

建议时区调整好 重新做合并 看着show trace发过来的数据 是有问题 看着是语句执行打开关闭 陷入循环了 或者不用容器环境 自己单机搭建一个 看看是否还有问题
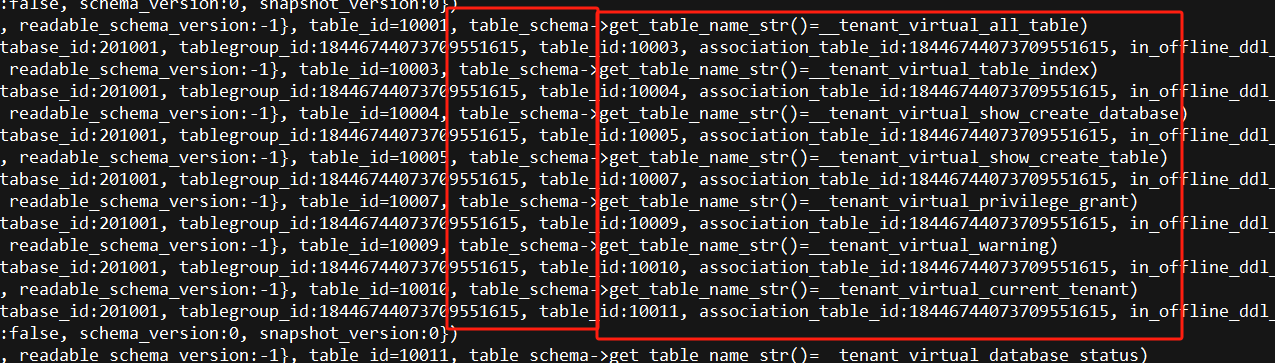
我还有个疑问 : 这个trace日志里面 有大量的这个操作 ,如果 3000多行的话 ,有可能 把所有的表或者视图 检查了一遍schema 。 会有 这样控制的参数不 ??
我记的 mysql 社区版有的操作,会自动触发 检测 ddl 的。
不知道咱们的ob是否有这样的机制。
自动触发检测 我记得mysql是information_schema是一个“in-memory”的数据库 他应该是log里读取数据并且创建表的和隔离级别有关系 可以使用ANALYZE TABLE 表名; 这样手动刷新吧
为什么 求回答
没看懂你发的内容
select count() from test2;
这个语法都过不去呀。
how create table __all_virtual_information_columns的查询结果:
CREATE TABLE `__ALL_VIRTUAL_INFORMATION_COLUMNS` (
`TABLE_SCHEMA` varchar(128) NOT NULL,
`TABLE_NAME` varchar(256) NOT NULL,
`TABLE_CATALOG` varchar(4096) NOT NULL DEFAULT '',
`COLUMN_NAME` varchar(128) NOT NULL DEFAULT '',
`ORDINAL_POSITION` bigint(20) unsigned NOT NULL DEFAULT '0',
`COLUMN_DEFAULT` longtext DEFAULT NULL,
`IS_NULLABLE` varchar(4) NOT NULL DEFAULT '',
`DATA_TYPE` longtext NOT NULL DEFAULT '',
`CHARACTER_MAXIMUM_LENGTH` bigint(20) unsigned DEFAULT NULL,
`CHARACTER_OCTET_LENGTH` bigint(20) unsigned DEFAULT NULL,
`NUMERIC_PRECISION` bigint(20) unsigned DEFAULT NULL,
`NUMERIC_SCALE` bigint(20) unsigned DEFAULT NULL,
`DATETIME_PRECISION` bigint(20) unsigned DEFAULT NULL,
`CHARACTER_SET_NAME` varchar(128) DEFAULT NULL,
`COLLATION_NAME` varchar(128) DEFAULT NULL,
`COLUMN_TYPE` longtext NOT NULL,
`COLUMN_KEY` varchar(3) NOT NULL DEFAULT '',
`EXTRA` varchar(4096) NOT NULL DEFAULT '',
`PRIVILEGES` varchar(200) NOT NULL DEFAULT '',
`COLUMN_COMMENT` longtext NOT NULL DEFAULT '',
`GENERATION_EXPRESSION` longtext NOT NULL DEFAULT '',
PRIMARY KEY (`TABLE_SCHEMA`, `TABLE_NAME`)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'none' REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 10
按照步骤来 那是个举例 哎 你的语句哪个有问题 可以按照案例的步骤来
按照上面的步骤 信息提供一下
我好奇试了下,发现我也有这个问题,用普通租户执行的。但是,和你的又不一样。我只有第一次执行会很慢,20s+,后面再怎么执行都很快了。
select 1 from Information_schema.columns limit 0,1
os : ubuntu 24.04
ce : 4.3.5.1
enable_sql_audit = true
select * from GV$OB_PLAN_CACHE_PLAN_EXPLAIN的结果:

[root@x.x.x.x ~]$ grep “YB420BA1CC68-000615A0A8EA6511-0-0” rootservice.log
[root@x.x.x.x ~]$ grep “YB420BA1CC68-000615A0A8EA6511-0-0” observer.log
换成我自己的TRACE_ID查不到数据
查询的信息 保存在文本里 可以都收集一下么?按照步骤
要在同一个会话下执行
重新搭建了一个单节点OBServer,复现还是相同情况,下面是复现的步骤和trace日志
YB427F000001-000632F610B331C6-0-0.log (2.0 MB)
复现完整记录.txt (33.8 KB)
建议你重新开个帖子 方便跟踪
内部没有复现出来 你的环境方便远程看看么?
我们也遇到了4.3这问题,4.2版本就正常能走table_schema,table_name索引
oceanbase mysql租户表数量超过20000张时查询information_schema.columns视图很慢,执行计划走了全表扫描 - 社区问答- OceanBase社区-分布式数据库

该问题和研发那边确认了,符合当前的预期,是已知问题,后期会优化。如果要在ob4351版本上走到pk,可以在创建租户的时候将 lower_case_table_names 变量设置为1,但是这个变量在租户创建好后就不能修改了。ob425bp1上查询应该没有问题
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000002016015
1 个赞
lower_case_table_names 参数默认是1,看上去参数配置没效果。 感谢解答,影响面不大,等一波研发修复后的版本做验证了
系统视图元数据量过大
Information_schema.columns 是系统视图,存储所有表的列元数据。如果数据库中存在大量表或列(如数万张表、数百万列),查询该视图会触发全量元数据扫描,导致延迟
部分数据库(如MySQL)的 Information_schema 视图基于实时元数据生成,每次查询需动态计算,而非预存储静态数据
数据量大慢是可以理解的,实际上面测试场景数据量不大的,只有内部表基础数据,总数据量就1w条左右,用limit 1就数据量更少了。 慢的原因应该不是和数据量有关。 我猜测是基表查询是真是的表数据,用户租户查询的是视图或加工后的数据,中间处理逻辑导致走不到索引或部分操作导致索引失效了。
可以