

玄铁剑一送即收,杨过回剑向后,当的一响,已将背后袭来的铜轮劈为两半,铜轮尚未分开落地,重剑横挥,两半片铜轮从中截断,分为四块。
玄铁剑虽然剑刃无锋,但他运上内力,竟是无坚不摧。
众人见了国师的绝顶轻功,还喝得出一声采,待见到他这神剑奇威,都惊得寂然无声。
——《神雕侠侣》三联版第二十七章
1. 背景
Nest Loop Join 是操作过程最简单的一种 Join 算法。相比于 Sort Merge Join 和 Hash Join,也是 Join 中最自然的一种实现方式。
但在很多场景下,Nest Loop Join 这种最朴实无华、大巧不工的 Join 算法,往往能够像杨过手中的玄铁剑一样,发挥出巨大的威力。

前一段儿时间,参加了 OceanBase 优化器研发同学关于 Nest Loop Join 的一个技术分享,受益匪浅。所以今天就给大家也一起分享下 TP 业务中经常出现的这个 Nest Loop Join(NLJ)。这篇文章值得对数据库感兴趣的朋友们收藏和仔细阅读,肯定能够有所收获。 也可以根据实际需求,选择性地进行阅读部分内容。
这篇文章相较于原分享,会根据我自己的理解,进行一些删改和调整,主要内容包括:NLJ 的基础概念(条件下推、Rescan 等)、OceanBase 中对 NLJ 的优化方式、NLJ 使用过程中的相关调优技巧等。最后,还会为大家奉上一张分布式数据库中的 NLJ 优化路径图。
2. Nest Loop Join 基础知识
TP 类型的业务中,多表连接查询通常会有几个典型的特征:
-
访问的数据量不会非常大。
- 如果访问数据量非常的大,客观来说 SQL 的执行耗时就会比较高。对 TP 这种延迟敏感,吞吐率比较高的场景,这类请求就会不太合适。这意味着,SQL 中总是会存在一些过滤性非常强的谓词。
-
表和表之间的连接通常是主外键连接。
- 这意味着,表和表之间的连接条件通常对一侧的过滤性非常强。
接下来,我们会先介绍一些 NLJ 的一些特质,以及为什么它是适合这类 TP 场景的。
2.1 条件下推的 NLJ

在上面这个执行计划中。
-
T1 表有一个非常强的过滤谓词 (T1.VAL = 10),走 IDX_VAL 这个索引实际只需要扫描一行数据。
-
T2 表上是没有基表过滤谓词的,只有一个和 T1 表的连接谓词。走 NEST LOOP JOIN(简记 NLJ) 可以把 T1.ID = T2.ID 转换成 T2 上的过滤条件 (T2.ID = ?),走 IDX_ID 这个索引之后,每次也只需要扫描一行数据。
这种将连接条件转换为右表的基表过滤条件的 NLJ,我们称之为条件下推的 NLJ。
它最直观的好处是:即使 T2 表上没有过滤谓词,也不需要全表扫,可以利用连接条件来走索引。这一点是非常 “TP” 的,它可以综合利用连接谓词和索引来极大地减少数据扫描量。而其他 JOIN (HASH JOIN,MERGE JOIN)算法是做不到这种效果的。
2.2 NLJ 执行机制
上一节简要介绍了条件下推的 NLJ 的性能优化的意义。这里进一步讲解一下条件下推的 NLJ 实际执行的流程。
最简化的执行模型大致如下:

