【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】
【 使用版本 】
【问题描述】清晰明确描述问题
【复现路径】问题出现前后相关操作
最近几天老是出现这样的报错,如下:

memory_limit=0M
memory_limit_percentage=95
机器分配情况:

看着都没啥问题,这个要从哪分析呢?
【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】
【 使用版本 】
【问题描述】清晰明确描述问题
【复现路径】问题出现前后相关操作
最近几天老是出现这样的报错,如下:
memory_limit=0M
memory_limit_percentage=95
机器分配情况:
看着都没啥问题,这个要从哪分析呢?
会不会是内存管理参数方面配置的效率,特别是内核参数那一部分
比如,是哪呢?
当前集群版本和架构是啥样的
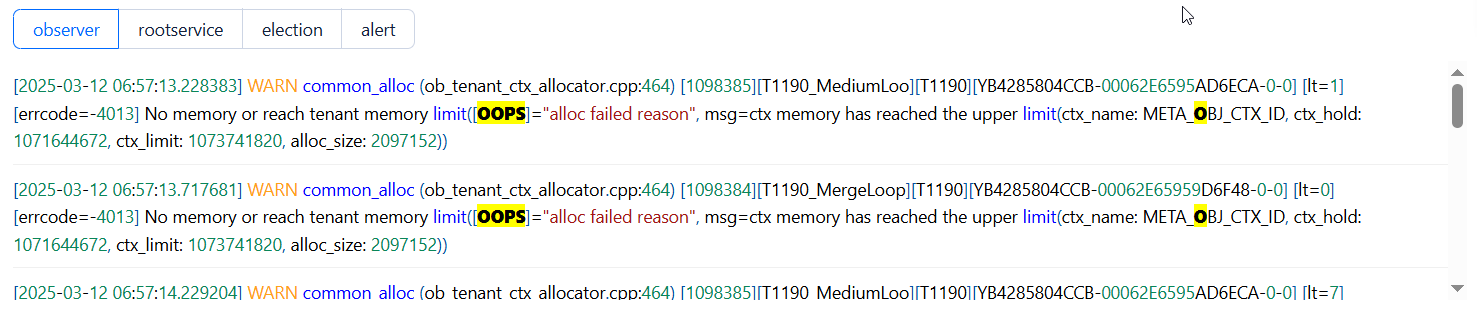
到日志中查一下最早的4013报错
![]()
通过trace_id去看看日志,是干了啥报了这个错,别一上来就看你主机资源,误导了自己。
trace_id 搜出来,也是 上面那个图了,没其他得了
你数据库的分区数是多少
4.0租户单个unit内的分区数建议每1GB不超过2w,例如4G租户内存建议不超过8w分区
你好,目前问题是租户内存超限了,从日志来看,
上下文ctx_hold的内存达到限制了大小为1G,尝试分配的alloc_size = 2097(2kb),没有更多内存可以分配导致出错,meta object应该是表结构或者索引表更较多吧。
1、截图的是metadb,日志中的的集群名为:obcluster_core,是否存在1190租户,看下租户规格多大
2、查询下租户参数: ob_sql_work_area_percentage ,如果是默认的5,建议调大至10或者15,可以临时解决这个问题
3、集群资源充足的话,建议直接扩容租户
4、GV$OB_MEMORY看下租户内存消耗
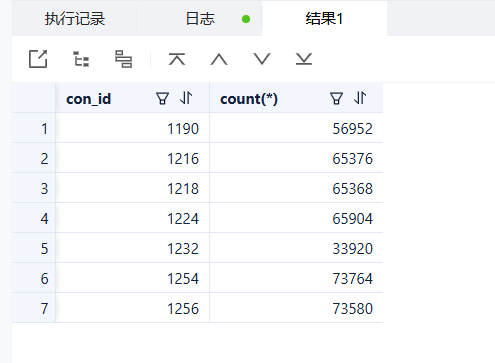
上图是这台服务器中存在的租户分区数,
配置都是2C16G的
好的,1190,租户,应该没用了,我可以删除掉
确保1190租户不再使用,删除租户后观察告警是否自动恢复,一般是五分钟。
其他租户也可以关注下,规格一致情况下,从分区数来看,其他租户可能负载会比1190更高些。
gv$ob_memory关注租户的内存消耗,以及租户参数ob_sql_work_area_percentage,存在租户的内存模块使用接近限制的话,可以调大参数或者扩大租户内存。
通过日志的方式也可以看到哪些模块占用较多内存。
grep ‘malloc_allocator.*tenant: <tenant_id>’ observer.log. -A 20
select * from GV$OB_MEMORY where tenant_id=1190;
看一下哪个模块占比最大
嗯,跟业务确认,1190,已经删除了,告警已经没有了
好的,这个方法可以,下次遇到,看看
下次遇到,分析看看