【 使用环境 】 测试环境&生产环境https://upfile.live/zh-cn/files/a33fd19f
在虚拟机上部署的OB都有出现类似的告警
2 个赞
靖顺
2025 年4 月 10 日 12:31
#3
2 个赞
淇铭
2025 年4 月 10 日 13:37
#4
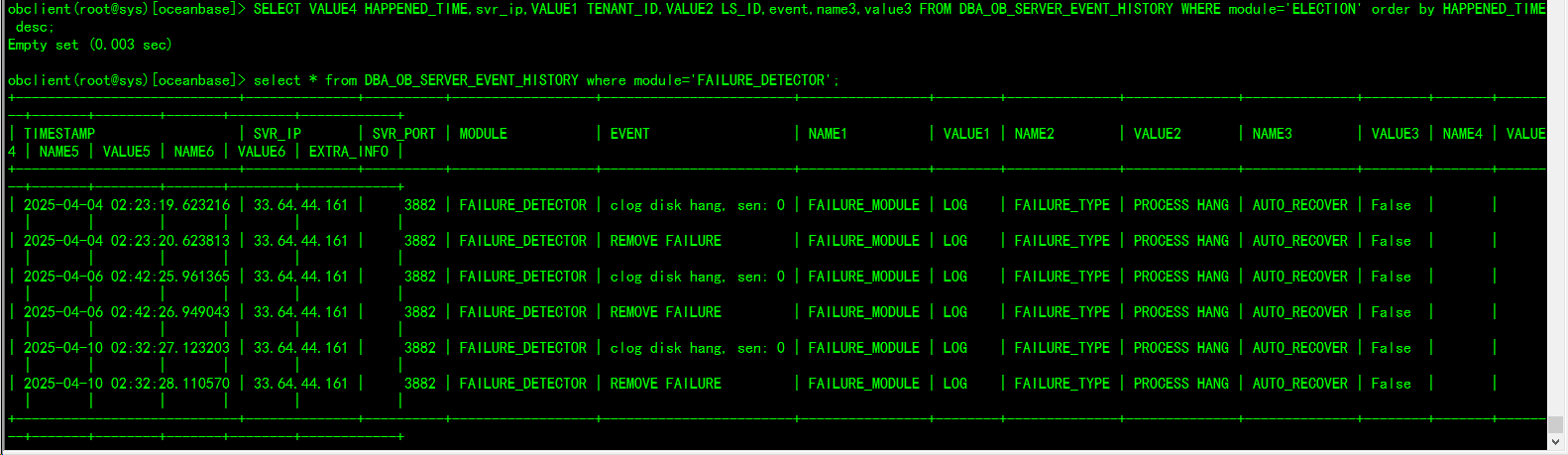
用obdiag命令 可以具体分析 日志采集命令: obdiag gather scene run --scene=[observer.io ] 那你这个检查 也对应到虚拟机里observer.io
2 个赞
gather_scene.gz (28.0 MB)
请看下是这个吗
2 个赞
淇铭
2025 年4 月 10 日 15:26
#7
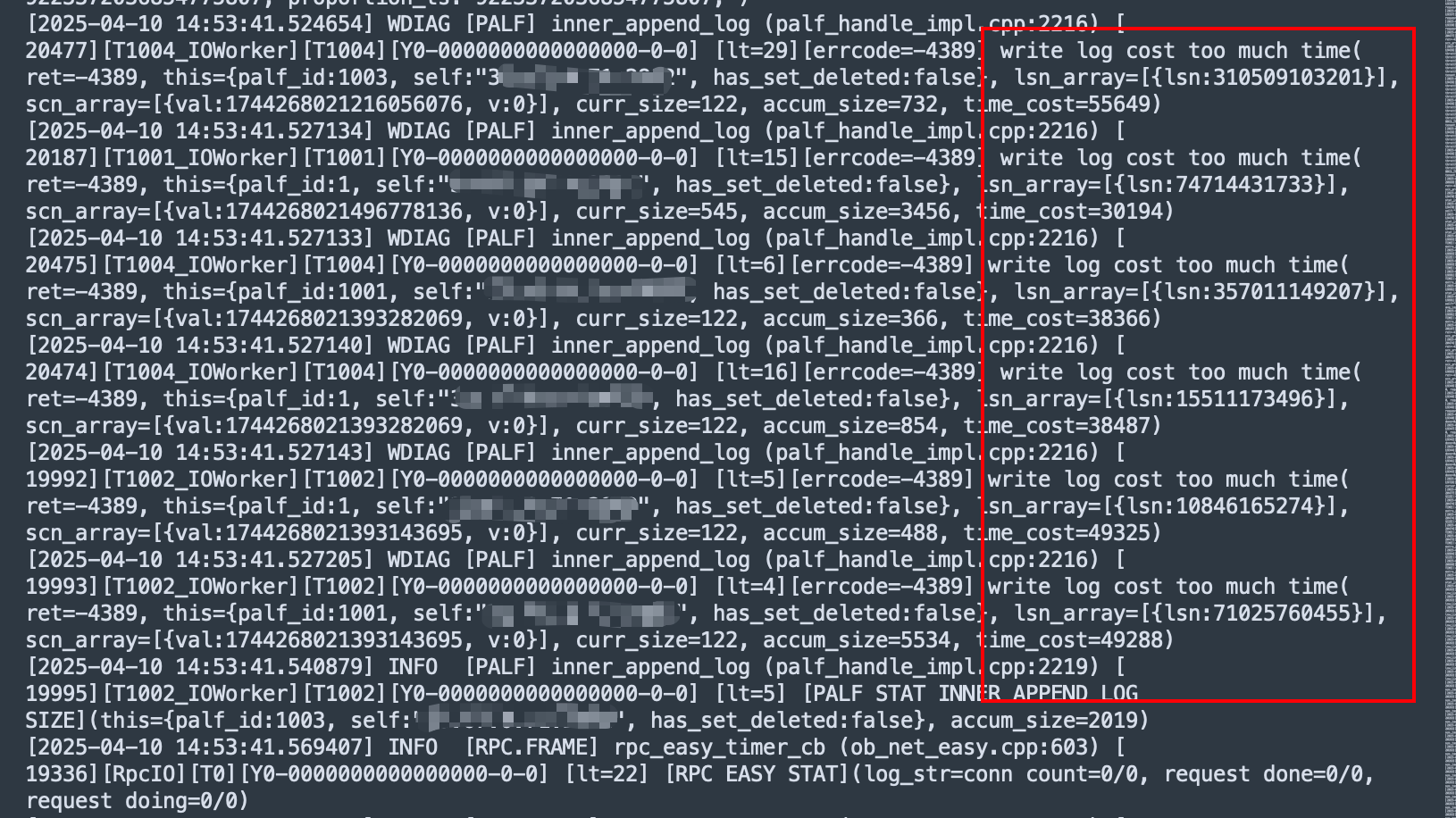
目前在observer.log看到大量 4389的报错,clog日志同步太慢,和IO调度相关
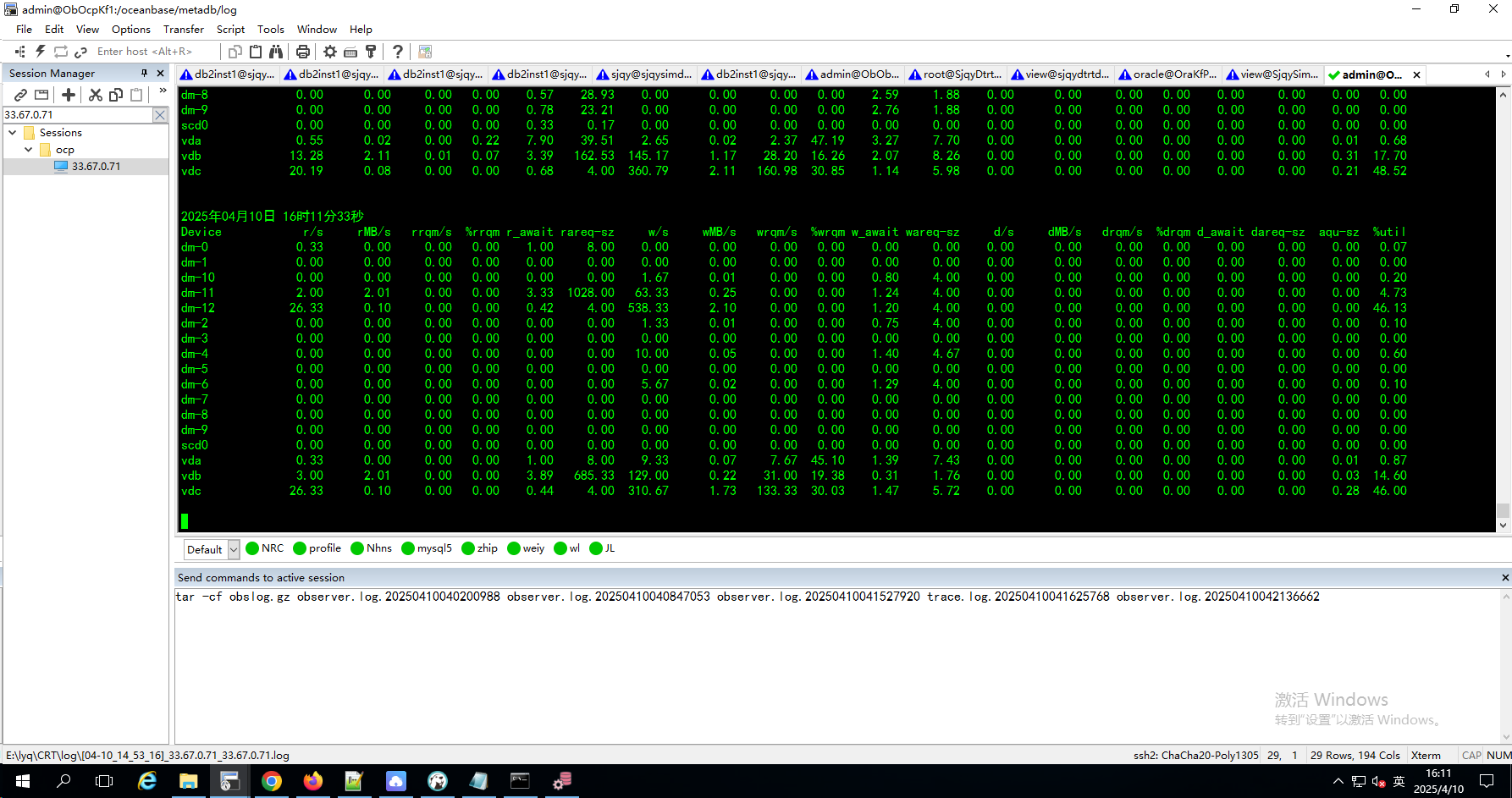
1.在服务器上监控下磁盘IO情况 iostat -mxdt 3
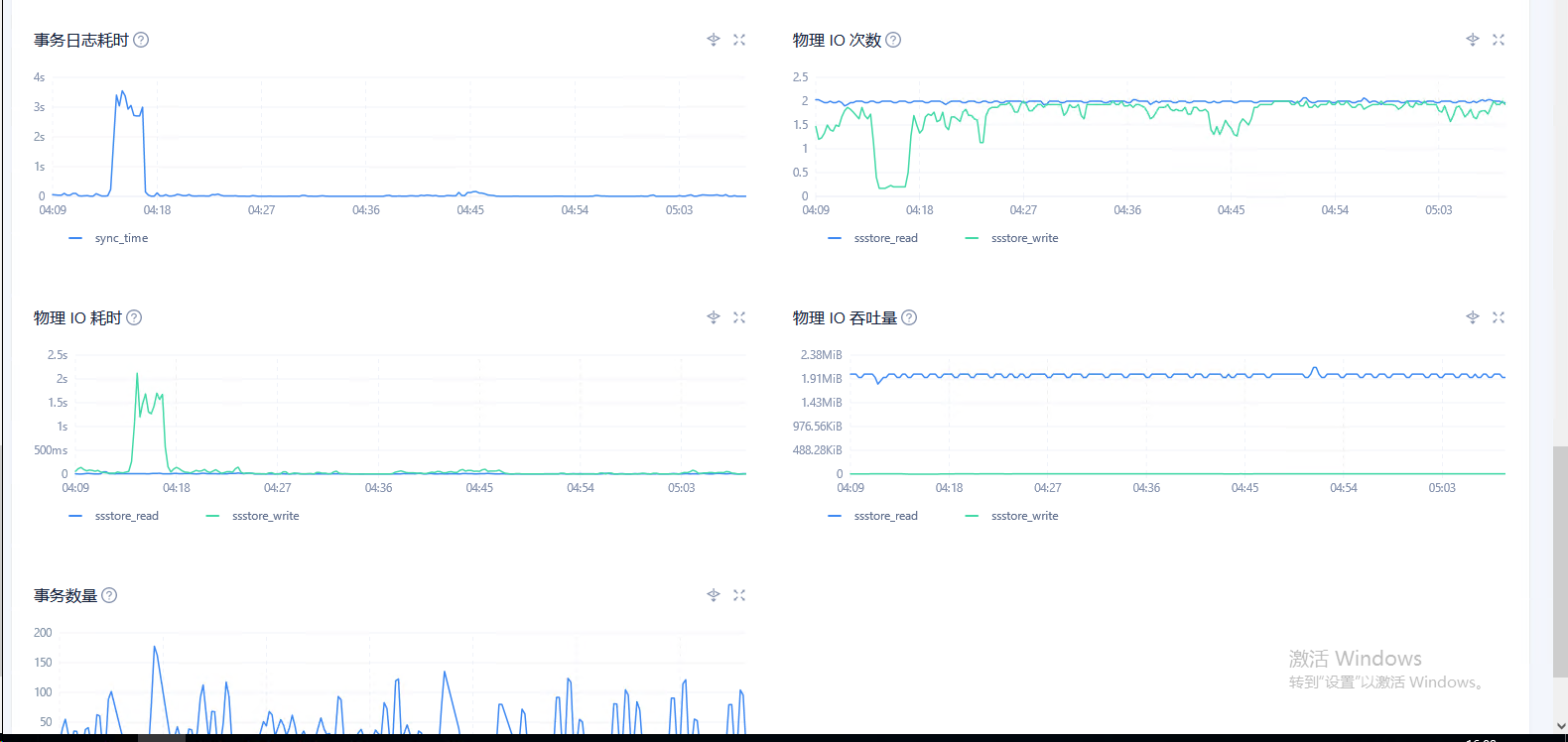
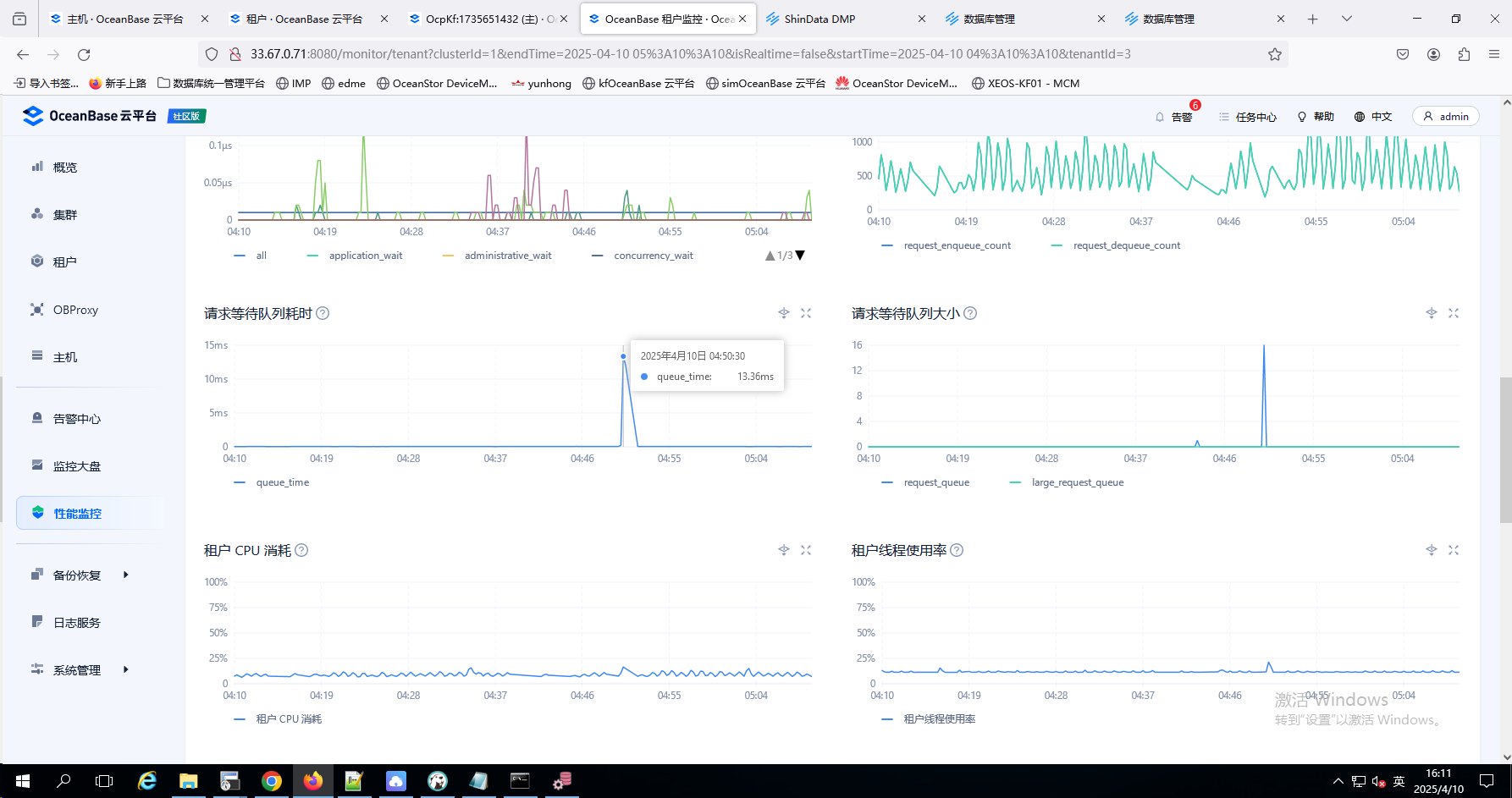
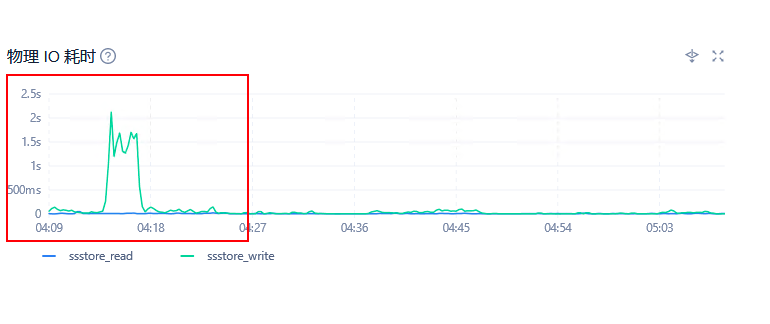
2.在ocp 租户–> 性能监控–>存储与缓存 物理 IO 次数,物理IO吞吐量,物理IO耗时
3.在ocp 租户–> 性能监控–>性能与SQL 看下 clog同步延迟 , 租户 CPU 消耗,内存使用率
还有这个时间段的[2025-04-10 04:49:51.373108] observer.log日志么?
2 个赞
淇铭
2025 年4 月 10 日 15:32
#8
ocean你的base:
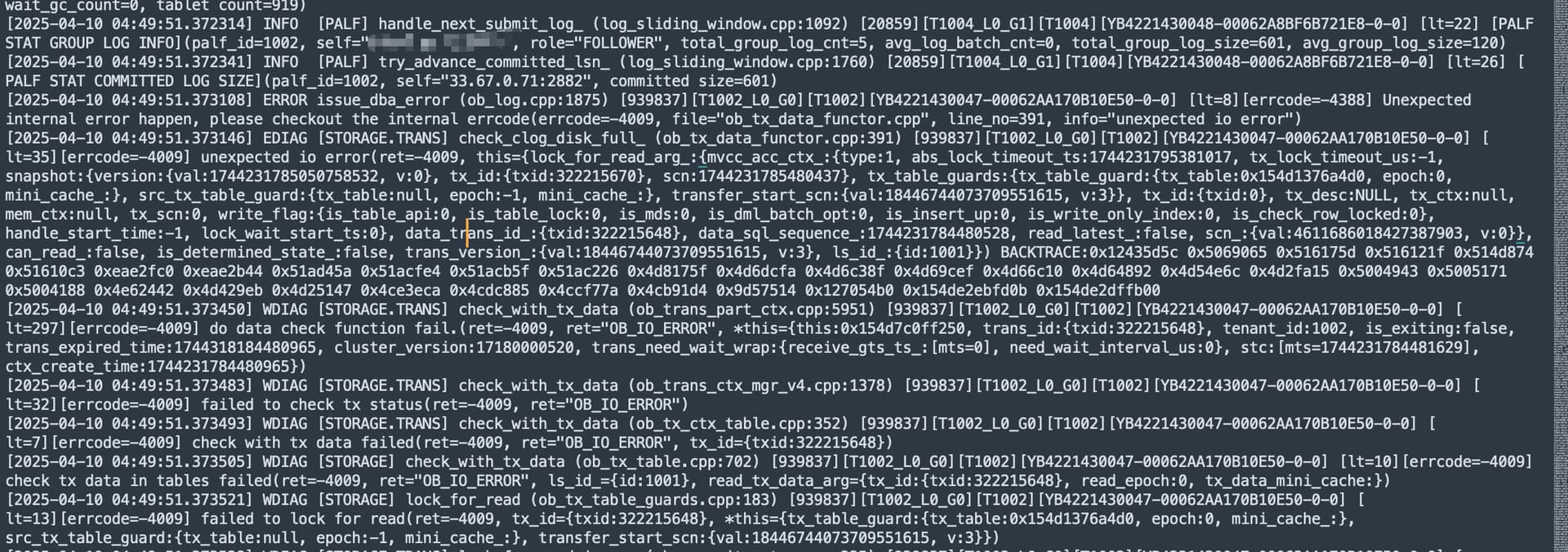
issue_dba_error (ob_log.cpp:1875) [939837][T1002_L0_G0][T1002][YB4221430047-00062AA170B10E50-0-0] [lt=8][errcode=-4388] Unexpected internal error happen, please checkout the internal errcode(errcode=-4009, file=“ob_tx_data_functor.cpp”, line_no=391, info=“unexpected io error”)。
报这个错 应该是日志盘Hang的场景才会报这个错误。按照我楼上发的排查一下
查一下这两个信息 注意粘贴过去 字符转义
1 个赞
这些都是在OCP所在服务器的信息,我们目前ob上的服务不多,OCP三节点部署,每个节点32C64G的配置
observer.log.20250410045205828.7z (6.3 MB)
2 个赞
淇铭
2025 年4 月 10 日 16:22
#11
你用的是机械盘还是ssd盘 看着物理io耗时 太高了 应该是磁盘出问题了吧 即使机械盘 也不应该是这样
1 个赞
虚拟机部署在超融合上,使用的是机械硬盘,但是有ssd缓存
1 个赞
淇铭
2025 年4 月 10 日 16:36
#13
ocean你的base:
4388
看着是磁盘异常导致的clog hang住了 先检查一下磁盘 看看是否有问题 可以在用dd测试 服务器上监控下磁盘IO情况 iostat -mxdt 3