可以看到在整个过程中,
-
对 T1 表的 scan 操作实际发起了一次,从 Query Range 的起点顺序扫描下去的;
-
对 T2 表的 scan 操作反复发起了 N 次(N 为 T1 的扫描的行数),每次重新确定 Query Range 的起点和终点进行扫描。
NLJ 中对 T2 这种反复 scan 的操作,我们称之为 Rescan。
2.3 流式执行
除了条件下推的能力外,NLJ 还有一个很重要的性质:流式执行。为了方便理解这个性质,我们通过下面的案例来进行进一步的阐述。
在上面这个案例中,T1, T2 都没有任何的过滤条件,只存在一个连接条件。这是不是意味着这里没有任何的优化空间存在,我们只能选择全表扫描?事实上,这个查询还存在一个限制读取行数非常强的子句 LIMIT 10。整个查询只要读取到 10 行结果就可以终止。
上面这就是一个典型的流式计划。这个执行计划中,2 号算子扫描 IDX_VAL,扫描结果是按照 T1.VAL 字段有序的。1 号 NEST LOOP JOIN 可以继承左支的序,因此不需要为 ORDER BY T1.VAL 分配额外的 SORT 算子,0 号是一个 LIMIT 算子。回忆下前面介绍的 NLJ 的执行过程,它每迭代出 T1、T2 的一行就可以向上输出。假如,T1 的每一行都可以和 T2 中的一行连接成功,那么 NLJ 至多分别从 T1、T2 中读取 10 行数据。这依然是一个非常典型的 “TP” 式扫描量。
但并不是每个算子都具有流式执行这种性质的,例如数据库中的以下算子都没有流式执行的性质:
-
SORT 算子需要对读取所有的输入数据,完成排序之后才可以向上吐行。
-
HASH JOIN 算子需要读取所有左表的数据,完成 HASH 表的创建之后,才有可能向上吐行。
-
MATERIAL 算子需要读取所有的输入数据,完成物化之后,才可以向上吐行。
流式执行通常对带 ORDER BY LIMIT 的查询具有奇效。单表的流式计划通常需要一个合适的索引,既可以抽取 Range,又可以消除排序;多表的流式计划,通常是一个多层嵌套的 NLJ,并且驱动表选择了合适的索引,可以消除排序。
基于以上对 NLJ 的理解,接下来,我们开始讨论 OceanBase 在单机场景、分布式场景 NLJ 面临的性能挑战。
3. NLJ 性能挑战
3.1 单机多分区场景
在这一节,我们讨论下分区对 NLJ 性能的影响。这里的分区保证 leader(多表的主副本)都在一个节点上。


