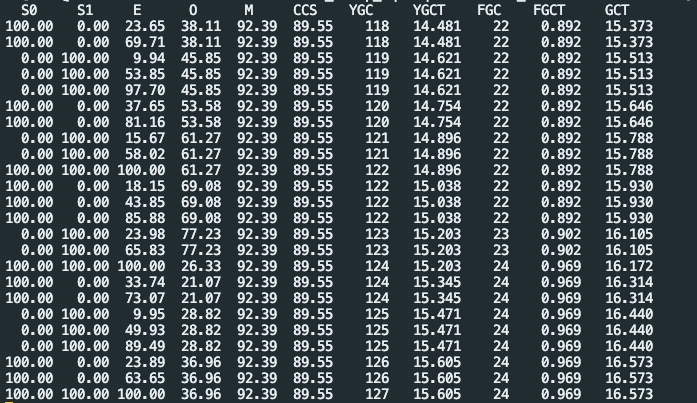
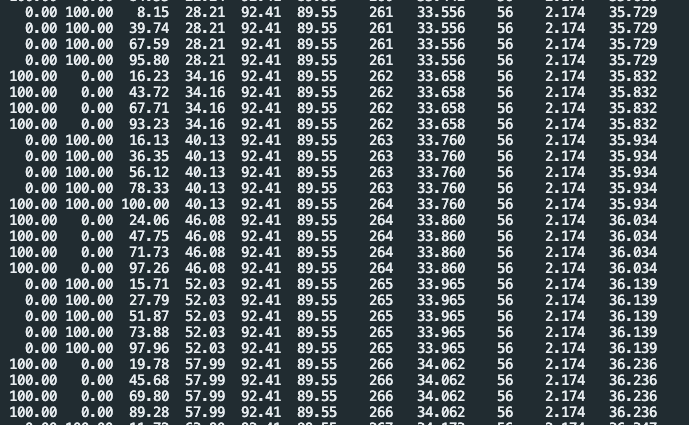
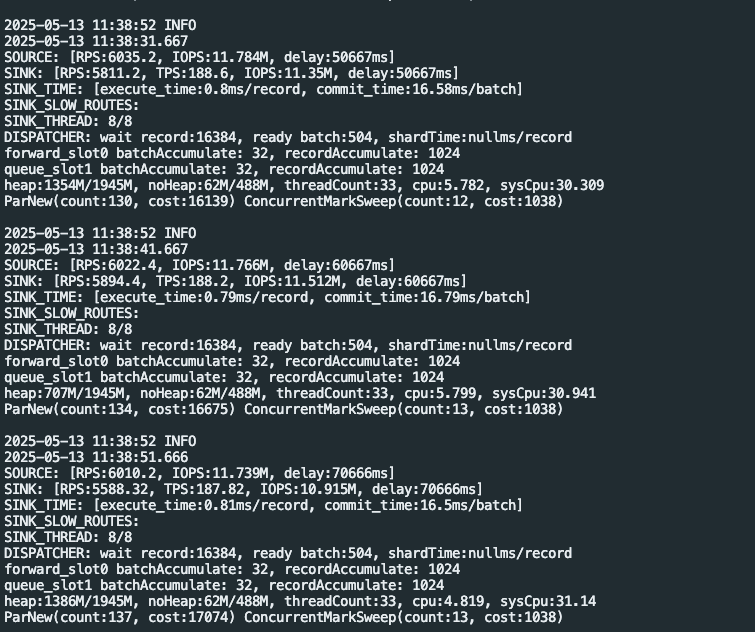
