

【 使用环境 】生产
【 OB or 其他组件 】
【 使用版本 】4.2.18
【问题描述】清晰明确描述问题
为何不同的查询值,会影响索引是否匹配呢?
ddl:
CREATE TABLE t_edm_xflow (
id bigint(20) NOT NULL AUTO_INCREMENT COMMENT ‘id’,
goods_id varchar(100) DEFAULT NULL COMMENT ‘商品id’,
promotion_code varchar(100) DEFAULT NULL COMMENT ‘引流位’,
order_no varchar(100) DEFAULT NULL COMMENT ‘订单号’,
uid varchar(100) DEFAULT NULL COMMENT ‘uid’,
experiment_code varchar(100) DEFAULT NULL COMMENT ‘实验组code’,
experiment_name varchar(100) DEFAULT NULL COMMENT ‘实验组名称’,
rule_code varchar(100) DEFAULT NULL COMMENT ‘rule_code’,
action varchar(100) DEFAULT NULL COMMENT ‘事件’,
creator varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL DEFAULT ‘SYSTEM’ COMMENT ‘创建者’,
modifier varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL DEFAULT ‘SYSTEM’ COMMENT ‘修改者’,
gmt_created datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ‘创建时间’,
gmt_modified datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ‘修改时间’,
is_deleted char(1) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL DEFAULT ‘N’ COMMENT ‘是否删除 Y:是 N:否’,
json text DEFAULT NULL COMMENT ‘消息体’,
action_time datetime DEFAULT NULL,
env varchar(100) DEFAULT NULL COMMENT ‘环境’,
pay_way varchar(100) DEFAULT NULL COMMENT ‘支付渠道’,
business_type int(11) DEFAULT NULL COMMENT ‘订单类型’,
uw_date datetime DEFAULT NULL,
pay_chain_id bigint(20) DEFAULT NULL COMMENT ‘支付链路id’,
pay_chain varchar(32) DEFAULT NULL COMMENT ‘支付链路’,
PRIMARY KEY (id),
KEY t_edm_xflow_goods_id_uw_date_IDX (goods_id, pay_chain, uw_date)
) AUTO_INCREMENT = 5931856 DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC;
情况1:
sql:explain select distinct uw_date from t_edm_xflow where goods_id=‘2019024’ and uw_date >=‘2025-04-01’ and uw_date <= ‘2025-04-30’ and pay_chain = ‘cashier_h’ and is_deleted=‘N’
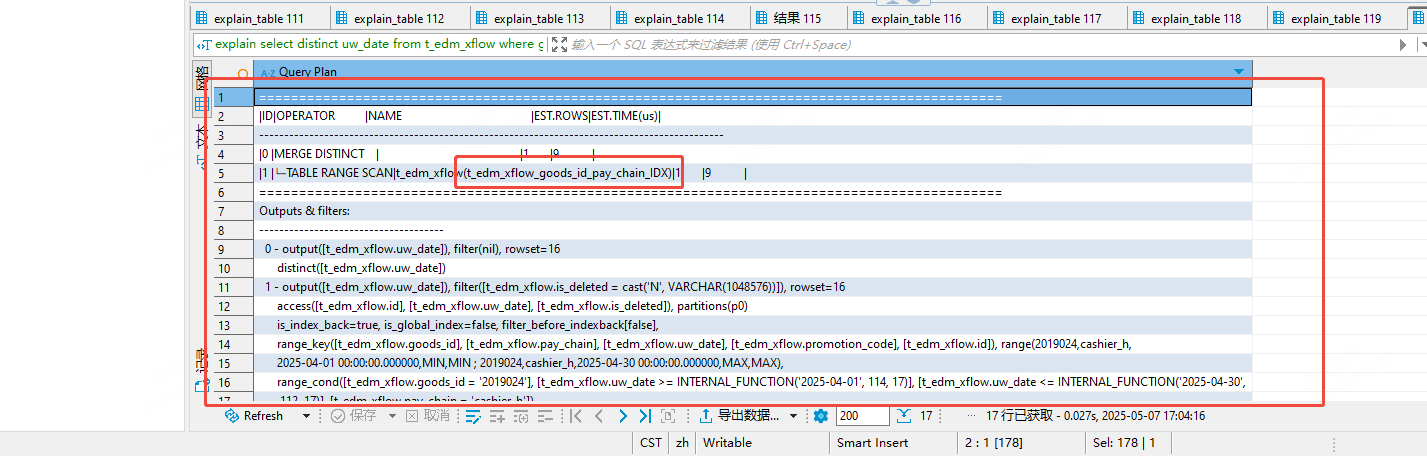
可见,使用了索引
情况2:
explain select distinct uw_date from t_edm_xflow where goods_id=‘2019024’ and uw_date >=‘2025-04-01’ and uw_date <= ‘2025-04-30’ and pay_chain = ‘cashier_h5’ and is_deleted=‘N’
返回:
|1 |└─TABLE FULL SCAN|t_edm_xflow|7118 |550245 |
可见,未使用索引。
情况1和情况2 唯一区别是pay_chain的值不同,请问pay_chain的值为何会影响索引的匹配呢?(表是有数据的,并且存在满足情况2pay_chain='cashier_h5’的数据,无情况1pay_chain='cashier_h’的数据)