rocH
2025 年3 月 6 日 15:46
#1
【 使用环境 】生产环境
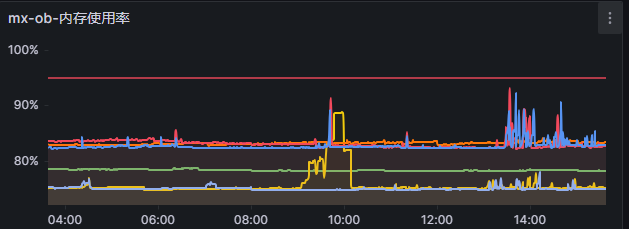
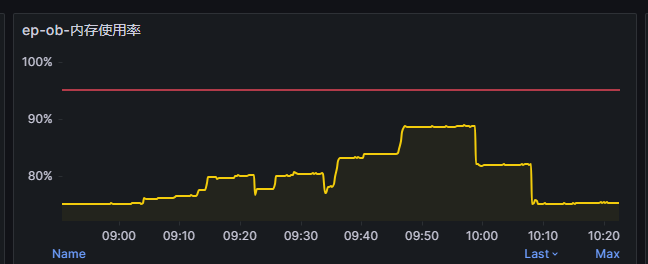
查看集群监控,黄线对应的机器内存使用率未有变化
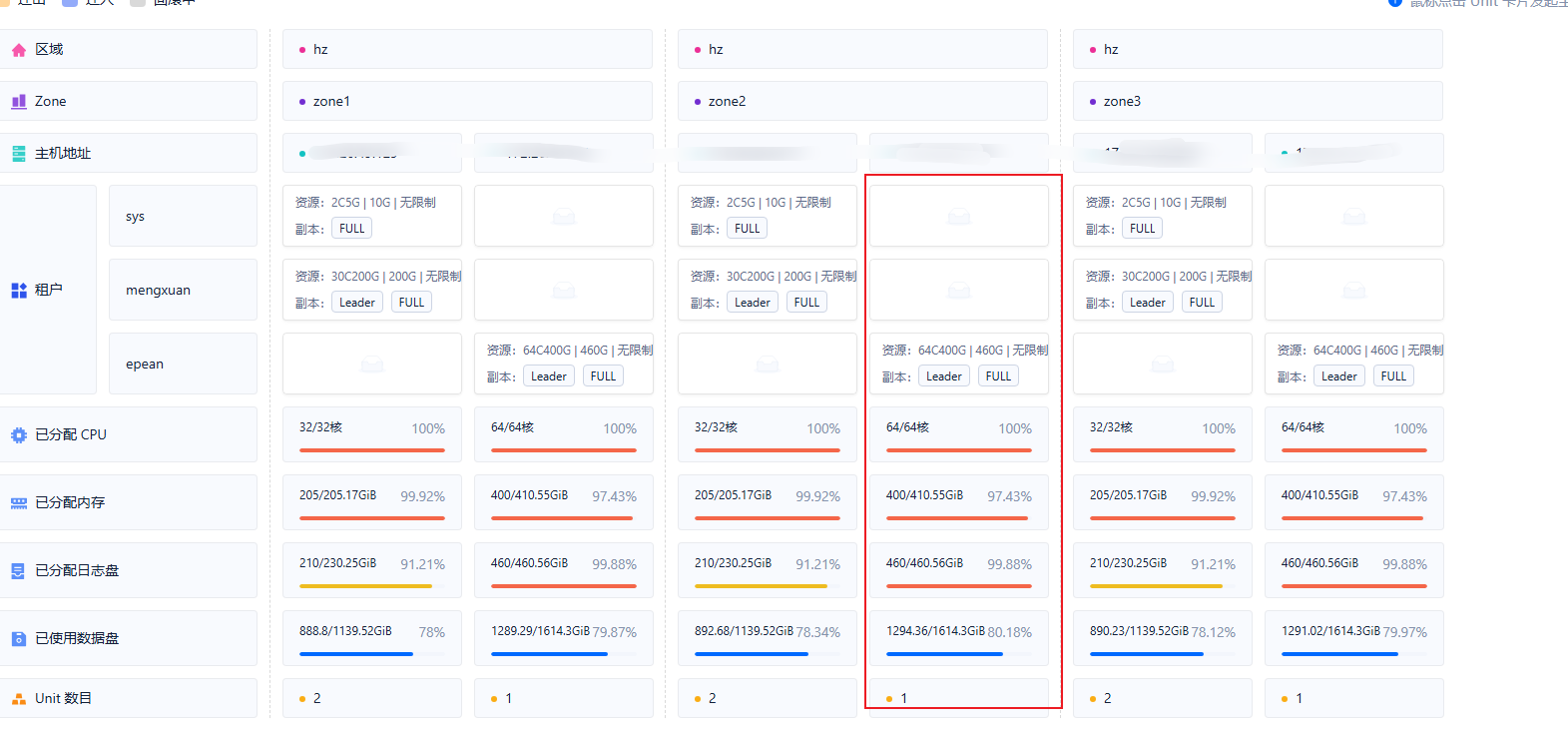
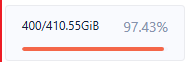
下图为集群配置。红色框起来的机器为内存暴增的机器。物理机内存规格分别为256G和512G。分配给租户使用的内存都为总物理内存的75%左右
而且图一中,在下午1点到2点期间还有其他2台机器存在突然爆内存的情况。
上述所有机器都仅运行了oceanbase、obagent服务
1 个赞
淇铭
2025 年3 月 6 日 15:51
#3
把暴涨的这个时间段的observer.log日志发一下 几个节点的日志都发一下
辞霜
2025 年3 月 6 日 15:51
#4
rocH
2025 年3 月 6 日 15:52
#5
这台机器实际上是有512G内存的。 只是参数设置了集群可分配内存为410G
淇铭
2025 年3 月 6 日 15:54
#6
obdiag gather scene run --scene=observer.memory --from “2022-06-30 16:25:00” --to “2022-06-30 18:30:00”https://www.oceanbase.com/docs/common-obdiag-cn-1000000002200435
辞霜
2025 年3 月 6 日 16:01
#8
麻烦参考楼上淇铭老师的使用obdiag收集一下
rocH
2025 年3 月 6 日 16:03
#9
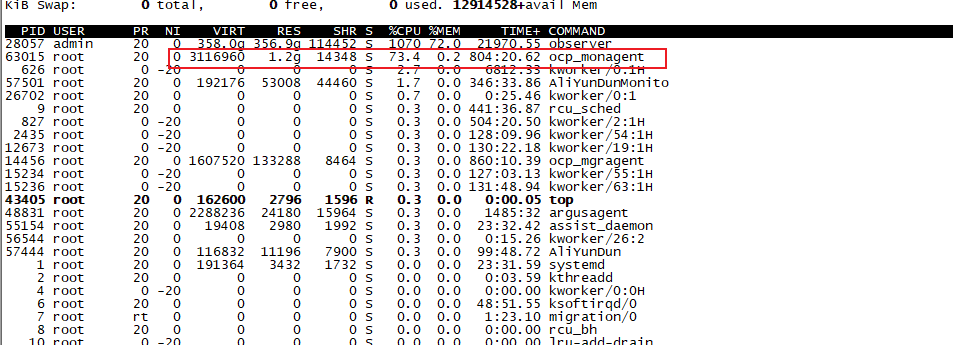
