【 使用环境 】生产环境
【 OB or 其他组件 】OB
【 使用版本 】4.2.1.7
【问题描述】truncate慢,非分区表,可以从那些方面排查
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
【 使用环境 】生产环境
【 OB or 其他组件 】OB
【 使用版本 】4.2.1.7
【问题描述】truncate慢,非分区表,可以从那些方面排查
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
根因分析场景: DDL过程中报磁盘空间不足的问题 (如果有疑问,可以先排查是否由于磁盘空间不足导致的缓慢)
根因分析命令: obdiag rca run --scene=ddl_disk_full
日志采集场景: 合并问题
日志采集命令: obdiag gather scene run --scene=observer.compaction
推荐使用 obdiag 工具进行根因分析和日志采集,并且将采集到的日志提供给我们以便确认问题所在。obdiag rca run --scene=ddl_disk_full 用于排查 TRUNCATE 操作中是否存在磁盘空间不足的问题,而 obdiag gather scene run --scene=observer.compaction 可以收集与合并相关的日志信息,因为 TRUNCATE 操作可能会触发底层的合并操作。
麻烦您提供一些信息以便我们更好地帮助您:(下面提出几个问题)
附上敏捷诊断工具 obdiag 使用帮助链接
deepseek生
truncate慢的问题,可以尝试升级到ob-4.2.1bp10及以上版本解决;
具体分析,可以看下truncate慢时集群的负载,io是否达到瓶颈,可以手动合并一次对比耗时有无变化。
再提供下集群架构和执行耗时
负载正常,只是truncate慢的表,每天会定时truncate然后在写入数据
根据您的描述,TRUNCATE 操作变慢可能与表的使用模式有关。以下是一些可能的原因和排查建议:
SELECT FOR UPDATE 或者其他 DML 操作),可能会导致 TRUNCATE 操作被阻塞。(G)V$OB_LOCK_WAIT 和 (G)V$OB_TRANSACTION 视图来检查是否有锁等待或者未提交的事务。SELECT * FROM gv$ob_lock_wait WHERE table_id = (SELECT object_id FROM oceanbase.__all_table WHERE table_name = 'your_table_name');
SELECT * FROM gv$ob_transaction WHERE status = 'ACTIVE';
TRUNCATE 操作可能会触发底层的合并操作(Minor Freeze 或 Major Freeze)。如果表的数据量较大,或者存在大量删除标记的数据,可能会导致合并操作耗时较长。(G)V$OB_MAJOR_COMPACTION 和 (G)V$OB_MINOR_COMPACTION 视图来检查是否有正在进行的合并操作。SELECT * FROM gv$ob_major_compaction WHERE tenant_id = (SELECT tenant_id FROM oceanbase.__all_tenant WHERE tenant_name = 'your_tenant_name');
SELECT * FROM gv$ob_minor_compaction WHERE tenant_id = (SELECT tenant_id FROM oceanbase.__all_tenant WHERE tenant_name = 'your_tenant_name');
如果该表每天都会被定时 TRUNCATE 并重新写入数据,可能会导致表的高水位(HWM)无法及时回收,从而影响后续的 TRUNCATE 操作。
优化建议:
freeze_trigger_percentage 和 minor_freeze_times,以加快合并速度。ALTER SYSTEM MAJOR FREEZE;
系统参数配置不当也可能导致 TRUNCATE 操作变慢。例如,cpu_quota_concurrency 参数设置过低,可能会限制可用线程的数量,从而影响操作性能。
排查方法:检查相关参数的配置。
SHOW PARAMETERS LIKE 'cpu_quota_concurrency';
TRUNCATE 操作。SELECT * FROM gv$ob_clog_stat;
CREATE OUTLINE 绑定 TRUNCATE 操作的执行计划,确保其每次都使用最优的路径。CREATE OUTLINE truncate_outline ON TRUNCATE TABLE your_table_name;
根据文档库中的信息,TRUNCATE 操作变慢可能与锁等待、合并操作、系统参数配置等因素有关。建议按照上述步骤逐一排查,并结合实际场景进行优化。如果问题仍未解决,可以提供更多的诊断信息(例如 obdiag 日志)以便进一步分析。
检索到的文档如下:
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
部分表的truncate慢还是所有的truncate慢,或者是整体ddl都慢,慢这个变化有具体出现的时间点吗或者变更点
只是truncate出现在慢SQL监控里, 这只是批量任务,其它业务没问题
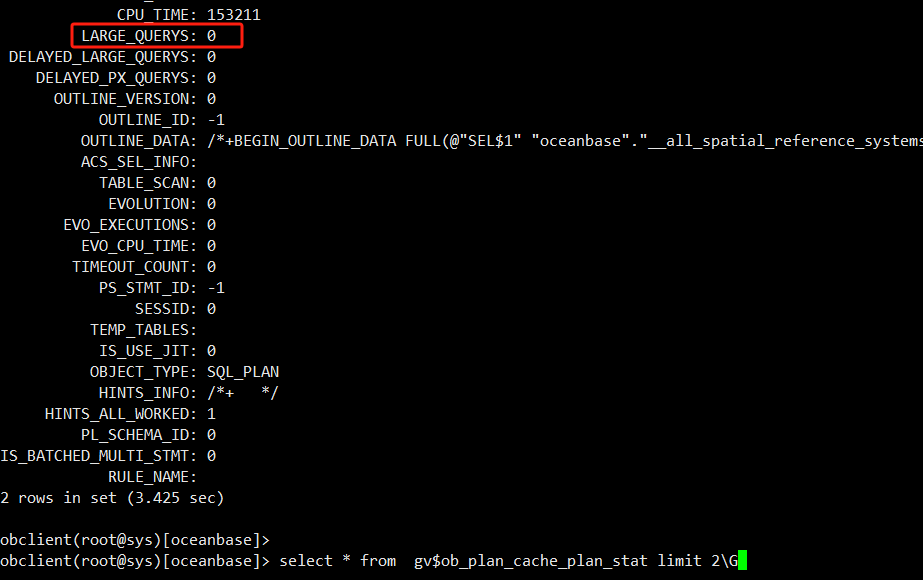
是不是进入 large查询了 。
trucate 慢 是否加并行了 。
truncate操作可以加并行的
没有,这些参数都没有调整,
尝试打开trace跟踪 。 或者ocp 里面能不能看到这个sql , 看看trace-id 看下 observer的日志里面有没有这个trace-id
SQL_AUDIT里面根据truncate 的语句找下对应的语句的trace_id,然后根据trace_id过滤一下RS的日志,提供一下RS的日志