

测试环境
obd oceanBase
4.3.5
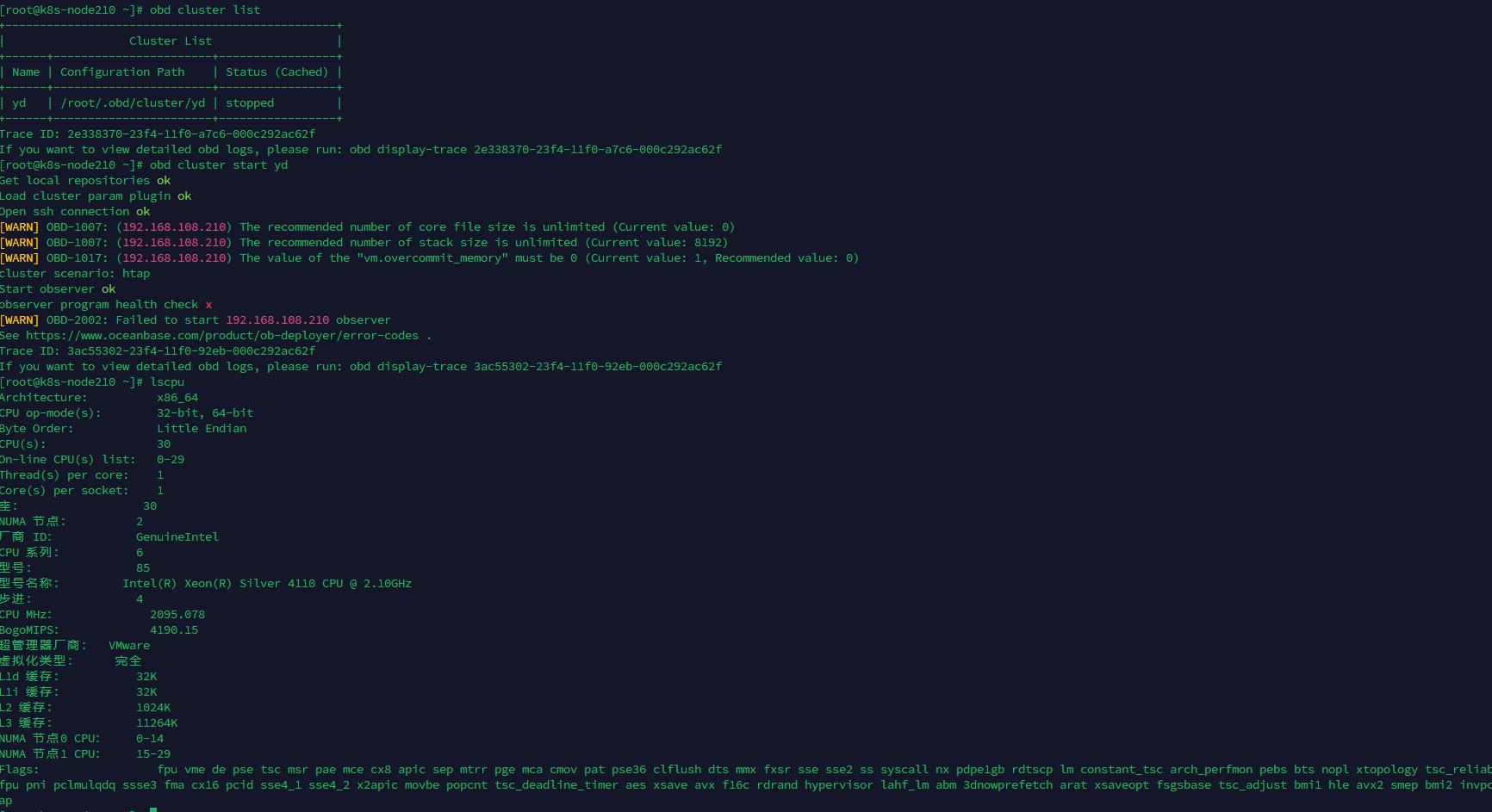
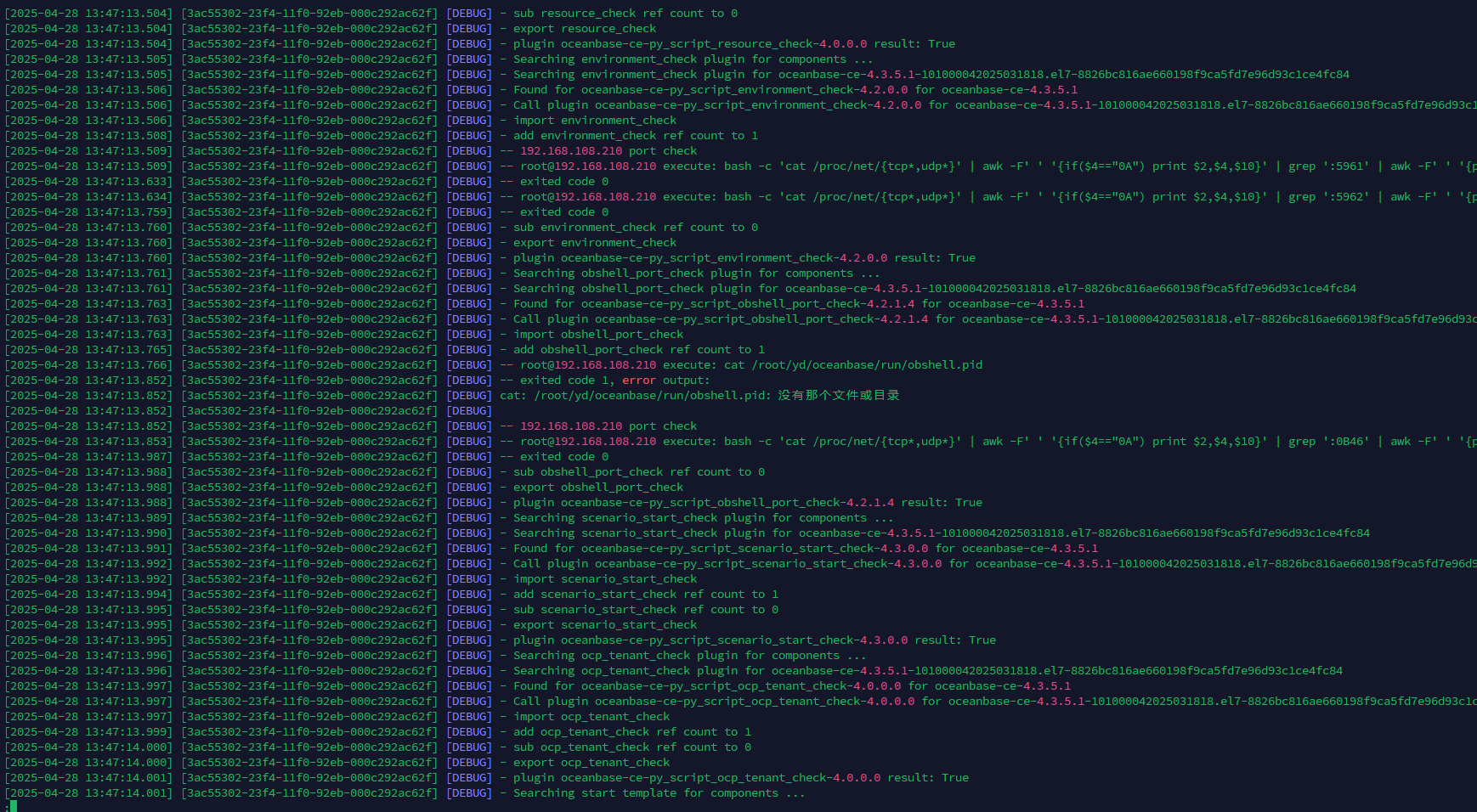
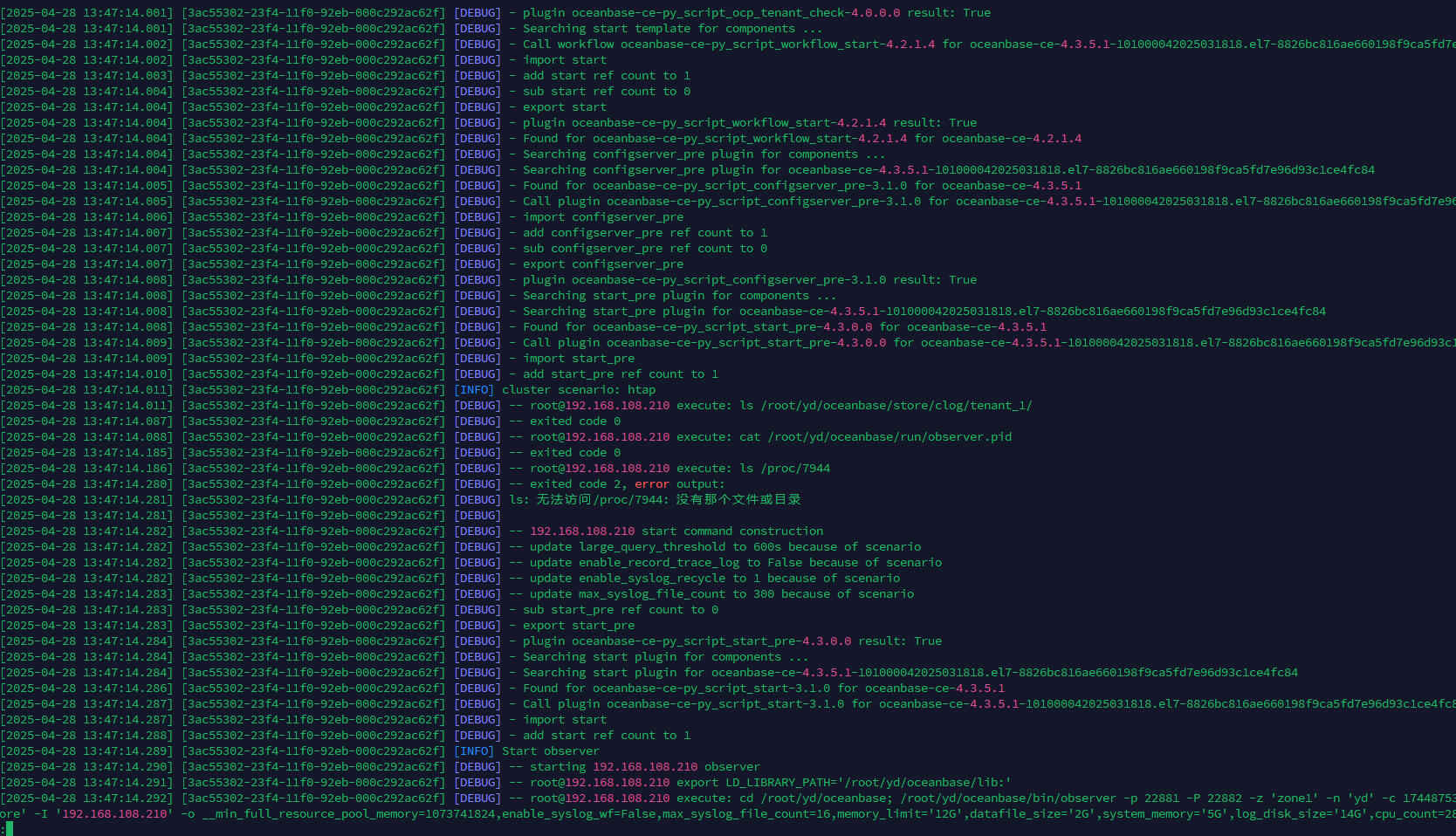
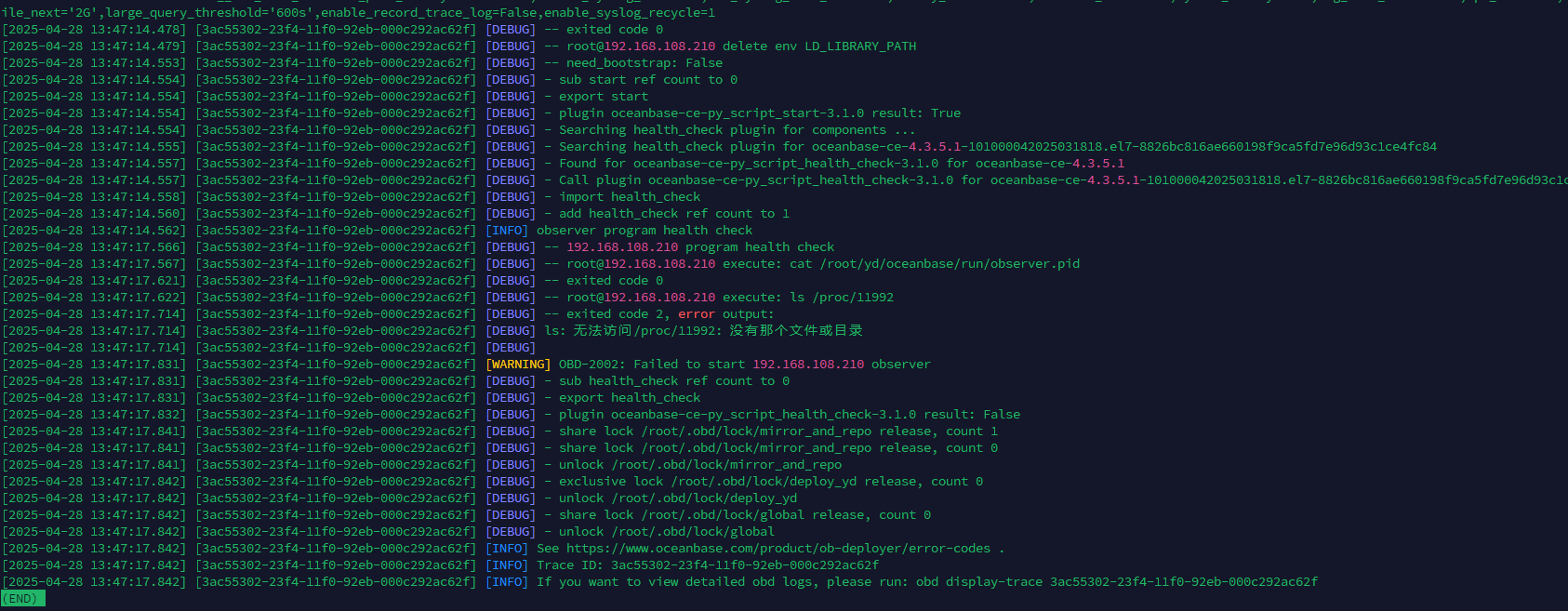
使用obd cluster stop yd停止集群后,再执行obd cluster start yd命令启动集群失败
[root@k8s-node210 log]# grep ERROR observer.log
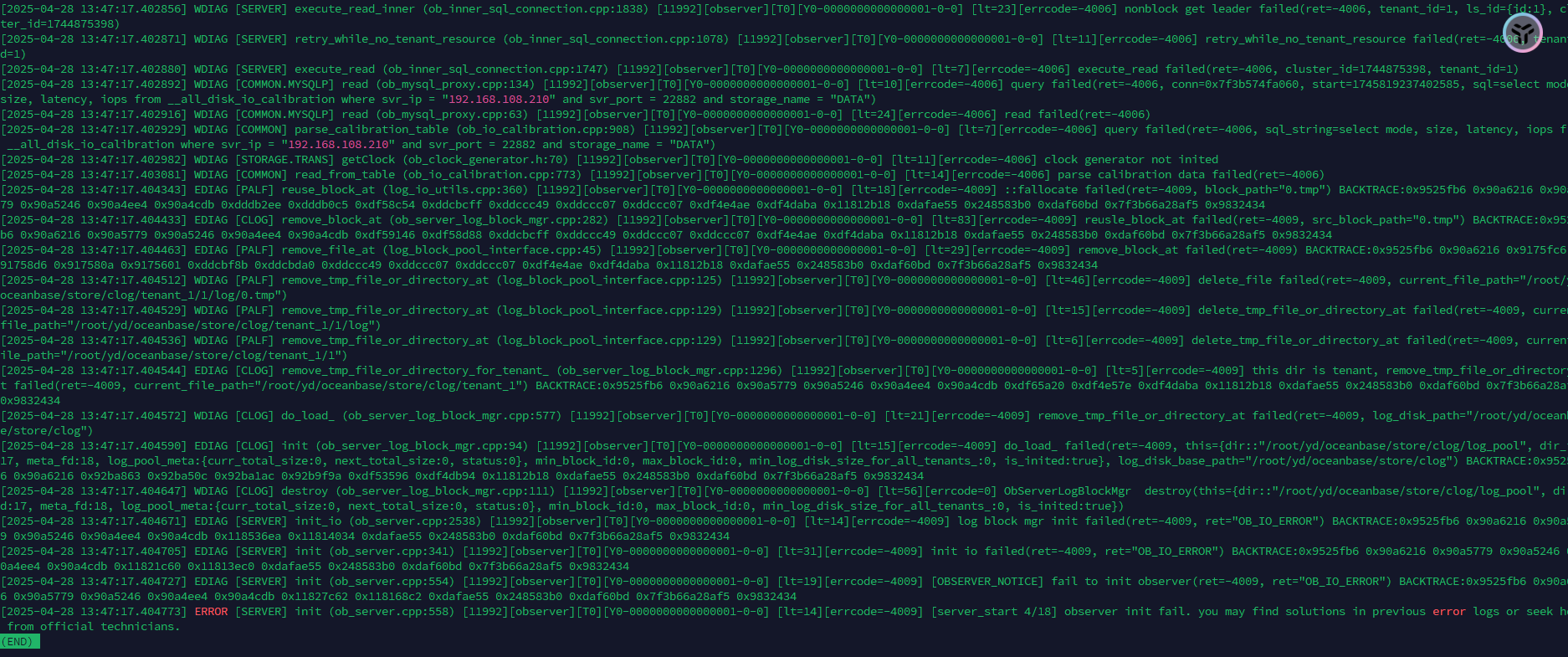
[2025-04-28 13:23:36.499904] EDIAG [SERVER] init_io (ob_server.cpp:2538) [6983][observer][T0][Y0-0000000000000001-0-0] [lt=12][errcode=-4009] log block mgr init failed(ret=-4009, ret=“OB_IO_ERROR”) BACKTRACE:0x9525fb6 0x90a6216 0x90a5779 0x90a5246 0x90a4ee4 0x90a4cdb 0x118536ea 0x11814034 0xdafae55 0x248583b0 0xdaf60bd 0x7fc663a7eaf5 0x9832434
[2025-04-28 13:23:36.499936] EDIAG [SERVER] init (ob_server.cpp:341) [6983][observer][T0][Y0-0000000000000001-0-0] [lt=29][errcode=-4009] init io failed(ret=-4009, ret=“OB_IO_ERROR”) BACKTRACE:0x9525fb6 0x90a6216 0x90a5779 0x90a5246 0x90a4ee4 0x90a4cdb 0x11821c60 0x11813ec0 0xdafae55 0x248583b0 0xdaf60bd 0x7fc663a7eaf5 0x9832434
[2025-04-28 13:23:36.499956] EDIAG [SERVER] init (ob_server.cpp:554) [6983][observer][T0][Y0-0000000000000001-0-0] [lt=17][errcode=-4009] [OBSERVER_NOTICE] fail to init observer(ret=-4009, ret=“OB_IO_ERROR”) BACKTRACE:0x9525fb6 0x90a6216 0x90a5779 0x90a5246 0x90a4ee4 0x90a4cdb 0x11827c62 0x118168c2 0xdafae55 0x248583b0 0xdaf60bd 0x7fc663a7eaf5 0x9832434
[2025-04-28 13:23:36.500004] ERROR [SERVER] init (ob_server.cpp:558) [6983][observer][T0][Y0-0000000000000001-0-0] [lt=17][errcode=-4009] [server_start 4/18] observer init fail. you may find solutions in previous error logs or seek help from official technicians.
