

小编曾经照猫画虎,用向量数据库、嵌入模型、LLM、前端 UI 等几个组件,“拼装” 过一个简易的 Text2SQL 小工具,但只知其然,不知其所以然。
前两天参加了一个 OB develop-tools 开发者共建月会。在这个会议上,菁甜为参会者分享了 Text2SQL 的技术原理解析,虽然整个 Text2SQL 的构建流程只有短短五个步骤,但听完感觉受益颇多,于是便将她在会议上分享的内容在这里分享给大家。
希望大家都能通过这篇小短文快速了解 Text2SQL 的实现原理。
前言
在数据检索的世界里,你是否曾为如何精准、高效地获取所需信息而苦恼?当面对海量的数据库,是不是感觉像是在迷雾中摸索,期待着一个“魔法棒”能帮你一键直达?别急,OBCloud 的 Text2SQL 功能就是你期待的“魔法棒”!开发者不用再逐字解释表关系,业务人员不需要成为SQL十级学者,DBA也不必夜夜被"这个字段为什么查不到"的电话惊醒。
本文将深入解密这场「自然语言到SQL语言」的奇幻之旅。前半程我们将手把手体验"对话即查询"的产品魔法,后半程将穿越技术虫洞,一睹大模型与分布式数据库如何共舞,揭秘 Text2SQL 是如何化身为「SQL翻译官」,让人类用日常语言提问,就能获得精准的数据库问答。
功能体验
在本章中,我们将通过详细的步骤演示,带您亲身体验 OBCloud Text2SQL 的功能使用过程。
登录 OBCloud官网,注册账号后您可以免费购买一个「共享实例」,购买成功后在「实例列表」页面点击「数据开发」:

基于该实例创建一个新的「工作空间」,创建完毕后点击「开始开发」:

进入「工作空间」后,在SQL窗口仅需根据注释内容或者 AI 输入框( Ctrl/Cmd + K 快速唤起)您就能够唤起 Text2SQL 功能,将自然语言文本转化为结构化查询语言。这里我们采用 Spider 数据集作为测试数据集:
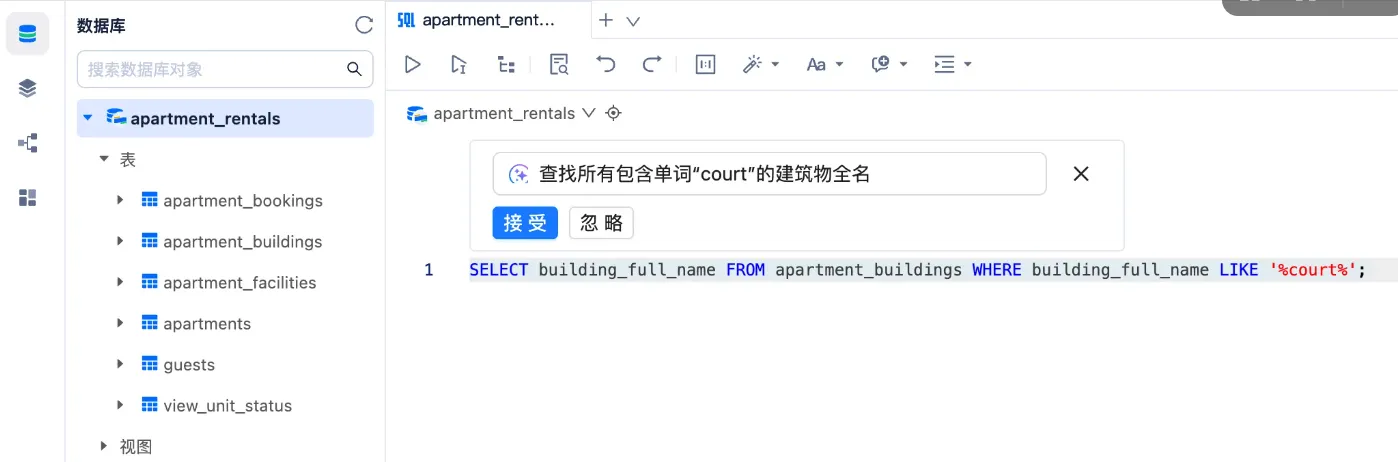
可以看到根据我们的中文输入已经成功生成了正确的SQL查询语言。
此外还支持 SQL智能修改/优化/纠错功能,选中 SQL 语句并单击鼠标右键:
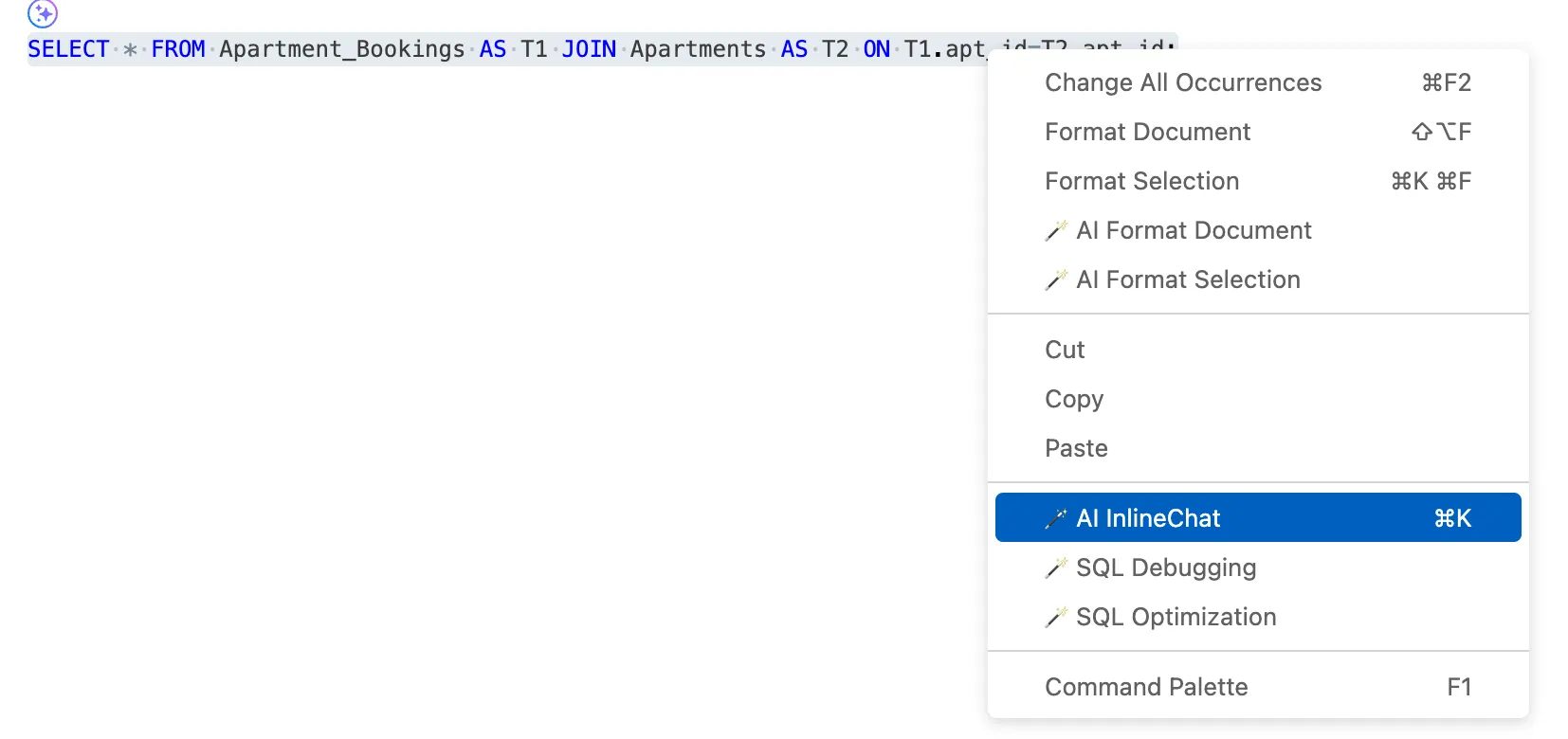
通过本节实操可以看出:OBCloud 的 Text2SQL 并非简单的关键词替换工具,而是基于用户业务数据库设计的AI智能化SQL生成器。
核心技术解读
本章节将深入剖析 Text2SQL 实现方案的底层技术架构与实现原理。
用户在给出查询语句时,往往只会给出自己想要查询的字段与条件,比如“查询所有年龄在24岁以上的NBA球员”,而如果仅仅把用户原始的 Query 输入给大模型,是无法生成准确的查询SQL的,因为大模型并不知道“有哪些表可以给我查询呢”。
RAG(检索增强生成)是一种优化大型语言模型(LLM)输出的方法,Text2SQL 的实现就是基于RAG技术,根据用户的 Query 内容,从用户业务库中查询与 Query 有关的表DDL信息,然后将检索到表DDL一起嵌入到预设的Prompt模板中,将 Prompt 和用户的 Query 输入到 LLM 中,以生成最终的 SQL。这种动态的元数据增强机制,有效解决了模型无法自主感知物理表结构的根本性障碍。