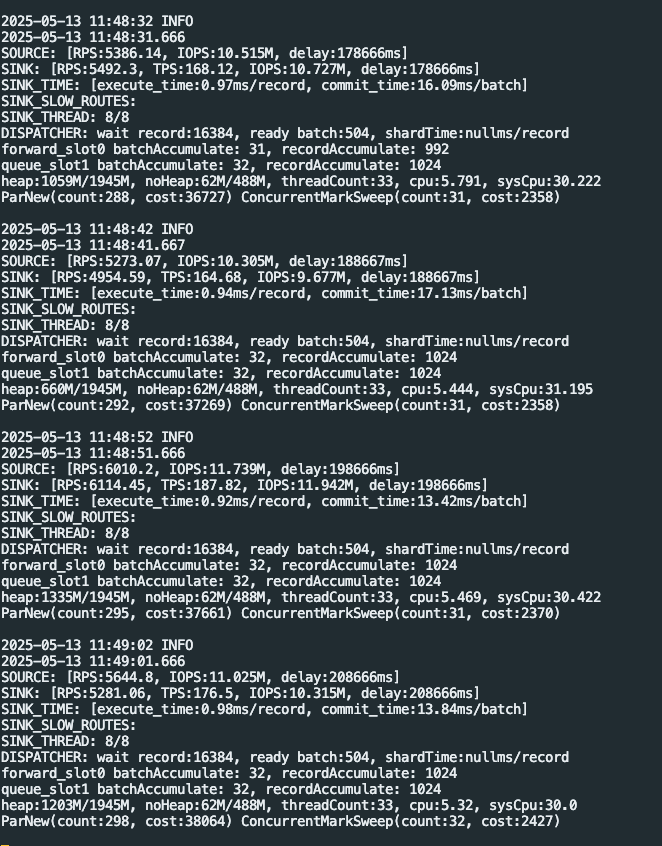
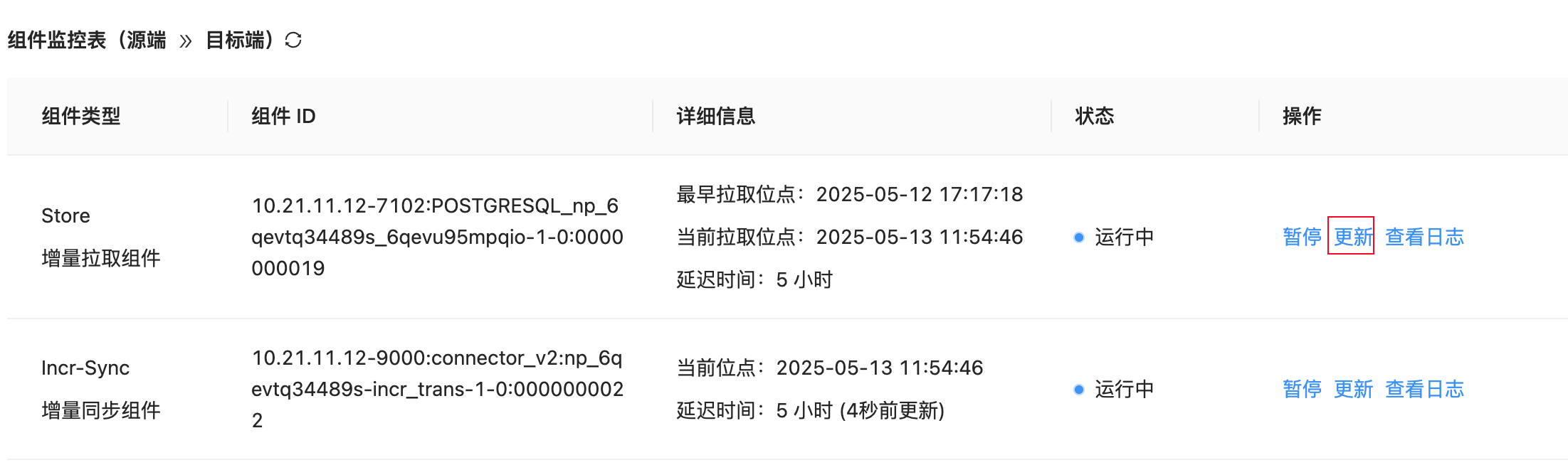
这是点更新后所有的配置内容,未发现关键字,sliceBatchSize 未找到,是直接添加到 source 里么?
