

本帖内容来源是在 OB 社区负责人的公众号 “老纪的技术唠嗑局” 中首发的《千呼万唤始出来 —— OB 全文索引能力史诗级增强》。
我们会在这个公众号上持续更新技术内容!欢迎大家扫码关注!

正文开始:
之前做技术支持时,很多用户都需要用到 OB 缺失的全文索引能力。
给全文索引的开发同学令川提过很多次需求,但他总画饼说:“XXX 版本就会支持全文索引了”
所以当时必须通过 like + 其他各种调优手段,把用户 SQL 性能一路优化到符合用户预期才算完,我的性能调优水平也因为这个功能的缺失而不断提升。后面在和一群技术专家们共同编写《DBA 入门教程》时,老大都让我来负责其中最复杂的性能调优章节了……
今天,令川终于在 4.3.5 版本中,支持了一个功能完整且性能过硬的全文索引。好饭不怕晚,特此发布一篇文章,为大家介绍 OB 中全文索引的功能和性能表现。
欢迎大家试用!
背景(What is OB FTS)
随着 4.3.5 GA 发布,OB 全文索引从功能和性能方面带来了诸多增强与提升。与之前版本局限于协助业务验证选型不同,最新版本的全文索引能够帮助用户解决实际生产中的问题。例如在系统日志分析、用户行为和画像分析等场景里,全文索引能够对数据做高效率过滤筛选、或是高质量相关性评估。最近火热的 AI 方面,将稀疏稠密向量和全文结合在一起的多路召回架构,能在具有特殊知识领域的 RAG 系统中取得更高更好的召回效果。
本文将通过一些小 demo 和测试结果对比,展示新版 OB 全文在功能、性能和易用性方面的提升。
原理简述 (How it works)
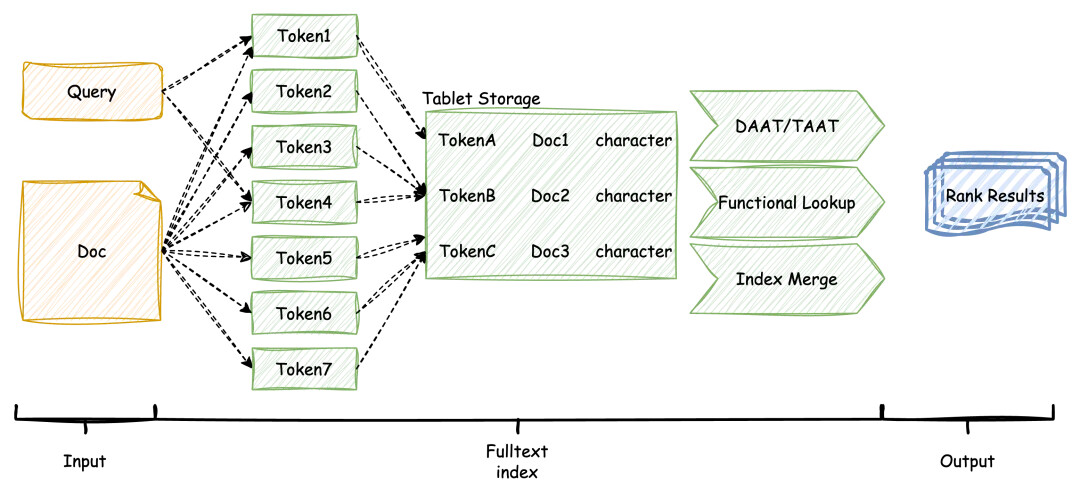
数据库中全文索引要解决的基本问题就是如何通过查询里的关键词快速有效地找到对应的文档。在 OB 存储引擎内部,用户的文档(doc)会被分词器(parser)拆分成若干关键词(word/token)。这些关键词连同文档的统计信息特征被存储在内部的辅助表(tablet)上,用于信息检索阶段的相关性评估算法(ranking)。OB 采用能够更好评估信息关联性的 BM25 算法,对用户查询语句中的关键词和存储的文档计算相关性分数,并最终输出有关联的文档和其评分。
结合 OB 已有的高性能查询引擎能力,在全文索引查询流程内,我们针对性地做了 TAAT/DAAT 流程优化、对标 ORACLE 的 functional lookup 功能以及多索引间的 index merge 等。这使得全文能结合更多复杂的查询特性,完成用户想要的数据检索。
实验 (What can I do)
介绍了那么多,我们动手体验下 OB 全文索引,同时会展示一些常用的视图和查询技巧。
集群部署与数据导入
首先我们用最新版 OB 4.3.5 BP1 搭建了两副本,一个 2c4g 的 MySQL 模式租户。
OB 内置有支持中文语言的 IK 分词器,以及比传统自然语言模式更好用的布尔模式。所以实验的数据集使用中文足球体育新闻(https://github.com/ej0cl6/SportsSum)。在 OB 内创建一张无主键分区表,包含三列变长字符串(event,date,news)。对 news 字段使用了 IK 中文分词器,并指定 max_word 模式。IK 分词器的另一种 smart 模式,和 max_word 的区别是,其在匹配到最长词语后就停止匹配更短的词语。
OB 内置的分词器还包括适合英语的 space 和 beng。以及按照字符长度分割的 ngram。
-- 建表语句
CREATE TABLE sport_data_whole(
event varchar(64),
date varchar(16),
news varchar(65535),
fulltext INDEX (news) WITH parser ik PARSER_PROPERTIES =(ik_mode = "max_word")
);
通过客户端本地文件的方式,将新闻数据集导入到表格内,时间大概是在十五秒左右。
-- 导入语句
load data /*+ parallel(8) */
local infile "/home/jiahua.cjh/sports_data_whole.csv"
into table sport_data_whole
fields terminated by ',' lines terminated by '\n';
导入后共 5268 条新闻,平均文档长度在 2700 个中文字。原始数据是 57MB 左右。实际存储的总空间大小,在经过存储引擎的压缩后,连同索引不到 30MB。可以看到其中比较大的是全文索引中倒排和正排辅助表,内部存储了比较多的分词记录。
-- 体育新闻数据集
select
avg(length(news)),
count(*)
from
sport_data_whole;
+-------------------+----------+
| avg(length(news)) | count(*) |
+-------------------+----------+
| 2781.6900 | 5268 |
+-------------------+----------+
1 row in set (0.03 sec)
select
*
from
oceanbase.DBA_OB_TABLE_SPACE_USAGE\G
*************************** 1. row ***************************
TABLE_ID: 500007
DATABASE_NAME: test
TABLE_NAME: sport_data_whole
OCCUPY_SIZE: 8349796
REQUIRED_SIZE: 10489856