在上面这个测试中,我们对比了两张表连接进行 NLJ 连接时候的性能。

我们可以看到,当 T2 表从单表变成 “按照 c2 分区的分区表” 后,整个查询的性能下降了 5 倍。这里最直接的原因在于:在每次 Rescan 的过程中,t2 不再是进行一次的数据扫描;而是需要对 50 个分区都进行一次索引扫描。Rescan 的代价是被显著放大了的,这就是分区迭代的代价。
另一方面,当 t2 表从单表变成 “按照 c1 分区的分区表” 时,查询的性能是没有显著变化的。这里的原因在于:查询的连接键是 t1.c1 = t2.c1,和分区键是一致的,在进行 t2 表的 Rescan 时,执行层首先会根据条件下推谓词 t2.c1 = ? 进行一次动态分区裁剪,裁剪之后只有一个分区,而不是 50 个分区,因此 Rescan 代价不会被显著放大。
可以看到,即使我们采用非打散(多表的主副本集中在一台机器)的方式部署:将一张表从单表变更成分区表,查询的执行性能也会受到负面的影响。
3.2 分布式场景
在单机场景中,表的 leader(主副本)在同一个节点上;有的时候为了获得横向扩展的能力,会尝试将 leader 打散到不同的节点上,此时需要依赖 PX(Parallel eXecution)[1]或者 DAS(data access service)[2] 进行节点间的数据交换,多表连接将变成分布式连接。
分布式场景相对于单机场景,复杂度是全面提升的。整体上,包括几个方面:
-
Rescan 可能需要多次访问远程节点上的数据,产生多次 RPC。
-
Rescan 的表是分区表时,需要迭代分区,分区数会进一步放大 Rescan 的次数。
-
分布式 NLJ 依赖数据重分区,通常会破坏掉流式执行的性质。
3.2.1 跨机 Rescan / 分布式 Rescan
打散产生的最大影响是出现了跨机的数据访问。我们还是通过 DBMS_XPLAN 系统包的结果来观察这种影响有多大。
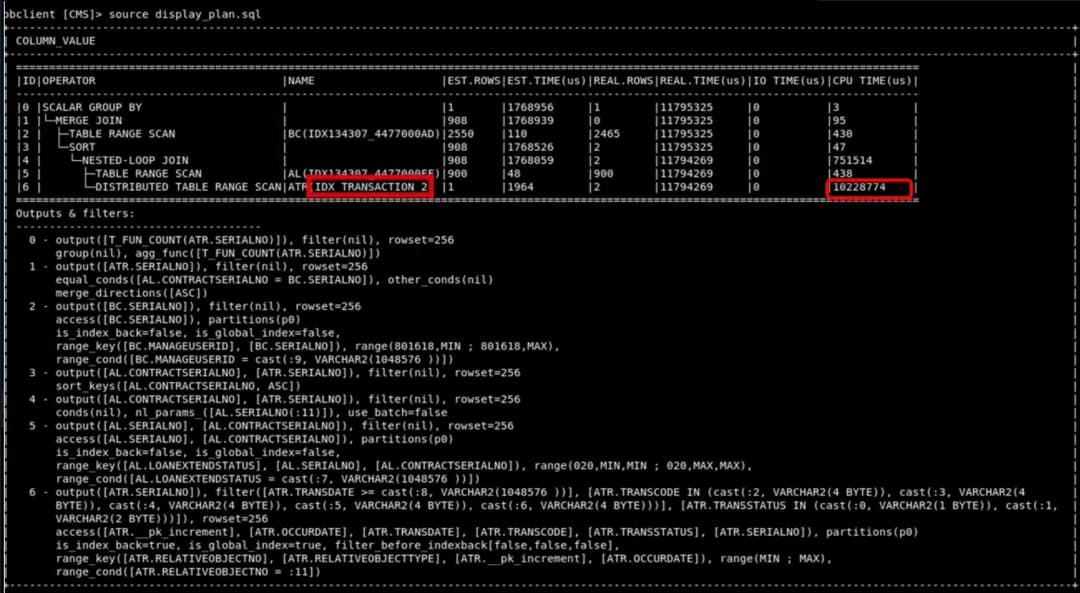
上图的执行,执行耗时明显是由 6 号算子贡献的,相对于其他算子高了两个数量级。这主要因为 5(AL 表)、6 (ATF 表) 号算子访问的表不在同一个机器上。
查询是路由到了 AL 表所在的机器上。在执行这个计划的时候,6 号算子需要去访问远程节点上的数据,会产生远程数据访问 (RPC)。而 6 号执行的次数是和 5 号输出的行数(900) 行数正相关的。因此,6 号实际会触发 900 次的远程数据访问,这产生了非常大的时耗。
针对这种案例,OceanBase 内核层面最基本的优化是尝试合并 6 号算子的多次远程数据访问,通过批量执行 (Batch Rescan,即左表 1000 行攒成一批,一批数据触发一次右表的 Rescan) 的方式,减少 RPC 的数量。当触发 Batch Rescan 之后,6 号算子可以将 900 次远程数据访问合并到一次 RPC 中,该算子的耗时可以降低近 900 倍。整个执行计划的性能将得到极大的提升。
跨机 Rescan 是分布式 NLJ 性能影响最大的因素。 一旦无法通过 Batch Rescan 之类的优化机制减少 RPC,这类查询的性能通常是会出现 2 ~ 3 个数量级的差距的。
3.2.2 流式性质变化
分布式执行第二个比较大的影响是会破坏 NLJ 的流式执行性质。下面这个测例是和前面的测例是几乎完全相同的(表结构,数据量,SQL 形态)。唯一的区别是我们将 t1、t2 打散到了两个不同的节点上。