整体流程为AI元数据准备(构建向量和 K-V 索引)、Query 信息抽取、表和样例召回、SQL生成。整体的流程图如下:
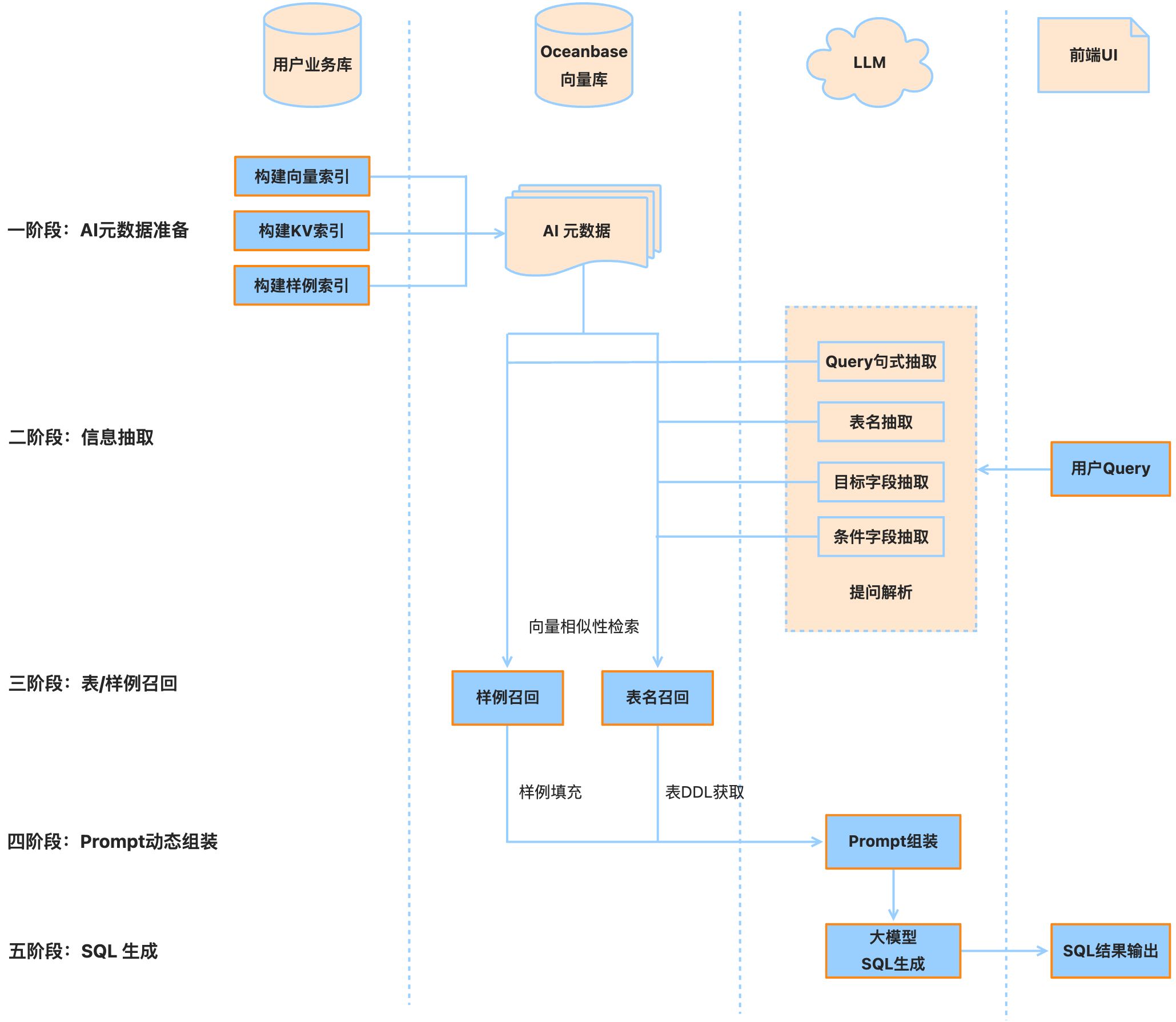
第一步,元数据索引构建 。基于用户的业务库准备AI原数据,通过将数据库中的表结构、字段说明、约束关系等元数据经过 Vector Embedding 模型进行向量化处理,构建高效的语义检索体系,包括向量索引和 KV 索引。它们将被用来辅助后续的表召回过程。
第二步,信息提取 。通过语言大模型对用户输入 Query 进行信息提取,提取的内容主要包括 Query 句式(骨架)抽取、目标字段抽取、条件字段抽取、表名抽取。
第三步,表和样例召回 。将目标字段、条件字段、表名的抽取内容通过文本模型向量化后,基于第一步中准备的AI 向量数据库进行向量相似性检索,结合表召回策略以及排序规则,得到召回的表名信息,以获得 Query 中涉及的所有表 DDL 信息。同时,将 Query句式(骨架)抽取的内容通过文本模型向量化,与样例向量库数据集进行逐一相似度比对,结合样例召回策略,获取最终填充 Prompt 模版的样例。
第四步,Prompt 动态组装 。将步骤三四中得到的表DDL信息、样例信息按照模版进行 Prompt 生成组装。
第五步,SQL生成与输出 。将第四步中得到的 Prompt 和用户原始的 Query 一起输入给大模型进行 SQL 语句生成,并将生成的 SQL 语句返回给用户,完成一次问答的流程闭环。