*************************** 2. row ***************************
TABLE_ID: 500008
DATABASE_NAME: test
TABLE_NAME: __idx_500007_news
OCCUPY_SIZE: 30247553
REQUIRED_SIZE: 31461376
*************************** 3. row ***************************
TABLE_ID: 500009
DATABASE_NAME: test
TABLE_NAME: __idx_500007_fts_rowkey_doc
OCCUPY_SIZE: 70125
REQUIRED_SIZE: 77824
*************************** 4. row ***************************
TABLE_ID: 500010
DATABASE_NAME: test
TABLE_NAME: __idx_500007_fts_doc_rowkey
OCCUPY_SIZE: 73171
REQUIRED_SIZE: 77824
*************************** 5. row ***************************
TABLE_ID: 500011
DATABASE_NAME: test
TABLE_NAME: __idx_500007_news_fts_doc_word
OCCUPY_SIZE: 28302737
REQUIRED_SIZE: 29364224
利用全文索引查询
利用存储进数据库中的新闻数据集和索引,我们可以做多条件自由组合,达到高过滤性信息检索的目的。例如作为球迷的我想搜索包含有 “拜仁” 和 “乌龙球” 的新闻,推荐使用布尔模式。相较于没有索引的字符串 like 匹配,布尔模式语法上更简洁易懂,查询速度也会更快。
-- 布尔模式
select
count(*)
from
sport_data_whole
where
match (news) against ('+乌龙球 +拜仁' in boolean mode);
+----------+
| count(*) |
+----------+
| 2 |
+----------+
1 row in set (0.03 sec)
select
count(*)
from
sport_data_whole
where
news like '%乌龙球%'
and news like '%拜仁%';
+----------+
| count(*) |
+----------+
| 2 |
+----------+
1 row in set (0.08 sec)
对于返回的多条新闻,在输出结果中增加分值,能用来帮助我们判断哪条新闻更有关联。OB 的全文支持经过 BM25 算法计算得到的相关性分数。下面可以看到 date 是 0278 的新闻,和我们查询的目的更具关联性。
-- ranking
select
event,
date,
match (news) against ('乌龙球 拜仁') as score
from
sport_data_whole
where
match (news) against ('+乌龙球 +拜仁' in boolean mode);
+-------+------+---------------------+
| event | date | score |
+-------+------+---------------------+
| ucl | 0278 | 0.4657063867776557 |
| ucl | 0201 | 0.41760566608994765 |
+-------+------+---------------------+
2 rows in set (0.04 sec)
布尔模式相较于自然语言,还能反向剔除一些关键词。例如每场足球比赛中几乎都有犯规行为,如果我想知道哪些比赛很激烈,但是没有红黄牌甚至没有犯规,则可以用到布尔模式里的 “-” 运算符。
-- 布尔模式运算
select
count(*)
from
sport_data_whole
where
match (news) against ('+激烈 -黄牌 -红牌 -犯规' in boolean mode);
+----------+
| count(*) |
+----------+
| 31 |
+----------+
1 row in set (0.04 sec)
一个调试的小技巧,当发现全文索引的查询结果不符合预期时,通常是因为分词结果不理想。OB 提供了一个快速的 TOKENIZE 函数来辅助测试分词结果。函数支持所有分词器和对应属性。例如下面手动的分词结果,反映了词典中对于国外体育明星人名的支持还不是很好(博阿滕、格策),因此用这些人名去检索新闻的效果可能达不到预期。
-- tokenize 函数
select
tokenize(
'博阿滕右路反击人球分过传中,格策后点停球转身闪开角度,在门前8米处低射从皮亚托夫裆下钻进门内',
'ik',
'[{"additional_args": [{"ik_mode": "smart"}]}]'
);
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| tokenize('博阿滕右路反击人球分过传中,格策后点停球转身闪开角度,在门前8米处低射从皮亚托夫裆下钻进门内', 'ik', '[{"additional_args": [{"ik_mode": "smart"}]}]') |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| ["亚", "格", "夫", "阿", "门内", "从", "下钻", "后点", "右路", "分过", "传中", "低", "转身", "球", "射", "闪开", "博", "进", "反击", "门前", "停", "人", "皮", "裆", "策", "滕", "8米处", "托", "在", "角度"] |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.03 sec)
select
count(*)
from
sport_data_whole
where
match (news) against ('+格策 +博阿滕' in boolean mode);
+----------+
| count(*) |
+----------+
| 0 |
+----------+
1 row in set (0.04 sec)
如果想提升分词器的精准性,OB 支持修改系统词典表。当我们将上述中文人名插入到系统词典表后,重新分词的效果立竿见影。
注:词典修改后,原索引分词效果不变,需要重建索引生效。
-- 中文人名分词效果
select
tokenize(
'博阿滕右路反击人球分过传中,格策后点停球转身闪开角度,在门前8米处低射从皮亚托夫裆下钻进门内',
'ik',
'[{"additional_args": [{"ik_mode": "smart"}]}]'
);
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| tokenize('博阿滕右路反击人球分过传中,格策后点停球转身闪开角度,在门前8米处低射从皮亚托夫裆下钻进门内', 'ik', '[{"additional_args": [{"ik_mode": "smart"}]}]') |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| ["门内", "从", "下钻", "后点", "右路", "分过", "传中", "低", "转身", "球", "皮亚托夫", "射", "闪开", "进", "反击", "门前", "停", "人", "裆", "8米处", "在", "角度", "格策", "博阿滕"] |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.04 sec)
select
count(*)
from
sport_data_whole
where
match (news) against ('+格策 +博阿滕' in boolean mode);
+----------+
| count(*) |
+----------+
| 79 |
+----------+
1 row in set (0.05 sec)
实验的最后,我们来对比下全文索引与普通索引混合查询下,union merge 带来的性能提升。我们对 sport_data_whole 表的 date 列再建立一个普通局部索引。可以通过 show index 观察索引生效情况。
-- 构建普通索引
alter table sport_data_whole add index (date);
show index from sport_data_whole\G
*************************** 1. row ***************************
Table: sport_data_whole
Non_unique: 1
Key_name: news
Seq_in_index: 1
Column_name: news
Collation: A
Cardinality: NULL
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: FULLTEXT
Comment: available
Index_comment:
Visible: YES
Expression: NULL
*************************** 2. row ***************************
Table: sport_data_whole
Non_unique: 1
Key_name: date
Seq_in_index: 1
Column_name: date
Collation: A
Cardinality: NULL
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment: available
Index_comment:
Visible: YES
Expression: NULL
2 rows in set (0.00 sec)
当两个索引条件使用 OR 连接时,过滤性好的情况下,union merge 带来的收益会比扫描普通索引后再过滤(计划中有 has_functional_lookup=true)更快。从两种计划最后预估的时间上可以看到有数量级提升。
-- union merge 计划对比
explain
select
/*+UNION_MERGE(sport_data_whole date news)*/
*
from
sport_data_whole
where
date = '0322'
or (match (news) against ('+乌龙球' in boolean mode));
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Query Plan |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| =================================================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------------------------------------------- |