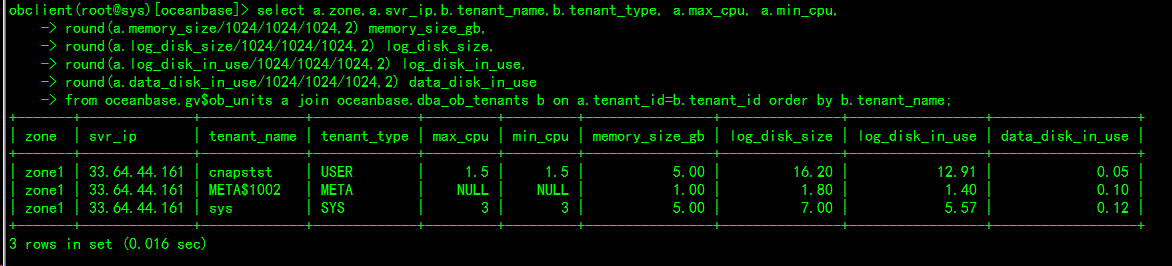
select a.zone,a.svr_ip,b.tenant_name,b.tenant_type, a.max_cpu, a.min_cpu,
1 个赞
淇铭
2025 年4 月 10 日 16:43
#14
是物理机搭建的私有云么?在私有云上通过虚拟机部署ob集群么?
在OCP的SYS租户下查询的,OCP下有纳管7个集群,不知为何只能看到其中一个集群
淇铭
2025 年4 月 10 日 17:17
#20
ob部署的硬件要求是ssd的磁盘 建议更换成ssd的磁盘 不过你这个问题是磁盘异常导致的clog hang 检查一下磁盘