元数据库索引构建
对于传统数据库,搜索功能都是基于不同的索引方式加上精确匹配和排序算法等实现的。本质还是基于文本的精确匹配,这种索引和搜索算法对于关键字的搜索功能非常合适,但对于语义搜索功能就非常弱。
以动物检索场景为例:当用户输入关键词"小猫"时,系统仅能返回含该字面表述的结果,而无法智能关联"银渐层"、"布偶"等细分猫种信息。因为传统数据架构无法解析词汇间的语义关联,必须依赖人工建立特征标签体系实现概念连接。在处理非结构化数据(如图像、音频、视频)时,这种人工标注模式的局限性更为显著——多媒体数据的特征维度呈指数级增长,人工构建标签体系将面临巨大挑战。
针对这一瓶颈,基于AI模型的向量嵌入(Vector Embedding)技术提供了创新解决方案。以 OpenAI 的 text-embedding-ada-002模型为例,该模型可将文本(如"Your text string goes here")编码为1536维特征向量,每个维度表征数据的不同语义特征。通过将这些高维向量存储到向量数据库,即可在底层实现语义相近度的自动识别,突破传统字符匹配的局限。因此我们可以将它存入Oceanbase向量数据库中,以便我们后续进行语义搜索。
在Text2SQL应用场景中,我们可基于用户的业务数据库的元数据构建智能化检索系统:通过提取表名、字段名、注释等关键信息的向量化特征表示,建立支持高效语义检索的特征索引系统,为后续的表/样例召回提供智能化的检索支撑。这些数据包括:
- 构建向量索引:表名、字段名、注释等利用Text-Embedding大模型进行文本 Embedding 处理得到向量化的数据后存储在 Oceanbase 向量数据库中。
- 构建关键词索引:将表DDL、字段名、表/字段注释和表名的关联以KV对的形式存入KV存储中。
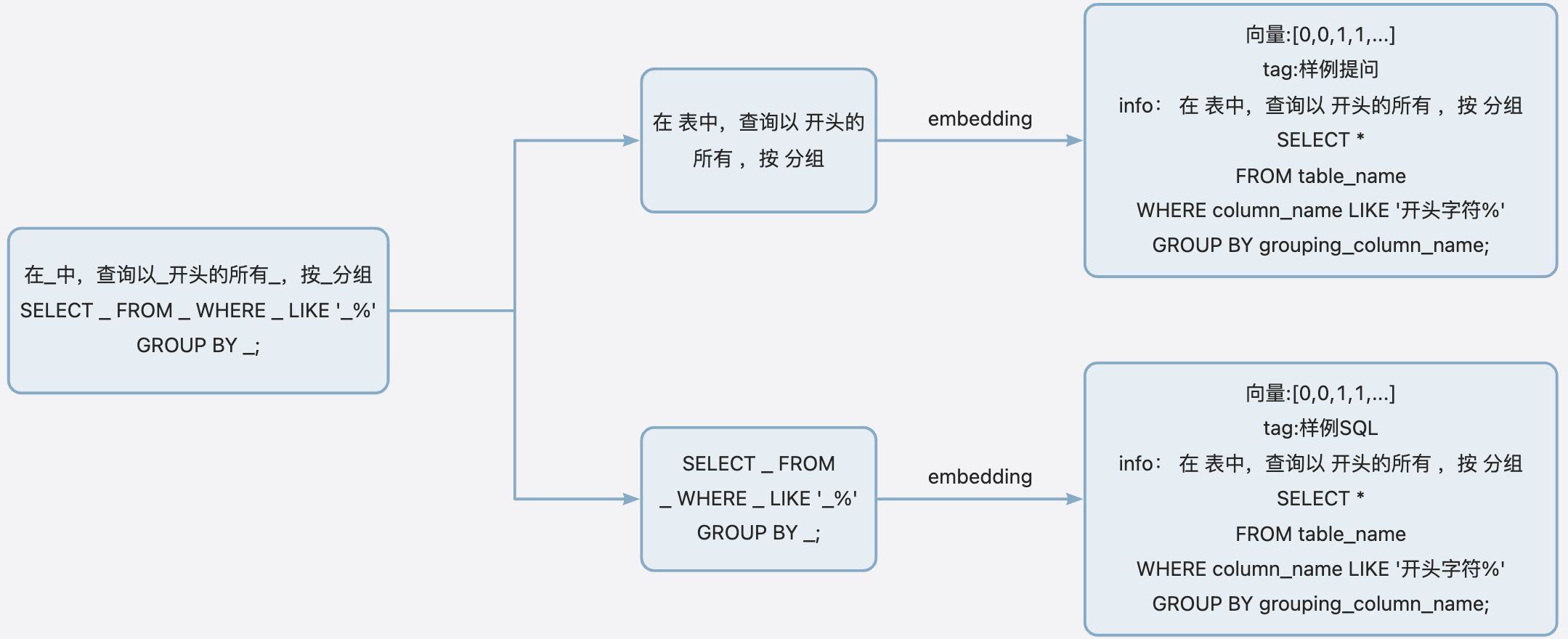
- 构建样例索引:为样例集构建向量索引,如下图所示:
信息抽取
信息抽取的核心目标是通过大语言模型对用户提问内容进行结构化提取。抽取的信息需要包括目标检索字段信息、目标条件字段信息、目标检索表名信息、句式语义信息这四部分内容:
- 目标检索字段信息 。对应数据库查询语句的 SELECT 部分,指用户希望获取的数据列。
- 目标条件字段信息 。限定数据范围的约束表达式,关联 WHERE 子句中的逻辑判断。包含条件对象(字段)与判断内容(值/范围),当用户未明确限制条件时该部分可为空值。
- 目标检索表名信息 。数据库表的描述信息抽取,但考虑到在用户Query中用户不一定知道自己想要的信息在哪张表中,故如果客户指定表信息的话则抽取出来,如果没有指定也支持暂不抽取。
- 骨架信息 。通俗描述就是整个Query中除字段信息之外的骨架信息,从句式信息中我们可以提炼出对应的SQL语句大致的样式,为后续样例召回做准备。
我们设计了如下的信息抽取 Prompt,以 Few-shot 的方式让模大型进行抽取:
## 角色
你是一个信息抽取专家,请根据用户提供的信息,参考以下3个样例,一步步思考并抽取出可用于编写SQL查询语句的字段与表名和用户问题的骨干信息,并将结果以json格式给出,必须包含columnNames、tableNames、questionSkeleton字段。
## 样例1
<user>: 查询满足7位商品编码以657为开头的所有7位商品编码、日分区,按7位商品编码、日分区分组。
<assistant>: {"columnNames": ["商品编码", "日分区"], "tableNames": [], "questionSkeleton": "查询满足_以_为开头的所有_、_,按_、_分组"}
## 样例2
<user>: 查询满足纳税人数据id为021的所有销项纳税人户数、收取外省专用发票金额占比,收取外省专用发票金额,限制返回10条。
<assistant>: {"columnNames": ["纳税人数据id", "销项纳税人户数", "收取外省专用发票金额占比", "收取外省专用发票金额"], "tableNames": [], "questionSkeleton": "查询满足_以_为结尾的所有_、_、_,限制返回_条"}
## 样例3
<user>: 查询所有学生中年龄大于10岁的学生名字。
<assistant>: {"columnNames": ["年龄", "学生名字"], "tableNames": ["学生"], "questionSkeleton": "查询所有_中_大于_的_"}
## 约束条件
1. 请注意,若未明确给出表名,输出的 tableNames 应为 []。
2. 结果以json格式给出,必须包含columnNames、tableNames、questionSkeleton字段
3. 请严格按照格式输出,不要给出SQL语句。
表/样例召回
该阶段,我们可以并行地执行 表召回与样例召回 两个流程,它们均依赖于信息抽取阶段的抽取结果。
表召回,即为通过上一阶段信息抽取所获得的字段和表名信息召回满足用户查询条件的表名 ——该部分为整个链路的关键,表名若是召回错误,那么SQL的正确率也会大幅度下降。
样例召回,即为通过上一阶段信息抽取所获得的骨架信息召回与用户查询的最相似的样例 ,以帮助大模型更好地生成针对当前查询的SQL查询语句。
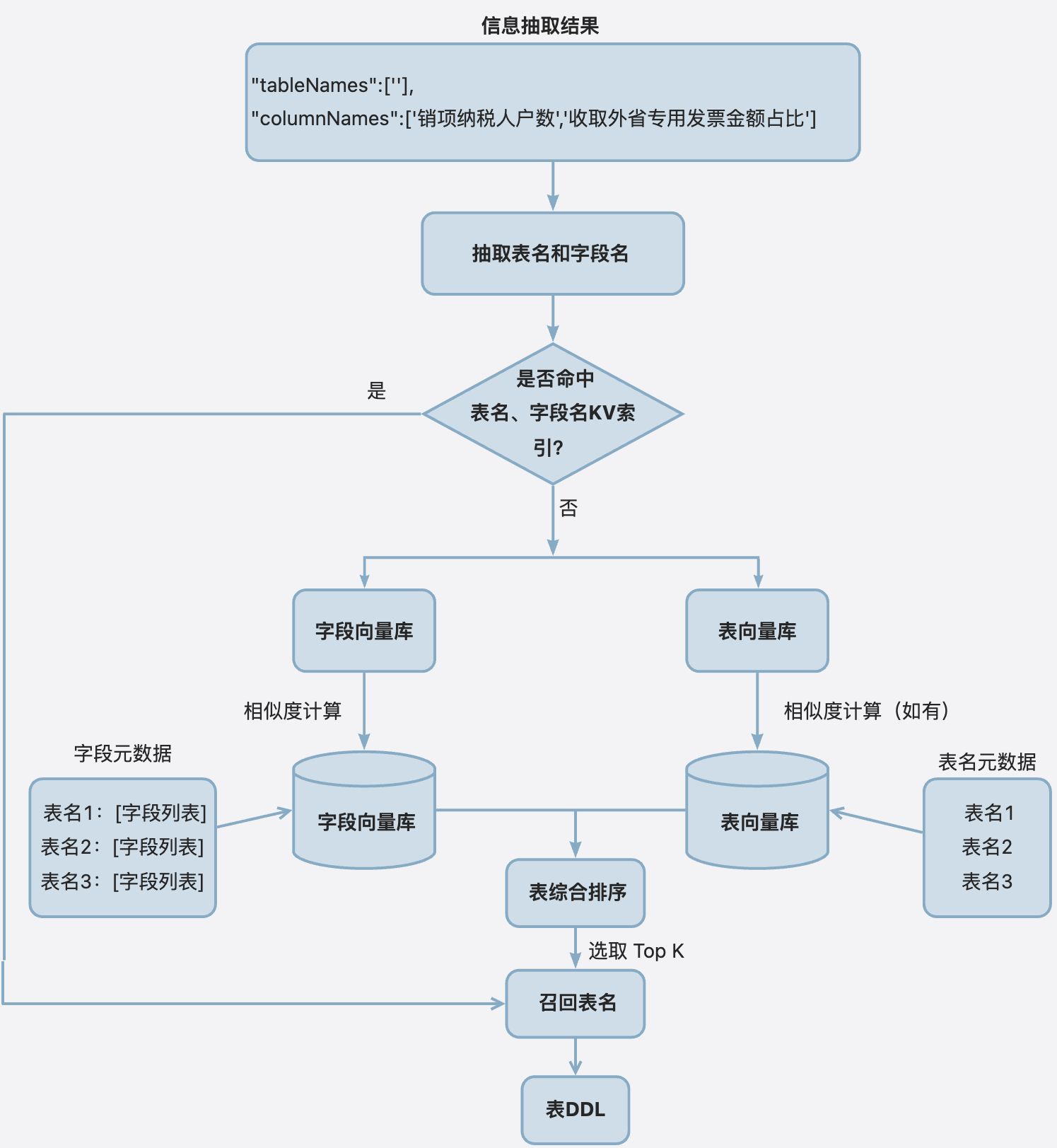
表召回
将「信息抽取」阶段获取的表名、字段等信息在「AI 元数据库」中进行 K-V 检索 和 向量相似性检索 ,最终得到 Query 关联的表 DDL,整体流程如下:
样例召回
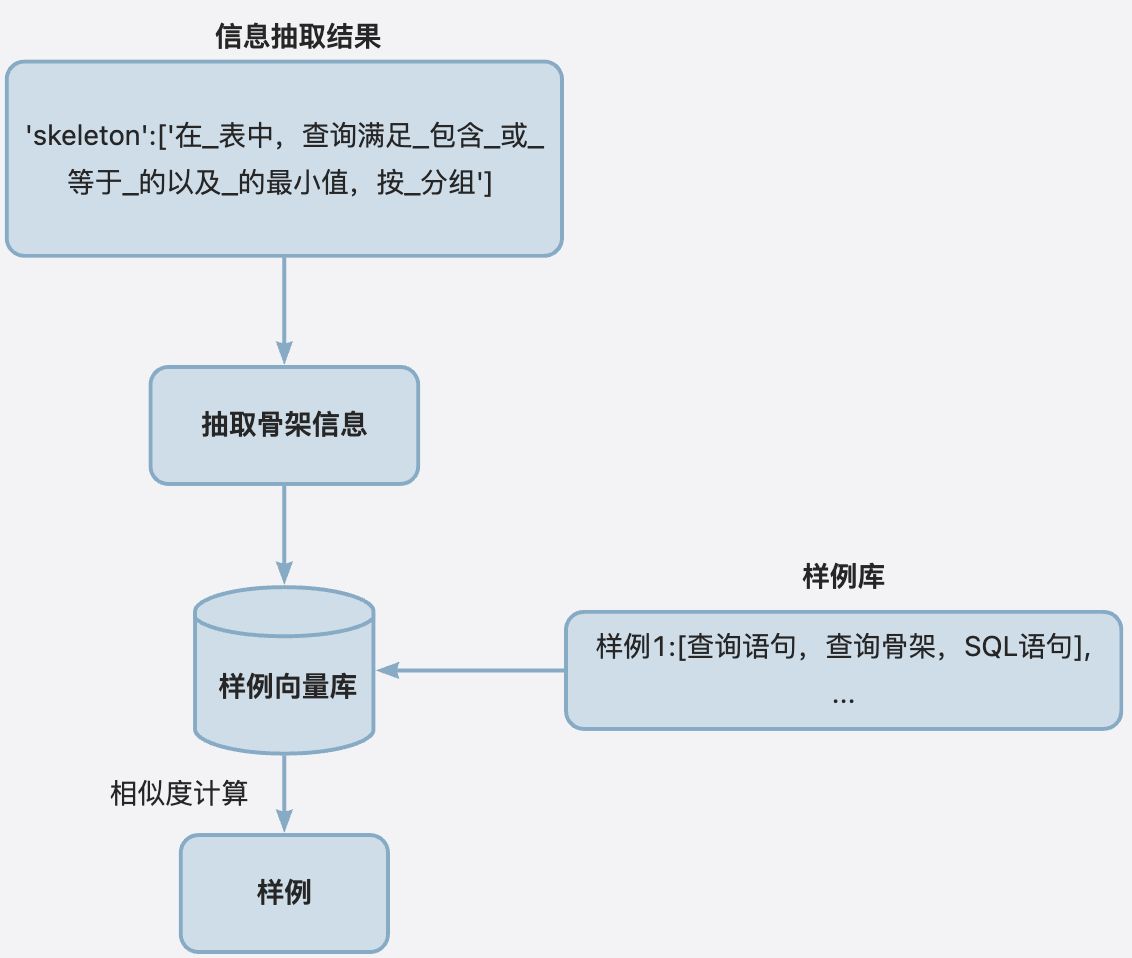
在 Text2SQL 的过程中,样例召回的目的就是在大模型的 Prompt 中,尽可能给大模型提供与用户Query 相类似的参考样例,样例中包含所提问题以及应该输出 SQL 的标准答案,样例问题与实际Query 问题越接近,那么大模型生成的SQL准确率就会越高。
整体样例召回流程图如下所示:
SQL生成