lscpu看下是否支持avx,或者把启动日志发出来看下
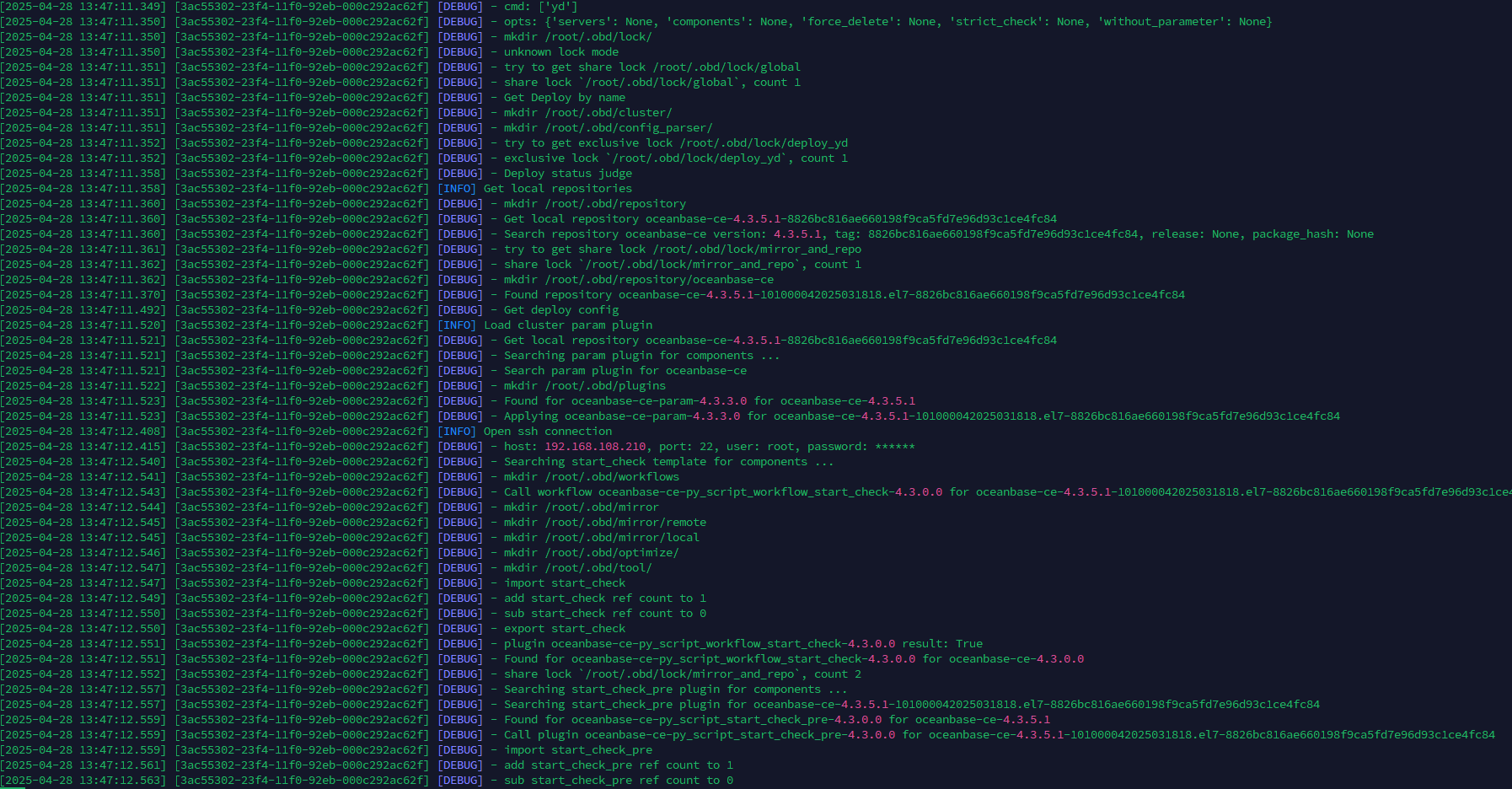
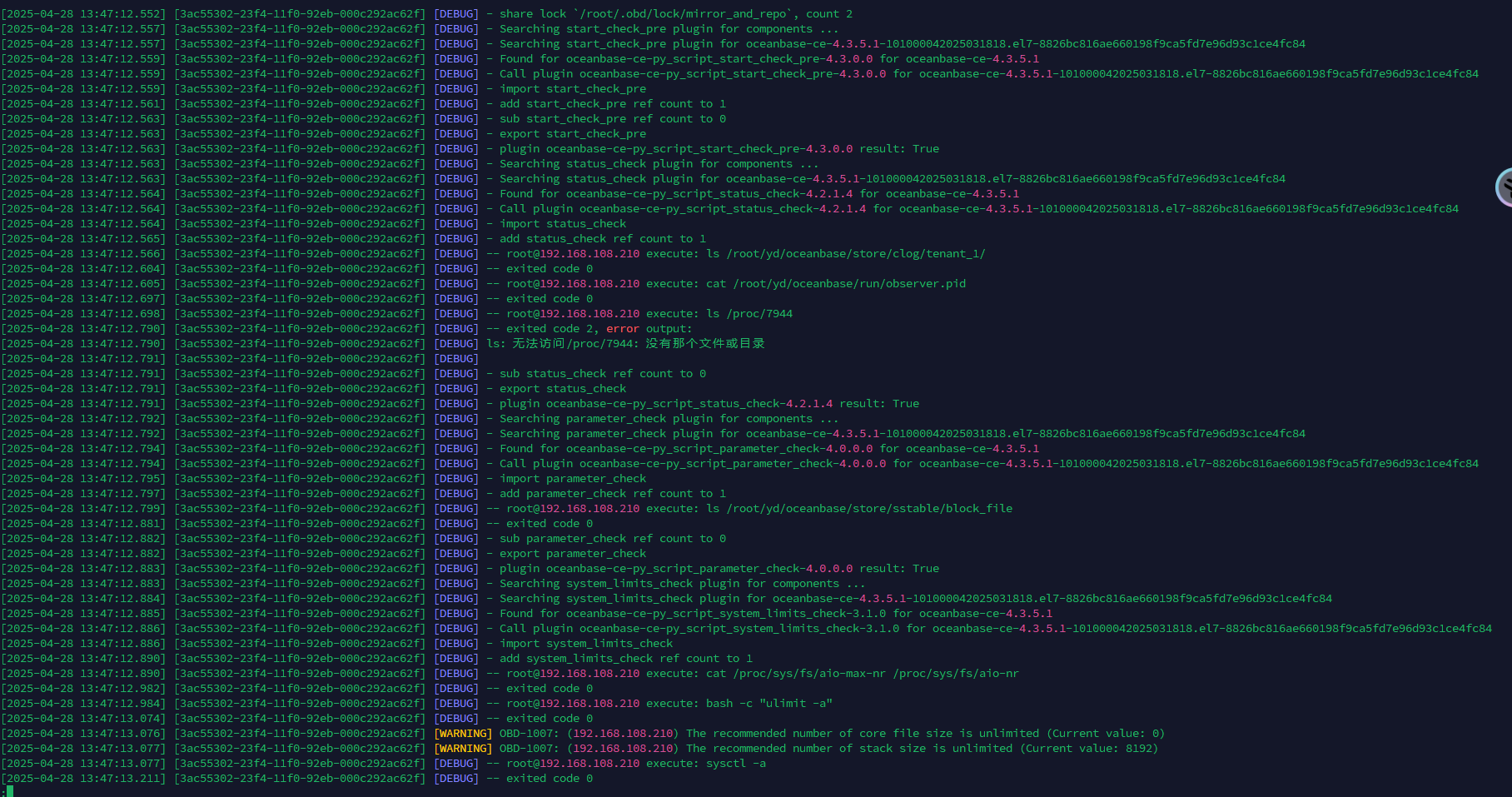
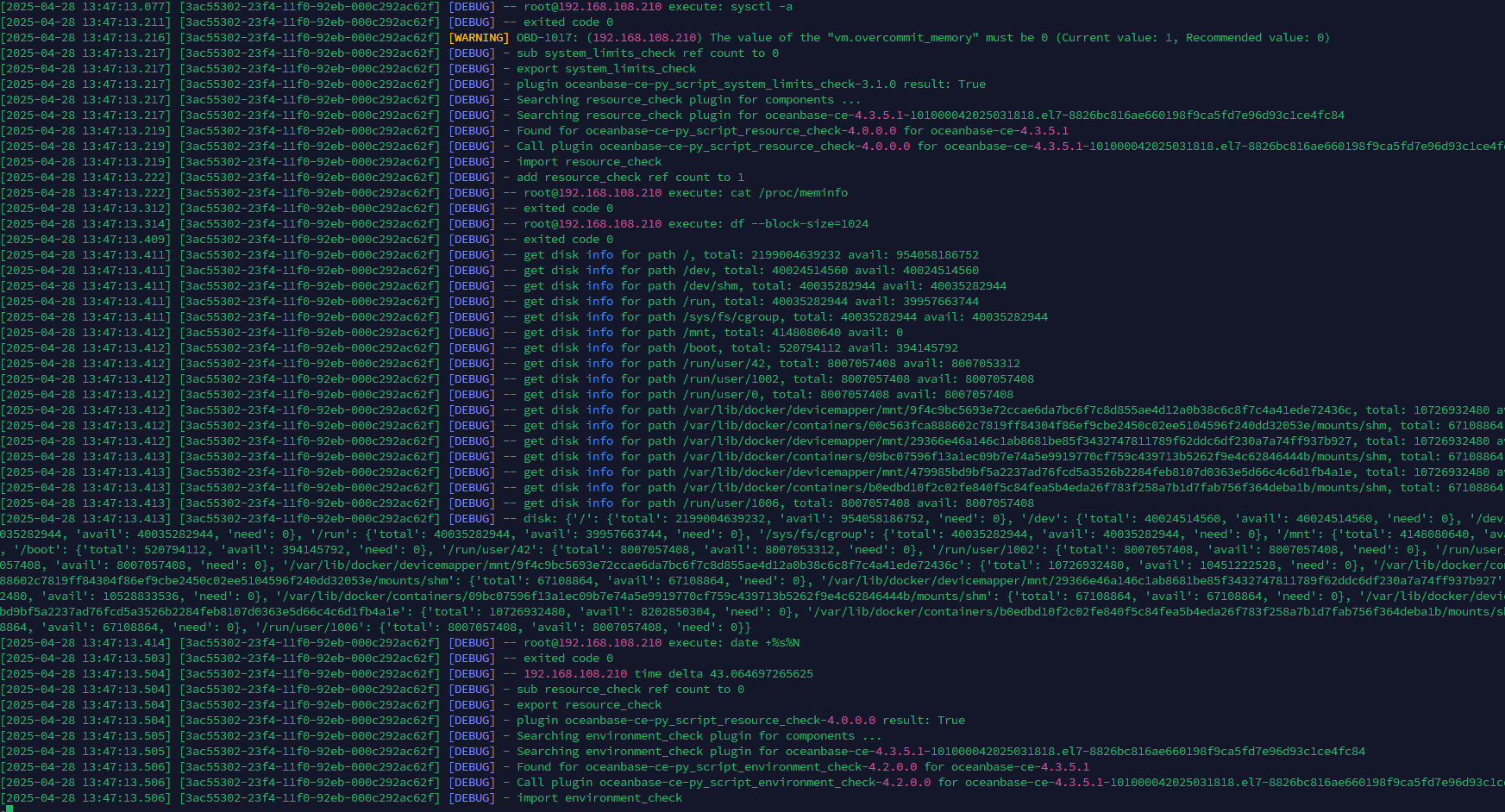



这个版本要avx的,看了下你的cpu支持,可以开启下avx,再重启试试
我是开发人员,对这个avx不太熟悉,搜索了一下,这个avx不是指令集吗?需要怎么开启,早上测试环境的集群都是好的,我执行了一下obd cluster stop后就启动不了了,没重启服务器。信创需要这个玩意
非常感谢回复
OCP升级集群,从4.2.2.1升级至4.2.5.3启动报错 - 社区问答- OceanBase社区-分布式数据库
可以看下我之前遇到的,报错一开始跟你差不多。
启动一段时间后就停止了。你可以尝试下手动拉起看报错,估计就是avx的问题了。
看你的lscpu是没开启的,但是cpu型号是支持的。如果你不会操作或者无法操作,可以使用4.2.2.1版本的oceanbase,这个版本不需要avx。
怎么用这个论坛小助手
根据文档库中的信息,OceanBase 数据库错误码 4009 表示 IO 相关的系统调用失败(如 READ 或 WRITE)。从您提供的日志中可以看到以下关键信息:
[2025-04-28 13:23:36.499904] EDIAG [SERVER] init_io (ob_server.cpp:2538) [6983][observer][T0][Y0-0000000000000001-0-0] [lt=12][errcode=-4009] log block mgr init failed(ret=-4009, ret="OB_IO_ERROR")
这表明在初始化过程中,log block manager 的 IO 操作失败。以下是可能的原因及解决方法:
可能原因及解决方法
-
磁盘空间不足:
- 检查 OceanBase 数据目录是否有足够的磁盘空间。
- 命令:
df -h查看磁盘使用情况。 - 如果磁盘空间不足,请清理不必要的文件或扩展磁盘。
-
磁盘权限问题:
- 确保 OceanBase 数据目录具有正确的读写权限。
- 命令:
ls -ld <data_directory>检查权限。 - 如果权限不足,请使用
chmod和chown修改权限和所有者。
-
文件系统损坏:
- 检查文件系统是否健康。
- 命令:
fsck检查和修复文件系统(需要谨慎操作)。
-
硬件故障:
- 如果磁盘本身存在硬件问题,可能会导致 IO 错误。
- 使用工具如
smartctl检查磁盘健康状态。
-
配置问题:
- 检查
observer.log中是否有其他相关错误信息。 - 确保配置文件中的路径正确且可访问。
- 检查
具体步骤
1. 检查磁盘空间
运行以下命令检查磁盘空间:
df -h
确保数据目录有足够的空间。
2. 检查磁盘权限
运行以下命令检查数据目录权限:
ls -ld /root/yd/oceanbase/store
如果权限不足,修改权限:
chmod 700 /root/yd/oceanbase/store
chown -R oceanbase:oceanbase /root/yd/oceanbase/store
3. 检查文件系统健康
运行以下命令检查文件系统:
fsck /dev/sdX
