【 使用环境 】生产环境
【 OB or 其他组件 】
【 使用版本 】4.2.1-10BP
【问题描述】
数据库备份失败,显示错误信息为module: BACKUP_DATA, result: -4184(Server out of disk space)。
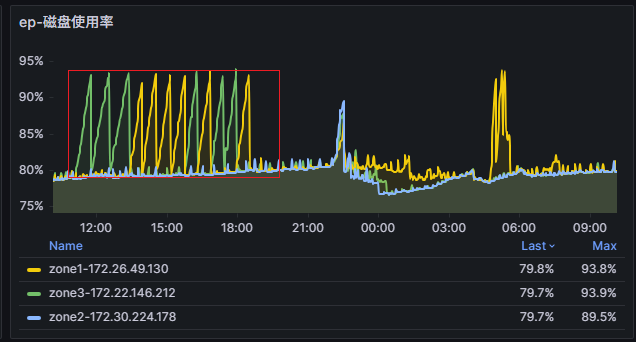
查看了下备份期间,有一台副本磁盘被占用接近95%。 备份的时候为什么会占用磁盘空间
【 使用环境 】生产环境
【 OB or 其他组件 】
【 使用版本 】4.2.1-10BP
【问题描述】
数据库备份失败,显示错误信息为module: BACKUP_DATA, result: -4184(Server out of disk space)。
查看了下备份期间,有一台副本磁盘被占用接近95%。 备份的时候为什么会占用磁盘空间
根据文档库中的信息,错误码 -4184 表示磁盘空间不足。以下是关于此问题的详细分析和解决方法:
备份过程占用磁盘空间的原因
在 OceanBase 数据库中,备份操作需要将数据写入到磁盘上的备份文件中。如果磁盘空间不足,备份操作会失败并返回错误码 -4184。此外,备份期间可能会生成临时文件或日志文件,进一步占用磁盘空间。
磁盘空间不足的风险
根据文档片段 4 的描述,当事务日志(CLOG)空间利用率超过 [log_disk_utilization_limit_threshold](默认为 95%)时,节点会停止写入。这可能导致备份失败或其他业务操作异常。
副本磁盘占用接近 95% 的影响
如果某台副本的磁盘占用接近 95%,可能已经触发了磁盘空间限制,导致备份无法继续。
df -h
/home/admin/oceanbase/backup 或类似路径,请根据实际环境确认。alter system set syslog_io_bandwidth_limit='10M';
alter system set enable_syslog_recycle = true;
alter system set max_syslog_file_count = 1000;
备份失败的原因是磁盘空间不足,建议按照上述步骤逐一排查和解决问题。如果问题仍未解决,可以参考文档片段 6 提供的日志路径,进一步定位问题原因,并联系 OceanBase 技术支持人员协助排查。
详情请参考:
磁盘空间满了啊,或者文件指针用尽了
只有备份期间磁盘空间使用率会上涨是吗?集群是什么部署架构的?只有一台observer上涨?
使用obdiag分析下报错时的日志
obdiag analyze log [options]
https://www.oceanbase.com/docs/common-obdiag-cn-1000000001768214
您把您的集群的规划简单介绍下,同时您的备份的配置比如使用nfs 也介绍下
根据文档库中的信息,您可以使用以下方法来查询哪些 SQL 查询占用了较大的内存和磁盘资源:
查询大 SQL 查询的方法
利用 gv$ob_processlist 查找慢查询
根据文档片段 5 的描述,可以使用 gv$ob_processlist 视图来查找慢查询。执行以下 SQL 查询以获取占用较多资源的 SQL 请求:
SELECT *
FROM gv$ob_processlist
WHERE state = 'executing'
ORDER BY time DESC;
此查询将返回正在执行的 SQL 请求,并按照执行时间降序排列。重点关注执行时间较长的 SQL 请求。
利用 gv$ob_sql_audit 查找资源消耗大的 SQL
根据文档片段 4 的描述,可以使用 gv$ob_sql_audit 视图来分析 SQL 执行计划的获取耗时。执行以下 SQL 查询以获取资源消耗较大的 SQL 请求:
SELECT sql_id, get_plan_time, execute_time, rows_examined, mem_used
FROM gv$ob_sql_audit
ORDER BY get_plan_time DESC, execute_time DESC, rows_examined DESC, mem_used DESC;
此查询将返回按获取执行计划耗时、执行时间、扫描行数和内存使用量降序排列的 SQL 请求列表。重点关注这些指标较高的 SQL 请求。
利用 gv$plan_cache_plan_stat 分析执行计划