我们将以上步骤中得到的与Query 相关的表DDL信息、样例信息按照模版进行 Prompt 生成组装,最后将 Prompt 和用户原始的 Query 一起输入给大模型进行 SQL 语句生成,并将生成的SQL语句返回给用户,完成一次问答的流程闭环。
预设的Prompt模版如下:
## 角色
你是一位SQL专家,擅长编写SQL查询语句。请根据用户输入与表结构信息以及样例编写SQL查询语句,请仅返回一条可执行的SQL语句,不需要任何解释或额外的文字内容。
## 已知表结构信息
{0}
## 样例
{1}
## 约束条件
1. 你的输出应该为一段可执行的SQL,这段SQL语句需要遵守{2}语法。
2. 不要解释你输出的SQL语句。
4. 如果你有说明请通过单行注释--给出。
5. 如果输出 DROP/TRUNCATE/DELETE 等高危 SQL 语句时,请在生成的 SQL 语句中通过 SQL 注释提示风险。
结语
本文全景式展现了 OBCloud Text2SQL 如何架起自然语言与数据库的智能桥梁——通过大模型语义解析架构与 Oceanbase 分布式向量数据库的深度融合,让非技术人员无需跨越SQL语法鸿沟即可实现精准数据检索。这场变革的价值不仅在于提升检索效率,更在于重新定义了人机协作的范式:数据库从被动响应的工具,转变为能解读业务场景的智能伙伴。
当 Text2SQL 的星火点燃整个数据领域,我们正见证一个新时代的序幕:未来的数据库将不再满足于"执行指令",而是向着"理解业务意图-预判需求-动态优化"的智能生命体进化。这或许标志着「人机协作」范式的终极转向——从此,数据世界的交互语言,终将以人类最本能的方式存在。