请将 /dev/sdX 替换为实际的设备名称。
4. 检查硬件状态
运行以下命令检查磁盘健康状态:
smartctl -a /dev/sdX
请将 /dev/sdX 替换为实际的设备名称。
5. 手动启动 Observer
尝试手动启动 Observer,查看详细错误信息:
./observer -p 2882 -P 2881 -c /path/to/config.ini
根据启动时的错误信息进一步排查。
总结
如果以上步骤仍无法解决问题,建议收集以下信息并联系 OceanBase 技术支持:
- 完整的
observer.log日志。 - 系统环境信息(如操作系统版本、硬件配置)。
- 集群配置文件内容。
希望以上信息对您有所帮助!
详情请参考:

根据您提供的 observer.log 日志内容,目前没有直接显示新的错误信息(如错误码或具体的失败原因)。日志中主要记录了 Observer 启动时的初始化信息和系统限制(limits)配置。以下是一些进一步排查和解决的方法:
1. 检查磁盘空间
尽管之前已经检查过磁盘空间,但再次确认数据目录是否有足够的空间仍然是必要的。运行以下命令:
df -h /root/yd/oceanbase/store
确保该路径下的磁盘空间充足。如果不足,请清理不必要的文件或扩展磁盘。
2. 检查文件系统健康状态
使用 fsck 检查文件系统是否健康。例如:
sudo fsck /dev/sdX
请将 /dev/sdX 替换为实际的设备名称。
3. 检查权限问题
确保 OceanBase 数据目录及其子目录具有正确的权限。运行以下命令:
ls -ld /root/yd/oceanbase/store
如果权限不足,请修改权限和所有者:
chmod -R 700 /root/yd/oceanbase/store
chown -R oceanbase:oceanbase /root/yd/oceanbase/store
4. 检查系统资源限制
从日志中可以看到以下系统资源限制信息:
RLIMIT_CORE = 0
RLIMIT_CPU = unlimited
RLIMIT_DATA = unlimited
RLIMIT_FSIZE = unlimited
RLIMIT_LOCKS = unlimited
RLIMIT_MEMLOCK = 65536
RLIMIT_NOFILE = 655350
RLIMIT_NPROC = 610725
RLIMIT_STACK = 8388608
重点检查以下两项:
-
RLIMIT_MEMLOCK:OceanBase 需要较大的内存锁限制。建议将其设置为更大的值,例如
unlimited。 -
RLIMIT_NOFILE:建议设置为更高的值,例如
1048576。
可以通过修改 /etc/security/limits.conf 文件来调整这些限制。例如:
oceanbase soft memlock unlimited
oceanbase hard memlock unlimited
oceanbase soft nofile 1048576
oceanbase hard nofile 1048576
然后重启系统以使更改生效。
5. 检查硬件故障
如果上述步骤均未解决问题,可能是硬件层面的问题。使用以下命令检查磁盘健康状态:
smartctl -a /dev/sdX
请将 /dev/sdX 替换为实际的设备名称。如果发现硬件问题,请更换硬件。