根据文档片段 5 的描述,可以使用 gv$plan_cache_plan_stat 视图来分析执行计划的性能。执行以下 SQL 查询以获取性能较差的执行计划:
SELECT sql_id, plan_id, avg_exe_time, avg_cpu_time, avg_mem_used, avg_rows_examined
FROM gv$plan_cache_plan_stat
ORDER BY avg_exe_time DESC, avg_cpu_time DESC, avg_mem_used DESC, avg_rows_examined DESC;
此查询将返回按平均执行时间、CPU 时间、内存使用量和扫描行数降序排列的执行计划列表。重点关注这些指标较高的执行计划。
利用 gv$plan_cache_plan_explain 获取执行计划详情
根据文档片段 5 的描述,可以使用 gv$plan_cache_plan_explain 视图来获取执行计划的详细信息。执行以下 SQL 查询以获取特定 SQL 请求的执行计划:
SELECT *
FROM gv$plan_cache_plan_explain
WHERE sql_id = '<目标_sql_id>' AND plan_id = <目标_plan_id>;
将 <目标_sql_id> 和 <目标_plan_id> 替换为从上一步查询中获得的值。此查询将返回目标 SQL 请求的执行计划详细信息,帮助您了解其资源消耗情况。
结合 SQL Diagnoser 工具进行诊断
根据文档片段 8 的描述,可以使用 SQL Diagnoser 工具对业务集群中的可疑 SQL 进行诊断。该工具能够提供索引优化建议和 SQL 改写建议,帮助您进一步优化资源消耗较大的 SQL 请求。
总结
通过以上方法,您可以查询到占用较大内存和磁盘资源的 SQL 请求。根据查询结果,您可以采取相应的优化措施,例如调整 SQL 语句、创建索引或优化执行计划等,以减少资源消耗并避免备份失败的问题。
更多信息请查看:
根据文档库中的信息,OCP 的 SQL 诊断功能确实提供了多种维度的筛选和分析能力,但直接针对内存和磁盘占用的指标需要进一步明确。以下是详细解答:
依据文档片段 2 和文档片段 4 的描述,OCP 提供了以下几种 SQL 诊断类型:
虽然 OCP 的 SQL 诊断功能没有直接以“内存”或“磁盘”为筛选指标,但可以通过其他间接指标来推测哪些 SQL 占用了较多资源。
rows_examined 和 mem_used 筛选
在文档片段 4 中提到,gv$ob_sql_audit 视图可以提供 SQL 的资源消耗信息,包括:
rows_examined:扫描的行数。mem_used:内存使用量。您可以在 OCP 的 SQL 诊断页面中,结合这些指标进行高级搜索。如果 OCP 支持自定义 SQL 查询,可以直接运行以下语句:
SELECT sql_id, rows_examined, mem_used
FROM gv$ob_sql_audit
ORDER BY rows_examined DESC, mem_used DESC;
这将返回扫描行数最多和内存使用量最大的 SQL。
execute_time) 和 CPU 时间 (avg_cpu_time) 筛选
gv$plan_cache_plan_stat 视图可以提供 SQL 的平均执行时间和 CPU 时间:SELECT sql_id, avg_exe_time, avg_cpu_time, avg_mem_used
FROM gv$plan_cache_plan_stat
ORDER BY avg_exe_time DESC, avg_cpu_time DESC;
需要注意的是,根据文档片段 2 的说明:
目前社区版 OCP 暂不支持可疑 SQL 诊断功能。
因此,如果您使用的是社区版 OCP,可能无法直接利用可疑 SQL 功能来快速定位性能异常的 SQL。不过,您仍然可以通过 TopSQL 和 SlowSQL 功能,结合上述间接指标进行分析。
虽然 OCP 的 SQL 诊断功能没有直接提供“内存”和“磁盘”占用的筛选指标,但可以通过以下方式间接筛选出占用资源较大的 SQL:
rows_examined 和 mem_used 指标筛选扫描行数多或内存使用量大的 SQL。如果需要更精确的资源占用分析,建议结合 OB 数据库的系统视图(如 gv$ob_sql_audit 和 gv$plan_cache_plan_stat)进行深入挖掘。
检索到的文档如下: