

请问 为啥合并 会这么长时间
2 个赞
根据您提供的信息,合并时间较长可能与以下几个因素有关。以下内容综合了多个文档片段中的信息进行分析:
1. 合并的定义和过程
根据文档库中的信息(参考:OceanBase 数据库性能的影响因素 → 合并与统计信息收集 → 合并),合并操作是将动静态数据做归并,把当前大版本的 SSTable 和 MemTable 与前一个大版本的全量静态数据进行合并,产生新的全量数据。这个过程可能会非常耗时,尤其是在数据量较大的情况下。
2. 合并期间的操作
在合并过程中,OceanBase 数据库会对数据进行两层压缩:
- 第一层是数据库内部基于语义的编码压缩。
- 第二层是基于用户指定压缩算法的通用压缩(如 lz4)。
虽然压缩节省了存储空间并提升了查询性能,但也会增加 CPU 的负担,从而延长合并时间。
3. 自适应合并的影响
从 V4.1.0 版本开始,OceanBase 支持自适应合并(参考:自适应合并)。如果您的集群启用了自适应合并功能,系统会根据用户的查询、写入等信息动态调整合并任务的调度。这可能导致某些场景下的合并时间变长,尤其是当系统识别到需要优先处理其他高优先级任务时。
4. 租户数据量和复杂度
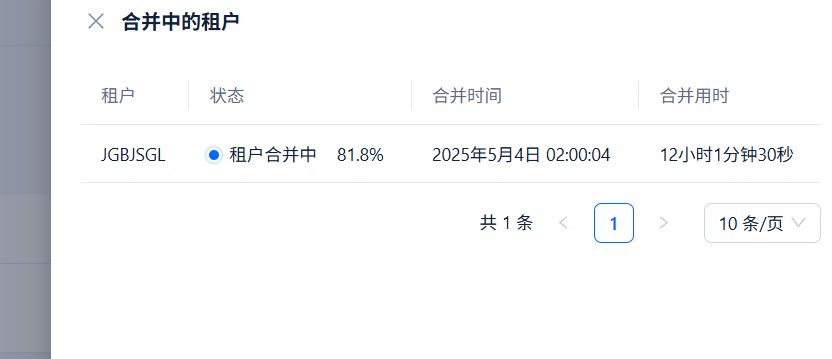
从您提供的图片信息来看,租户 JGBJSGL 的合并用时为 12 小时 1 分钟,且进度为 81.8%。这表明该租户的数据量较大或合并任务较为复杂。对于大规模数据集,合并时间自然会更长。
5. 硬件资源限制
如果服务器的硬件资源(如 CPU、内存、磁盘 I/O 等)不足,也可能导致合并时间延长。例如:
- 如果 CPU 资源被其他任务占用,合并任务的执行速度会变慢。
- 如果磁盘 I/O 性能较差,读取和写入数据的速度受限,也会拖慢合并进程。
6. 手动控制合并
如果您希望缩短合并时间,可以尝试手动控制合并(参考:手动控制合并)。例如:
- 使用
MAJOR FREEZE命令触发合并。 - 如果在合并过程中出现错误(如 Checksum 校验出错),可以暂停当前合并 (
suspend merge),修复问题后清理错误标记 (clear merge error),再继续执行合并 (resume merge)。
7. 优化建议
为了减少合并时间,您可以考虑以下措施:
- 调整合并策略:确保自适应合并功能开启,并检查其是否正确调度了合并任务。
- 优化硬件资源:确保服务器有足够的 CPU、内存和磁盘 I/O 资源。
-
设置合理的参数:通过调整相关参数(如
ob_sql_work_area_percentage、parallel_servers_target等)来优化合并性能。
示例代码
以下是一些可能有助于优化合并的 SQL 参数设置示例(参考:OceanBase 数据库性能的影响因素 → 数据库参数调优 → OLAP 场景):
-- 设置 SQL 工作区内存占整个租户内存百分比
SET GLOBAL ob_sql_work_area_percentage = 80;
-- 设置事务超时时间
SET GLOBAL ob_trx_timeout = 36000000000;
-- 设置最大网络包的大小
SET GLOBAL max_allowed_packet = 67108864;
-- 租户在每个节点上可申请的并行执行线程数量
SET GLOBAL parallel_servers_target = 624;
总结
根据文档库中的信息,合并时间较长的原因可能包括数据量大、硬件资源不足、自适应合并策略的影响等。建议您结合实际场景,优化硬件资源配置或调整合并策略以缩短合并时间。如果问题仍未解决,建议联系 OceanBase 技术支持团队获取进一步帮助。
详情请参考:
7 个赞
有结果了不
4 个赞
同时,查询一下__all_zone 视图,看看在哪一个zone 的ob server 卡住了,查看一下卡的类型等等
3 个赞
建议也说一下租户的资源规格、数据量、磁盘类型等信息。
4 个赞
![]()
![]()
![]()
![]()
1 个赞
有解决方案之后记得分享出来,我也跟着涨一涨见识啊,谢谢啦
SELECT * FROM oceanbase.GV$OB_TABLET_COMPACTION_PROGRESS;
分析写这个表
- 看看是那个tablet合并有问题
- 从server的角度看看是不是 server的整个tablet都有问题
1 个赞