6. 手动启动 Observer 并查看详细日志
尝试手动启动 Observer,并观察启动过程中的详细日志输出:
cd /root/yd/oceanbase/bin
./observer -p 22881 -P 22882 -z zone1 -n yd -c 1744875398 -d /root/yd/oceanbase/store -I 192.168.108.210 -o "__min_full_resource_pool_memory=1073741824,enable_syslog_wf=False,max_syslog_file_count=16,memory_limit=12G,datafile_size=2G,system_memory=5G,log_disk_size=14G,cpu_count=28,datafile_maxsize=8G,datafile_next=2G,large_query_threshold=600s,enable_record_trace_log=False,enable_syslog_recycle=1"
在启动过程中,注意观察是否有新的错误信息输出。
7. 检查集群配置文件
确保集群配置文件(如 config.ini 或 obd cluster config)中的参数正确无误。特别是以下关键参数:
datafile_sizesystem_memorymemory_limitcpu_countdatafile_maxsizedatafile_next
如果配置文件中有不合理的参数,可能会导致启动失败。
8. 联系技术支持
如果以上步骤仍无法解决问题,建议收集以下信息并联系 OceanBase 技术支持团队:
- 完整的
observer.log日志文件。 - 系统环境信息(操作系统版本、硬件配置等)。
- 集群配置文件内容。
总结
目前的日志中没有明确的错误信息,因此需要从以下几个方面继续排查:
- 确保磁盘空间充足。
- 检查文件系统健康状态。
- 确认数据目录权限正确。
- 调整系统资源限制(如
RLIMIT_MEMLOCK和RLIMIT_NOFILE)。 - 检查硬件状态。
- 手动启动 Observer 并观察详细日志。
希望以上信息对您有所帮助!如果仍有问题,请随时反馈更多日志或错误信息。
更多信息请查看:
根据您提供的日志信息和描述,OceanBase 集群启动失败的问题仍然存在。以下是进一步的分析和解决步骤:
1. 确认配置文件路径
- 您提到本地没有
/path/to/config.ini文件,但实际上该路径是一个占位符,表示需要替换为实际的配置文件路径。 - 在您的集群配置中,
obd工具会自动生成配置文件,并将其存储在~/.obd/cluster/<cluster_name>目录下。 - 您可以运行以下命令查看配置文件路径:
obd cluster config yd - 如果需要手动启动 Observer,请使用以下命令:
其中./observer -p <rpc_port> -P <sql_port> -z <zone> -n <cluster_name> -c <config_file_path> -d <data_directory><config_file_path>是通过obd cluster config命令获取的实际路径。
2. 检查日志中的关键错误
- 日志中未明确显示新的错误信息,但之前提到的错误码
4009 (IO error)表明 IO 操作失败。 - 根据文档片段 4 的信息,错误码
4009可能的原因包括:- 磁盘空间不足。
- 文件系统损坏。
- 硬件故障。
- 配置问题。
3. 进一步排查步骤
3.1 检查磁盘状态
- 确保数据目录
/root/yd/oceanbase/store有足够的可用空间:df -h /root/yd/oceanbase/store - 如果磁盘空间不足,请清理不必要的文件或扩展磁盘。
3.2 检查文件系统健康
- 使用
fsck工具检查文件系统是否健康:
(请将sudo fsck /dev/sdX/dev/sdX替换为实际的设备名称)
3.3 检查硬件状态
- 使用
smartctl工具检查磁盘健康状态:sudo smartctl -a /dev/sdX
3.4 检查权限设置
- 确保数据目录具有正确的读写权限:
ls -ld /root/yd/oceanbase/store - 如果权限不足,请修改权限:
chmod 700 /root/yd/oceanbase/store chown -R oceanbase:oceanbase /root/yd/oceanbase/store
3.5 检查资源限制
- 日志中显示了系统的资源限制(
RLIMIT),例如:-
RLIMIT_CORE = 0:表示核心转储文件大小限制为 0,建议调整为非零值以捕获潜在的核心转储文件。 -
RLIMIT_MEMLOCK = 65536:表示锁定内存的限制较低,可能影响性能。
-
- 调整资源限制:
编辑/etc/security/limits.conf文件,添加以下内容:
然后重启系统或重新加载配置。oceanbase soft nofile 655350 oceanbase hard nofile 655350 oceanbase soft nproc 610725 oceanbase hard nproc 610725 oceanbase soft memlock unlimited oceanbase hard memlock unlimited
3.6 检查日志中的其他线索
- 查看
rootservice.log和election.log文件,寻找更多错误信息:tail -f /root/yd/oceanbase/log/rootservice.log tail -f /root/yd/oceanbase/log/election.log
4. 尝试恢复集群
如果以上步骤仍无法解决问题,可以尝试以下方法:
4.1 清理并重新部署集群
- 销毁当前集群:
obd cluster destroy yd - 重新部署集群:
obd cluster deploy yd -c <config_yaml_file>
4.2 手动修复数据目录
- 如果数据目录损坏,可以尝试删除并重新初始化:
rm -rf /root/yd/oceanbase/store/* obd cluster start yd
5. 联系技术支持
如果问题仍未解决,建议收集以下信息并联系 OceanBase 技术支持:
- 完整的
observer.log、rootservice.log和election.log日志。 - 系统环境信息(操作系统版本、硬件配置)。
- 集群配置文件内容(可通过
obd cluster config yd获取)。
希望以上信息对您有所帮助!如果还有其他问题,请随时提问。
检索到的文档如下:
你好当前问题解决了么