

自适应合并是分区级别、自动触发的(不能人工触发)、encoding编码压缩、产生分区级全局快照的行为,但是触发条件是什么呢?
1 个赞
根据文档库中的信息,自适应合并策略的触发条件与 OceanBase 数据库的 LSM-Tree 架构密切相关。以下是关于自适应合并策略触发条件的详细说明:
1. 背景知识
OceanBase 数据库基于 LSM-Tree 架构,数据分为 MemTable 和 SSTable 两部分。当 MemTable 的大小超过一定阈值时,会触发转储操作,生成新的 SSTable。随着转储次数增加或业务低峰期到来,系统会将基线 SSTable 与增量 SSTable 合并为一个 SSTable,这一过程称为 合并。
2. 自适应合并策略的触发条件
自适应合并策略是一种分区级别的自动触发机制,不能通过人工干预触发。其触发条件主要包括以下几点(综合多个文档片段信息得出):
(1) 数据写入压力
- 当某个分区的数据写入量较大,导致
MemTable转储频繁时,可能会触发自适应合并策略。 - 如果增量
SSTable数量过多,系统会评估是否需要进行合并以减少文件数量,优化查询性能。
(2) 存储空间利用率
- 当分区的存储空间利用率较高时,系统可能会触发自适应合并策略,通过压缩和合并数据来释放存储空间。
- 合并过程中会对数据进行两层压缩:第一层是数据库内部基于语义的编码压缩,第二层是基于用户指定压缩算法(如
lz4)的通用压缩。
(3) 业务低峰期
- 在每天的业务低峰期,系统会自动触发自适应合并策略,对分区数据进行合并和优化。
- 这一行为旨在减少对在线业务的影响,同时提升整体查询性能。
(4) 分区级全局快照
- 自适应合并策略会在分区级别生成全局快照,确保合并过程中数据的一致性和完整性。
- 快照的生成时机与数据变化频率、分区状态等因素相关。
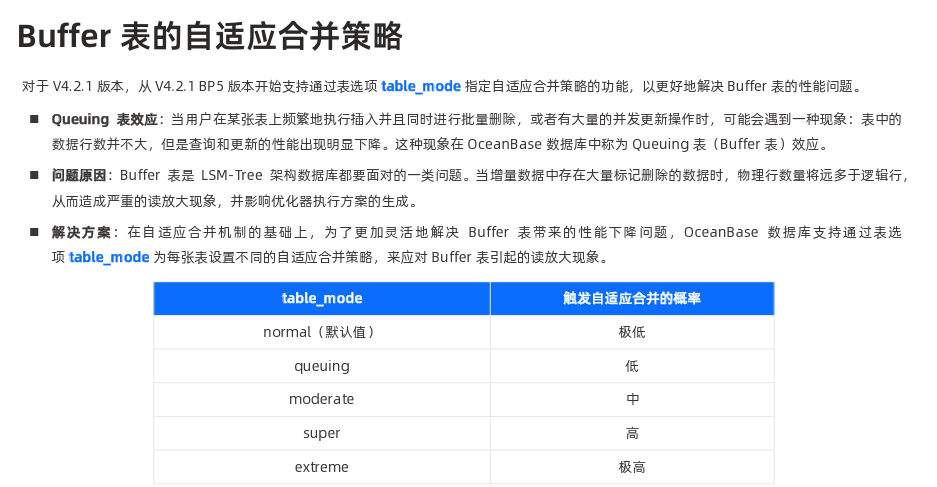
(5) 表模式配置
- 根据 OCR 提取的内容,OceanBase 数据库支持不同的表模式(如
normal、queuing、moderate、super、extreme),这些模式会影响自适应合并策略的行为。 - 不同表模式下的合并策略可能在触发条件、合并频率等方面有所不同。
3. 无法手动触发的原因
自适应合并策略是分区级别的自动化机制,设计初衷是为了减少人工干预,确保系统能够根据实际负载情况动态调整合并行为。因此,该策略不支持手动触发。
4. 参考文档
- 文档标题: OceanBase 数据库性能的影响因素 → 合并与统计信息收集 → 合并
- 文档标题: OceanBase 数据库在 MySQL 模式租户下的扩展功能 → 序列(sequence) → 适用场景
如果您需要更详细的配置信息或特定场景下的触发条件,请参考官方文档中关于合并管理的部分。
详情请参考:
您好,您提到的问题似乎与 OceanBase 没有关联,我无法回答,敬请谅解! 如果您有其他 OceanBase 相关问题,欢迎继续提问。
打卡学习! ![]()
根据文档库中的信息,自适应合并的触发条件可以总结如下:
-
数据写入频率和增量数据量
- 自适应合并会根据分区的数据写入频率以及增量 SSTable 的数量来决定是否触发合并。如果某个分区的增量数据较多,系统会识别到可能存在的查询性能问题,并触发自适应合并以优化查询性能(参考文档:合并管理概述 → 合并的触发方法)。
-
业务低峰期
- 自适应合并通常会在业务低峰期自动触发,以减少对在线业务的影响。这种机制类似于每日合并(Major Compaction),但更加灵活,能够根据实际负载动态调整(参考文档:OceanBase 术语 → H → 合并/每日合并(Major Compaction))。
-
存储空间利用率
- 当分区的存储空间利用率较高时,系统可能会触发自适应合并,通过压缩和合并数据来释放存储空间。合并过程中会对数据进行两层压缩:第一层是基于语义的编码压缩,第二层是基于用户指定压缩算法(如 lz4)的通用压缩(参考文档:OceanBase 数据库性能的影响因素 → 合并与统计信息收集 → 合并)。
-
查询性能优化需求
- 自适应合并会实时采集并统计用户的查询、写入等信息,识别可能导致查询变慢的场景,并自适应地调度合并任务。例如,它可以避免一部分 Buffer 表问题的出现,优化导数场景下的查询性能(参考文档:自适应合并)。
-
分区级全局快照
- 自适应合并会在分区级别生成全局快照,确保合并过程中数据的一致性和完整性。快照的生成时机与数据变化频率、分区状态等因素相关(参考文档:OceanBase 术语 → H → 合并/每日合并(Major Compaction))。
注意事项
- 自适应合并是自动触发的,不能通过人工干预触发。
- 如果需要关闭自适应合并功能,建议联系技术支持人员协助处理,因为隐藏配置项(如以
_开头的配置项)仅供开发人员在故障排查或紧急运维时使用(参考文档:自适应合并 → 注意事项)。
如果您还有其他疑问,请随时提问!
检索到的文档如下:
触发规则
当分区 Leader 满足一定条件时,系统就会自动为该分区及 Follower 副本调度自适应合并。自适应合并的触发规则如下:
- 系统通过分析一段时间内分区的统计信息,获取到该分区查询和转储的次数以及增量数据中 Insert 行数的占比,确认该场景是否为导数场景。如果是导数场景,则对该分区触发自适应合并。
- 系统通过分析一段时间内分区的统计信息,获取到该分区转储的次数以及增量数据中更新和删除行的占比,确认该场景是否为导数场景。如果是导数场景,则对该分区触发自适应合并。
- 系统通过统计分区增量数据的总行数,确认该场景是否为持续写入场景,如果是持续写入场景,系统对该分区触发自适应合并。
- 系统通过查询扫描的数据量与实际有效数据的比例,确认针对该分区的查询是否为慢查询,如果为慢查询,系统对该分区触发自适应合并。