在这个执行计划中,我们可以看到 6 号算子对 t1 的扫描是真的全表扫描,需要扫 10w 行数据。这是因为:t1 的数据需要通过 4,5 号 Exchange 算子发送到 t2 所在的节点上,这个操作无法流式执行,破坏了整个执行计划的流式性质。 因此,t1 表的扫描无法通过 limit 算子提前终止,导致了全表扫描。
这是一个 PX 场景下,NLJ 左支流式被破坏的案例。在这个计划中,NLJ 右支部分还是流式的,7 号 Table Scan 算子只需要读取 t2 表 10 行数据就可以提前终止。
接下来,我们尝试将上述计划通过 Hint 固化为基于 DAS 的分布式 NLJ 计划。
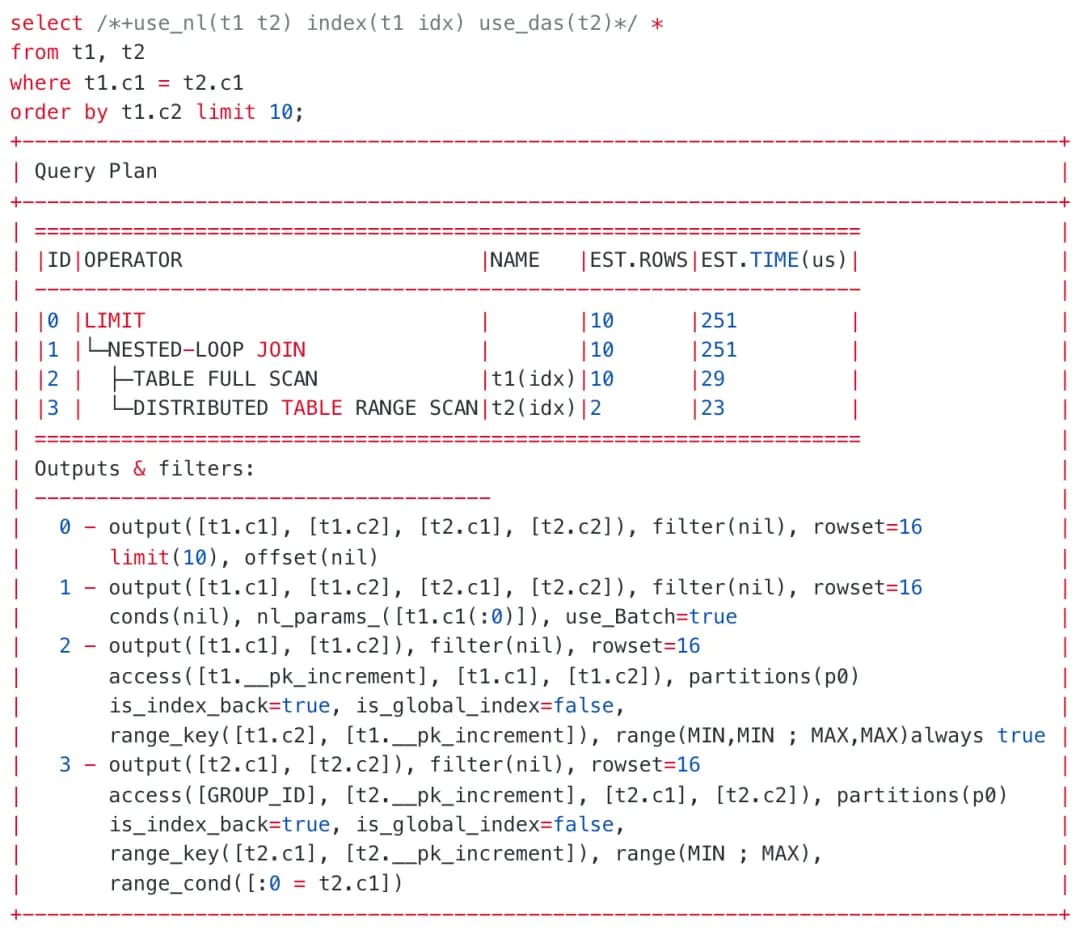
执行计划看上去整体是流式的,但实际上并不完全是。
这个 NLJ 为了保证高效的 Rescan,需要左表积累 1000 行之后,发起对右表的远程 Batch Rescan(计划中的 JOIN 算子会显示 use_Batch=true)。
实际的执行中:
-
2 号 Table Scan 算子会读取 1000 行数据。
-
3 号 Table Scan 算子会通过 DAS 执行,通过一次 RPC,进行 1000 次的 Rescan,每次 Rescan 读取 1 行数据,结果批量拉回本地。
-
最终 1 号 NLJ 算子进行左右两表数据的连接,吐出 10 行之后查询结束。
这里无法达到良好的流式效果是因为需要从远程拉取超出预期数量的 t2 表数据。流式性质的利用主要出现在带 ORDER BY LIMIT、 SEMI JOIN 的查询中。并且仅当左右表连接的结果集很大时,才会产生无法忽略的性能影响。相对前面讨论的跨机 Rescan 问题而言,不能流式这个点,相对来说影响要小很多。
4. 分布式 NLJ 优化技巧
4.1 避免分布式 Rescan
基于 PX 的分布式 NLJ,可以通过适当移动左表的数据来避免右表产生分布式 Rescan。
概括而言有以下几种场景:
- Partition Wise Join