workernum 有找到:
“root”:{
“condition”:{
“blackCondition”:
string"[{“all”:false,“sub”:[{“func”:“fn”,“name”:“drc_txn*”},{“func”:“fn”,“name”:“DRC_TXN*”},{“func”:“fn”,“name”:“delay_delete_"},{“func”:“fn”,“name”:"DELAY_DELETE_”}],“func”:“fn”,“name”:“public”,“map”:“er_nsh_payslip”}]"
“whiteCondition”:
string"[{“all”:false,“sub”:[{“name”:“payslip_template_style_rel”,“map”:“payslip_template_style_rel”},{“name”:“payslip_summary_config”,“map”:“payslip_summary_config”},{“name”:“payslip_template_config”,“map”:“payslip_template_config”},{“name”:“payslip_info_solution_batch_rel”,“map”:“payslip_info_solution_batch_rel”},{“name”:“payslip_template”,“map”:“payslip_template”},{“name”:“payslip_wage_item”,“map”:“payslip_wage_item”},{“name”:“payslip_template_config_solution_rel”,“map”:“payslip_template_config_solution_rel”},{“name”:“payslip_employee_info”,“map”:“payslip_employee_info”},{“name”:“payslip_info”,“map”:“payslip_info”},{“name”:“payslip_wage_group”,“map”:“payslip_wage_group”},{“name”:“payslip_wage_adapt_item”,“map”:“payslip_wage_adapt_item”},{“name”:“ob_person_bank_information”,“map”:“ob_person_bank_information”},{“name”:“ob_per_national_id”,“map”:“ob_per_national_id”},{“name”:“ob_payslip_employee_info_wage_item”,“map”:“ob_payslip_employee_info_wage_item”},{“name”:“ob_per_phone”,“map”:“ob_per_phone”},{“name”:“ob_per_personal”,“map”:“ob_per_personal”},{“name”:“ob_hr_employee”,“map”:“ob_hr_employee”},{“name”:“ob_per_person”,“map”:“ob_per_person”},{“name”:“ob_per_email”,“map”:“ob_per_email”},{“name”:“hr_department”,“map”:“hr_department”},{“name”:“hr_employee_eapp_external”,“map”:“hr_employee_eapp_external”},{“name”:“emp_job_eapp_external”,“map”:“emp_job_eapp_external”},{“name”:“emp_job”,“map”:“emp_job”}],“name”:“public”,“map”:“er_nsh_payslip”}]"
}
“coordinator”:{
“allowRecordTypes”:
string"DELETE,INSERT,UPDATE"
“connectorJvmParam”:
string"-Xms2048m -Xmx2048m -Xmn1024m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSClassUnloadingEnabled"
“enableActiveReportTask”:
boolfalse
“enableMetricReportTask”:
boolfalse
“enableOmsConnectorV2Report”:
booltrue
“sinkType”:
string"OB_MYSQL"
“sourceType”:
string"POSTGRESQL"
“taskIdentity”:
string"np_6qevtq34489s"
“timezone”:
string"+08:00"
}
“sink”:{
“boosterClass”:
string"com.oceanbase.oms.connector.jdbc.sink.obmysql.OBMySQLJDBCSinkBooster"
“charsetReplaceMap”:{}
“dbVersion”:
string"4.3.5.0"
“enableNoUniqueConstraintTableReplicate”:
booltrue
“endpointId”:
string"e_6j2o993zyjy8"
“ignoreRedunantColumnsReplicate”:
boolfalse
“insertMode”:
string"INSERT"
“isPreLoadAllTableSchema”:
boolfalse
“jar”:
string"jdbc-sink-ob-mysql.jar"
“jdbcUrl”:
string"jdbc:mysql://10.21.11.12:2883?useUnicode=true&allowMultiQueries=true&socketTimeout=50000&characterEncoding=utf8&readOnlyPropagatesToServer=false"
“password”:
string"******"
“timezone”:
string"+08:00"
“type”:
string"JDBC_SINK_OB_MYSQL"
“username”:
string"root"
“workerNum”:
int8
}
“source”:{
“boosterClass”:
string"com.oceanbase.oms.connector.source.store.MultiStoreSourceBooster"
“checkpoint”:{
“POSTGRESQL_np_6qevtq34489s_6qevu95mpqio-1-0”:
string"1747042038"
}
“clients”:[
0:{
“clientId”:
string"POSTGRESQL_np_6qevtq34489s_6qevu95mpqio-1-0"
“clusterManagerUrl”:
string"http://10.21.11.12:8088"
“subtopic”:
string"POSTGRESQL_np_6qevtq34489s_6qevu95mpqio-1-0"
}
]
“dbType”:
string"POSTGRESQL"
“dbVersion”:
float15.3
“ignoreDdl”:
booltrue
“jar”:
string"connector-source-store.jar"
“password”:
string"******"
“timezone”:
string"+08:00"
“type”:
string"STORE_SOURCE"
“username”:
string"RM_oms"
“workerNum”:
int8
}
}