| |0 |DISTRIBUTED INDEX MERGE SCAN|sport_data_whole(date,news)|45 |9102 | |
| =================================================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([sport_data_whole.event], [sport_data_whole.date], [sport_data_whole.news]), filter([sport_data_whole.date = '0322' OR MATCH(sport_data_whole.news) |
| AGAINST('+乌龙球' IN BOOLEAN MODE)]), rowset=256 |
| access([sport_data_whole.__pk_increment], [sport_data_whole.date], [sport_data_whole.news], [sport_data_whole.event]), partitions(p0) |
| is_index_back=true, is_global_index=false, keep_ordering=true, use_index_merge=true, filter_before_indexback[false], |
| index_name: date, range_cond([sport_data_whole.date = '0322']), filter(nil) |
| index_name: news, range_cond(nil), filter(nil) |
| lookup_filter([sport_data_whole.date = '0322' OR MATCH(sport_data_whole.news) AGAINST('+乌龙球' IN BOOLEAN MODE)]) |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+
14 rows in set (0.03 sec)
explain
select
*
from
sport_data_whole
where
date = '0322'
or (match (news) against ('+乌龙球' in boolean mode));
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Query Plan |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| =========================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------------------- |
| |0 |TABLE FULL SCAN|sport_data_whole|79 |526939 | |
| =========================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([sport_data_whole.event], [sport_data_whole.date], [sport_data_whole.news]), filter([sport_data_whole.date = '0322' OR MATCH(sport_data_whole.news) |
| AGAINST('+乌龙球' IN BOOLEAN MODE)]), rowset=256 |
| access([sport_data_whole.__pk_increment], [sport_data_whole.date], [sport_data_whole.news], [sport_data_whole.event]), partitions(p0) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([sport_data_whole.__pk_increment]), range(MIN ; MAX)always true, has_functional_lookup=true |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+
12 rows in set (0.04 sec)
MySQL 性能对比(How about the performance)
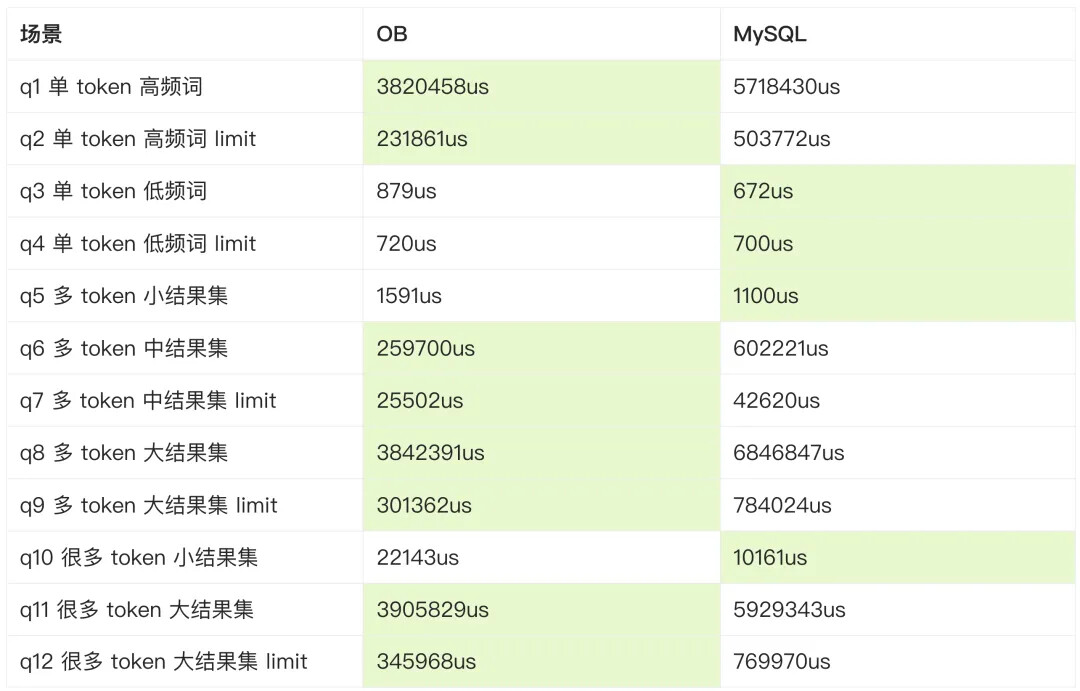
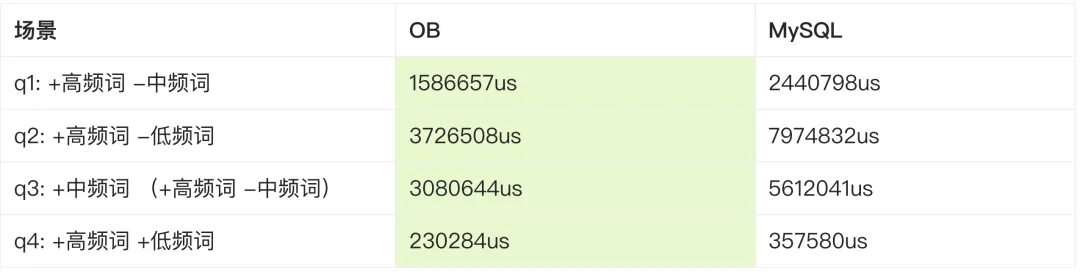
OB 的全文索引性能横向比较又是如何的呢?我们以 MySQL 的全文为例。MySQL 的中文分词能力不是很好,因此对比数据集选定在英文数据集 wikir1k(369721行,平均每行100词)上。以下分别是自然语言模式,以及布尔模式下多种场景的对比结果。
结果上:
-
OB 在需要大量分词或是返回结果的场景中,都远优于 MySQL。
-
小结果集上,因为计算量占比不高,查询引擎的优势不明显,两者十分接近。
测试环境 :
OB 租户规格 8c 16g
MySQL Ver 8.0.36 for Linux on x86_64 (MySQL Community Server - GPL)
自然语言模式
# Query
# q1
select * from wikir1k where match (document) against ('and');