上述这个执行计划,虽然是一个分布式 NLJ。左表和右表都不涉及到跨节点的数据交换。它的执行逻辑是:t1、t2 每个分区的数据先互相完成连接操作,最后再把连接结果拉回本地。
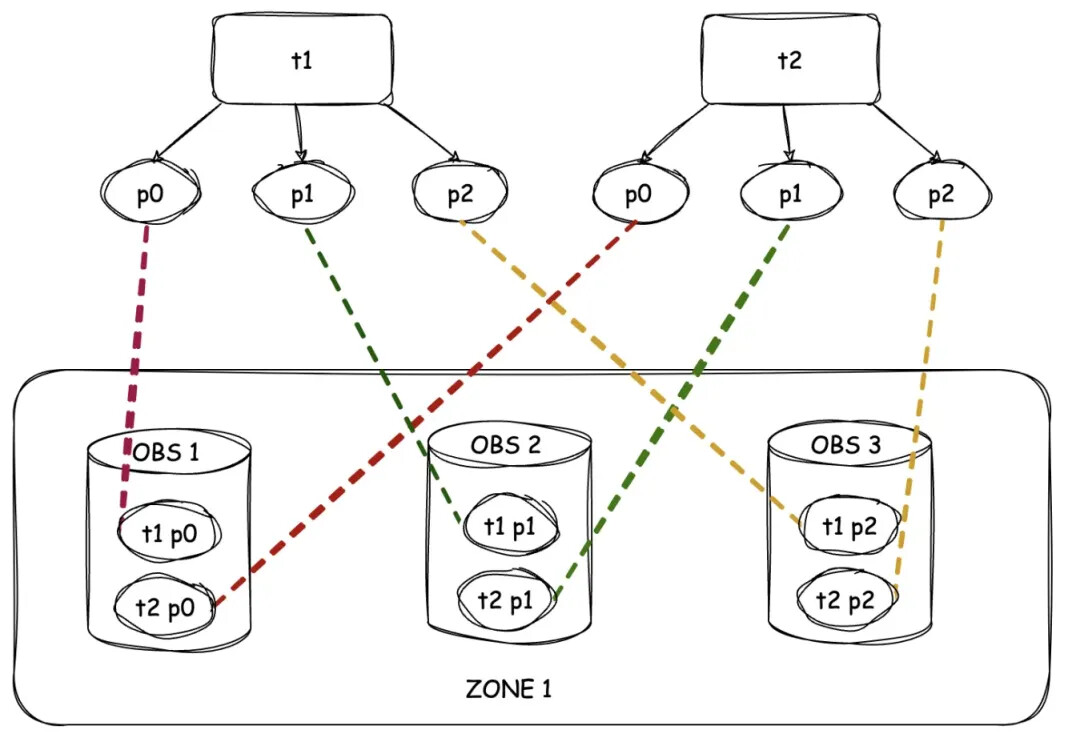
这是一个很理想的分布式 NLJ 形态,左表和右表都不存在跨机数据交换,这在 OceanBase 中被称为 Partition Wise Join。
要调优产生这种计划,关键操作是分区设计和 Tablegroup(表组)[3]设计:
-
左表和右表的分区键需要是连接键。
-
左表和右表分区模式是相同的。
-
左表和右表分区在多个节点上分布也是相同的。
1. PKEY-NONE

上述这个执行计划的执行方式是按照把 t1 的扫描的数据,按照 t2 的分区方式进行分发(3,4 号 Exchange 算子),然后 t1 表的数据和 t2 表的数据进行连接,最后再把连接结果拉回本地。
这是一个相对理想的分布式 NLJ 形态,左表存在一次跨机数据交换,右表不需要跨机访问。要调优产生这种计划,关键操作是分区的设计:右表的分区键需要是连接键。
2. PullToLocal & BC2HOST-NONE

在这个执行计划中,t2 的数据在本地,t1 的数据在远程。
执行的逻辑是直接把 t1 的数据从远程拉回本地,之后的执行流程基本和单机执行没有实质性的区别。这也是一个相对理想的分布式 NLJ,左表存在一次跨机数据交换,右表是 Local Rescan。
调优产生这种计划的关键是:NLJ 右表的数据需要集中在一台机器上,并且查询被路由到了右表所在的机器上。
对这种计划而言,右表是单表时,天然可以保证数据都在一台机器上,问题是很多时候我们无法控制 OBProxy 的路由,无法保证查询是路由到右表所在的机器上。
为了解决这个问题,OceanBase 还有下面这种 BC2HOST 的计划形态。

