSERVICE|CLUSTER|DEFAULT|DYNAMIC_EFFECTIVE|0 | 1|
zone1|observer|172.16.0.65| 2882|log_disk_size |CAPACITY |100G |the size of disk space used by the log files. Range: [0, +∞) |LOGSERVICE|CLUSTER|DEFAULT|DYNAMIC_EFFECTIVE|0M | 0|
zone1|observer|172.16.0.65| 2882|memory_limit_percentage |INT |70 |the size of the memory reserved for internal use(for testing purpose). Range: [10, 95] |OBSERVER |CLUSTER|DEFAULT|DYNAMIC_EFFECTIVE|80 | 0|
zone1|observer|172.16.0.65| 2882|system_memory |CAPACITY |1G |the memory reserved for internal use which cannot be allocated to any outer-tenant, and should be determined to guarantee every server functions normally. Range: [0M,) |OBSERVER |CLUSTER|DEFAULT|DYNAMIC_EFFECTIVE|0M | 0|
zone1|observer|172.16.0.65| 2882|memory_limit |CAPACITY |0M |the size of the memory reserved for internal use(for testing purpose), 0 means follow memory_limit_percentage. Range: 0, [1G,). |OBSERVER |CLUSTER|DEFAULT|DYNAMIC_EFFECTIVE|0M | 1|
zone1|observer|172.16.0.65| 2882|datafile_disk_percentage|INT |0 |the percentage of disk space used by the data files. Range: [0,99] in integer |SSTABLE |CLUSTER|DEFAULT|DYNAMIC_EFFECTIVE|0 | 1|
zone1|observer|172.16.0.65| 2882|datafile_size |CAPACITY |24G |size of the data file. Range: [0, +∞) |SSTABLE |CLUSTER|DEFAULT|DYNAMIC_EFFECTIVE|0M | 0|
这是分配量,不是使用量
你是用obd搭建的ob集群 后面黑屏修改的配置项log_disk_size的大小么?log_disk_size看着是100G