

【 使用环境 】生产环境
【 OB or 其他组件 】
【 使用版本 】4.2.1-10BP
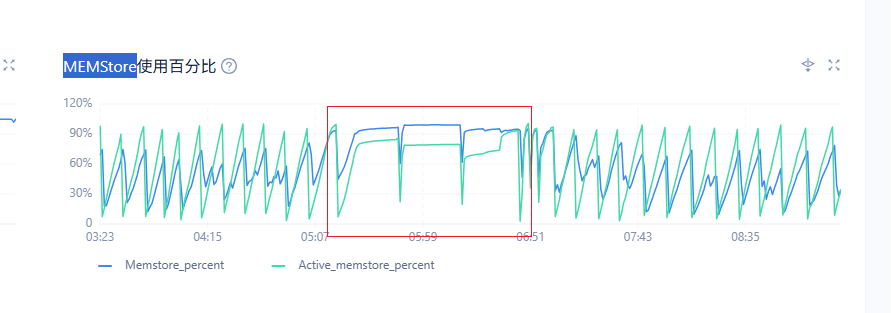
早上发现一台副本突然cpu长时间处于低使用率状态,就检查了下这台机器的其他指标。发现MEMStore使用百分比在这期间一直处于高位状态,未进行转储。 猜测是这台机器未能转储导致数据副本严重滞后其他副本,无法提供任何读写服务。才表现出cpu使用率低的状态。
无法转储的问题该如何排查。已经看了这台机器无论是内存和硬盘容量都绰绰有余。
【 使用环境 】生产环境
【 OB or 其他组件 】
【 使用版本 】4.2.1-10BP
早上发现一台副本突然cpu长时间处于低使用率状态,就检查了下这台机器的其他指标。发现MEMStore使用百分比在这期间一直处于高位状态,未进行转储。 猜测是这台机器未能转储导致数据副本严重滞后其他副本,无法提供任何读写服务。才表现出cpu使用率低的状态。
无法转储的问题该如何排查。已经看了这台机器无论是内存和硬盘容量都绰绰有余。
根据您提供的信息,MEMStore(即 MemTable)一直处于高使用比且无法转储的问题可能由以下原因引起。以下是综合文档信息和内在知识的分析与排查建议:
根据文档片段 7 和文档片段 8 的描述,OceanBase 数据库在 LSM-Tree 架构中,当 MemTable 达到一定阈值时会触发转储。如果转储未能发生,可能是以下原因之一:
排查方法:
SHOW TENANT MAJOR FREEZE 命令手动触发 Major Freeze,观察是否能解决问题。文档片段 2 提到了错误码 4677,其原因是“本次转储调度找不到符合转储条件的 MemTable 或者 SSTable”。这可能表明系统尝试进行转储但未能找到合适的对象。
排查方法:
4677 的报错。文档片段 5 提到,在密集写入场景下,小规格租户可能会因为 MemTable 达到上限而无法接受新的请求。虽然您提到内存和硬盘容量充足,但仍需检查以下配置:
排查方法:
memory_limit_percentage 和 memstore_limit_percentage,确保其设置合理。如果上述条件均正常,仍需考虑以下可能性:
排查方法:
SHOW TABLET STATUS 命令检查 Tablet 的状态,确认是否存在副本滞后或其他异常。如果以上方法均未能解决问题,可以进一步检查以下方面:
/home/admin/oceanbase/log),寻找与转储相关的错误信息。4.2.1-10BP,可能存在已知的 Bug。建议查阅该版本的 Release Notes 或联系技术支持以确认是否存在相关问题。根据文档库中的信息,您可以按照以下步骤逐步排查问题:
SHOW TABLET STATUS 和其他命令检查副本状态和节点状态。希望以上信息对您有所帮助!如果需要更详细的指导,请提供更多上下文信息(如系统日志、配置参数等)。
具体信息可参考以下文档:
转储进程没有正常运行呢吧
手动进行过 转储没 ?
要是线程有问题:重启节点试过没 ?
这个工具好
核心排查思路
![]() 是否有Flush Queue堆积?
是否有Flush Queue堆积?
查看FlushQueue的状态,是否有大量堆积的flush请求没有被执行。
如果flush请求太多,可能是flush线程数不够或者有阻塞。
![]() 检查Flush线程池状态
检查Flush线程池状态
HBase RegionServer 有 flush 线程池(如flush.handler)。
看看线程池配置和状态(是否有blocked线程或等待队列过长)。
![]() 观察WAL写入和同步
观察WAL写入和同步
flush 需要先写WAL(预写式日志)。如果WAL有瓶颈(如磁盘写入慢),flush也会被阻塞。
看一下WAL的写入延迟或堆积是否异常。
![]() HFile生成的写入速率是否受限
HFile生成的写入速率是否受限
flush过程是把memstore刷到HFile,需要写磁盘。
检查磁盘IO情况(如I/O wait、IOPS、带宽是否被其他进程占用)。
![]() 是否遇到写放大问题
是否遇到写放大问题
大量小flush导致写放大,进而和compaction冲突。
检查compaction状态是否非常繁忙。
flush和compaction之间的争用也会拖慢flush。
![]() 检查Region状态和Split/Compaction冲突
检查Region状态和Split/Compaction冲突
如果Region太大,flush量大,或者Region在split时阻塞,可能卡住。
看看这段时间有没有RegionSplit或Compaction日志。
![]() 相关配置参数
相关配置参数
hbase.hregion.memstore.flush.size (memstore大小阈值)。
hbase.regionserver.optionalcacheflushinterval (flush间隔)。
hbase.regionserver.handler.count (handler线程数)。
检查是否因为这些参数配置过低或过高导致flush受阻。