上面这个执行计划的执行方式是把 t1 的数据 “推送” 到 t2 所在的节点上,NLJ 在 t2 所在的节点上执行,此时对 t2 数据访问会是 Local Rescan。这也是一个相对理想的分布式 NLJ,左表存在一次跨机数据交换,右表是 Local Rescan。
综合 PullToLocal 的计划,产生这类计划的关键点在于:NLJ 右表的数据需要集中在一台机器上(避免 NLJ 的跨机 Rescan)。
4.2 加速分布式 Rescan
在很多复杂场景中,是分布式 Rescan 是无法避免的。
譬如两张分区表 JOIN 时,可能会按照不同的字段进行连接,往往无法保证分区键一定是连接键,分布式 Rescan 也就难以避免了。这时候,就必须正面强化分布式 Rescan 的性能,OceanBase 在这里的技术路径是基于 DAS 的分布式 NLJ。
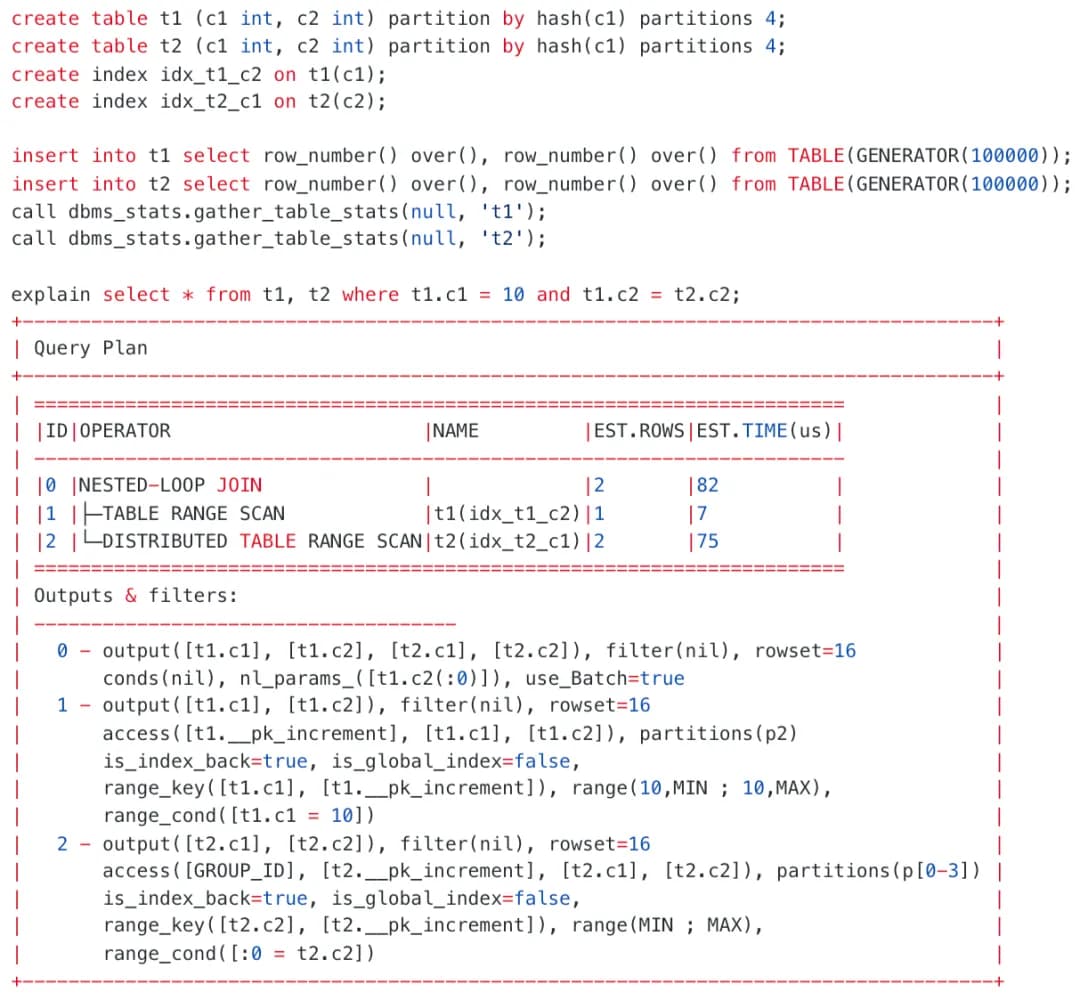
例如,上面这个执行计划,t2 是一个分区表,查询的连接键不是分区键。
逻辑上,t1 的一行可能和 t2 任意一个分区中的数据连接成功,t2 需要进行分布式 Rescan。
针对这种场景,OceanBase 目前的优化方式是上面提到的 Batch Rescan:在一次 RPC 过程中,完成多行数据的 Rescan 操作,从而整体上减少跨机数据访问的次数。此时,在计划中的 NLJ 算子会有 use_Batch=true 标记。
理想的情况下,任意的分布式 Rescan 操作都可以通过 Batch 进行优化。但一些场景下 NLJ 计划的复杂度很高,暂不支持 Batch Rescan 优化,例如:右支不是一个基表扫描,而是一个连接操作。

这是一个执行计划的片段。4 号是一个 NLJ 外连接。它的右支是 54-62 这个计划片段。这个子计划本身又是一个 NLJ。在这种情况下,4 号是无法做 Batch Rescan 的。
4.3 NLJ 优化路径图
综合上面的介绍,可以汇总一下分布式 NLJ 的优化路径:
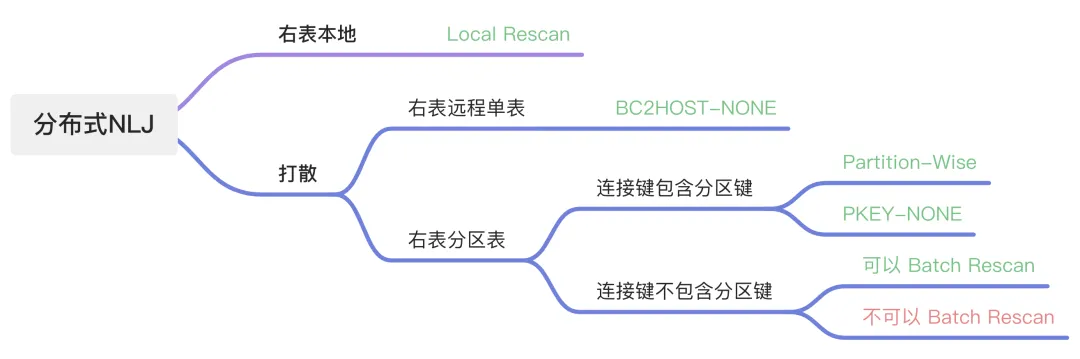
从这个图可以看到,既无法通过 PX 规避分布式 Rescan,也无法使用 DAS Batch Rescan 场景加速时,NLJ 的性能会遇到比较大的挑战。总的来说,这类 SQL 的特征是有相对复杂的子查询,并且子查询中引用了多张表。
5. FAQ
在 OLTP 业务中,分布式 NLJ 因为跨机 Rescan 跑不快的时候,强制改成 HASH JOIN 是不是好的?
改成 HASH JOIN:
-
好处:右表不会反复的 Rescan,在跨机的场景中,也就不会出现反复 Rescan 导致放大远程数据访问的开销。
-
坏处:少了一个 NLJ 条件下推的谓词,当右表的数据量很大的时候,扫描右表可能会慢。
简而言之,HASH JOIN 显著的缺点就是放大了右表扫描的开销,这部分的开销是两方面的,一方面放大 CPU 的开销;另外一方面也会放大 IO 的开销。
很多时候,改成 HASH JOIN 之后并不会比 NLJ 快很多,第二轮调优往往就是加并行(或者打开 Auto DOP),加并行之后,可以投入更多线程资源加速查询的执行。
但这种 HASH JOIN + 并行化的调优方法最大的问题在于:为一个查询投入了过多的计算资源和 I/O 资源。 在 TP 场景下,如果这是一条高频查询,可能会把 IO/CPU 打穿。在 TP 场景中,分布式 NLJ 如果性能不好的时候,改 HASH + 并行的方式并不是一个最佳的调优思路。如果存在大量类似场景需要调优,最好的办法是调整所有表的 leader 在同一个节点上(不进行打散)。

参考资料:
- [1] PX(Parallel eXecution): https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000002013746
- [2] DAS(data access service): https://www.oceanbase.com/knowledge-base/oceanbase-database-1000000000217873?back=kb
- [3] Tablegroup(表组): OceanBase 社区
