【 使用环境 】测试环境
【 OB or 其他组件 】
【 使用版本 】4.3.5LTS
【问题描述】使用docker部署的,空闲状态下cpu一直在50%左右,是什么原因呢?
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
【 使用环境 】测试环境
【 OB or 其他组件 】
【 使用版本 】4.3.5LTS
【问题描述】使用docker部署的,空闲状态下cpu一直在50%左右,是什么原因呢?
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
推荐使用 obdiag 工具进行日志采集,并且将采集到的日志提供给我们以便确认问题所在。
日志采集场景: CPU高
日志采集命令: obdiag gather scene run --scene=observer.cpu_high
为了更好地帮助您分析问题,请您按照上述命令采集日志并上传给我们。此外,还需要请您提供以下信息:
附上敏捷诊断工具 obdiag 使用帮助链接
这一列是CPU
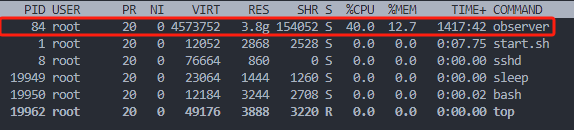
CPU高的进程
根据您提供的信息,Docker 部署的 OceanBase 社区版在空闲状态下 CPU 占用率持续在 50% 左右。以下是可能的原因及解决方法:
选举线程占用 CPU
sync_io_thread_count 参数配置
sync_io_thread_count 参数会影响 IO 线程的数量。如果该参数配置不当,可能会导致过多的线程竞争 CPU 资源。后台任务或定时任务
系统监控工具的影响
top 命令查看 CPU 使用情况,某些系统监控工具本身可能会占用一定的 CPU 资源。检查选举线程的 CPU 配额
SHOW PARAMETERS LIKE 'election_cpu_quota';
ALTER SYSTEM SET election_cpu_quota=10;
调整 sync_io_thread_count 参数
sync_io_thread_count 参数的值:SHOW PARAMETERS LIKE 'sync_io_thread_count';
ALTER SYSTEM SET sync_io_thread_count=48;
排查后台任务或定时任务
减少系统监控工具的影响
top 等系统监控工具的频率,或者考虑使用更高效的监控工具,如 htop 或 glances。如果以上方法未能解决问题,建议使用 OceanBase 的敏捷诊断工具 obdiag 收集更多诊断信息:
obdiag gather scene run --scene=observer.cpu_high
将采集到的日志提供给我们以便进一步确认问题所在。此外,还需要请您提供以下信息:
希望以上信息能够帮助您解决问题!
详情请参考:
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
看看sync_io_thread_count参数是不是配置不对
我也看看我的是不是选举cpu高,我好像没改这参数,默认值,CPU也不低
OceanBase 默认会根据机器 CPU 数自动起大量线程:
调度线程(sys_task_queue_thread_num)
容灾线程
I/O 提交线程等
即使没有业务请求,这些线程仍会运行调度循环。
尤其在 Docker 中(特别是默认 cgroup 限制失效时),OceanBase 可能认为自己拥有所有 CPU 核心,从而分配了大量线程。
日志刷盘 / flush 日志线程频繁运行
日志刷盘线程会定期检查是否有日志需要写入磁盘
尽管无业务写入,但后台日志线程仍在 tick loop 中不断运行
系统监控线程和租户心跳机制活跃
OceanBase 自带大量的后台服务线程,如:
租户统计
负载采集
内存监控
异步任务轮询器
这些线程虽然不重,但线程数很多,加在一起可能形成一定负载
4. Docker容器资源虚拟化导致监控异常
在 Docker 中运行 OB 时,如果未正确设置:
--cpuset-cpus 或 --cpu-quota 等限制
OB 可能认为其拥有整个物理机资源,导致调度线程过多docker分配了cpu多少
docker在部署ob的时候没有给限制
我限制下试试,感谢回答