# q2
select * from wikir1k where match (document) against ('and') limit 10;
# q3
select * from wikir1k where match (document) against ('librettists');
# q4
select * from wikir1k where match (document) against ('librettists') limit 10;
# q5
select * from wikir1k where match (document) against ('alleviating librettists');
# q6
select * from wikir1k where match (document) against ('black spotted white yellow');
# q7
select * from wikir1k where match (document) against ('black spotted white yellow') limit 10;
# q8
select * from wikir1k where match (document) against ('between up and down');
# q9
select * from wikir1k where match (document) against ('between up and down') limit 10;
# q10
select * from wikir1k where match (document) against ('alleviating librettists modifications retelling intangible hydrographic administratively berwickshire strathaven dumfriesshire lesmahagow transhumanist musselburgh prestwick cardiganshire montgomeryshire');
# q11
select * from wikir1k where match (document) against ('alleviating librettists modifications retelling intangible hydrographic administratively berwickshire strathaven dumfriesshire lesmahagow transhumanist musselburgh prestwick cardiganshire montgomeryshire and');
# q12
select * from wikir1k where match (document) against ('alleviating librettists modifications retelling intangible hydrographic administratively berwickshire strathaven dumfriesshire lesmahagow transhumanist musselburgh prestwick cardiganshire montgomeryshire and') limit 10;
布尔模式
# Query
# q1: +高频词 -中频词
select * from wikir1k where match (document) against ('+and -which -his' IN BOOLEAN MODE);
# q2: +高频词 -低频词
select * from wikir1k where match (document) against ('+which (+and -his)' IN BOOLEAN MODE);
# q3: +中频词 (+高频词 -中频词)
select * from wikir1k where match (document) against ('+and -carabantes -bufera' IN BOOLEAN MODE);
# q4: +高频词 +低频词
select * from wikir1k where match (document) against ('+and +librettists' IN BOOLEAN MODE);
更上一层楼(One more thing)
综上,最新版本的全文索引,在以下方面帮助用户解决更多搜索使用上的痛点:
1. 支持分区表,索引数据和分区数据就近存储,提高性能。
2. 支持主表上建立多种混合索引(普通二级、全文、多值、向量等),一套数据应对不同查询目标和加速场景。
3. 支持 IK 中文分词器和词典修改,在一些需要中文专业术语的业务里,字典维护和匹配更加易用和精准。
4. 支持常用的自然语言和布尔模式,性能优于 MySQL,功能与性能两方面支撑业务做平替。
未来规划(future)
OB 全文索引的能力还远不止于此,结合新的技术趋势和新的数据检索场景,在后续版本,我们还会推出更多易用性功能。例如:
-
能支持交集能力的全面的 index merge;
-
以插件方式支持更丰富流行的多语言分词器;
-
更灵活的用户自定义词典和停词;
-
更常用的 term query、phrase query,compound query 功能;
-
在检索方面,结合 OB 的多模稀疏向量,进一步增强文档的语义理解力;
-
使用多路召回、动态剪裁以及底层例如 WAND 的加速算法,在质量和速度两个方面提升检索体验等等。
敬请大家期待!