obproxy是部署在节点之外的机器上的。所有节点除了 oceanbase和agent服务,没有其他服务。
常规ocp_monagent 占用内存大概2g不到。
靖顺
2025 年3 月 6 日 16:14
#10
确认下是不是2025年03-06 9:00 - 10:10 这个时间段ob机器上的日志还在不在。
说明:obdiag gather scene run --scene=observer.memory 本身没有加内存高低的判定策略在,你执行的时候他会获取对应时间的日志、内存信息和主机等信息,所以没收到日志得看下是不是日志已经过期清理了
淇铭
2025 年3 月 6 日 16:31
#12
rocH:
observer.log.zip
看一下日志设置的级别 看着设置的不是wdiag级别呀
辞霜
2025 年3 月 6 日 16:52
#15
这边不允许访问你给的链接,文件麻烦压缩一下发出来。
rocH
2025 年3 月 6 日 17:02
#16
辞霜
2025 年3 月 6 日 17:30
#17
辞霜
2025 年3 月 7 日 14:27
#18
[2025-03-06 09:28:43.663903] WDIAG [STORAGE] ~ObOccamTimeGuard (ob_occam_time_guard.h:269) [29062][T1004_MINOR_EXE][T1004][YB42AC1EE0B2-00062B7E71BAE341-0-0] [lt=11][errcode=0] cost too much time:(null):(null), (*this=|threshold=60.00s|start at 09:27:43.602|5=59.86s|6=196.58ms|7=101us|9=3.56ms|12=2us|total=60.06s)
你好查看日志发现,你当时的数据库应该执行很慢。可以看一下ocp的sql诊断看看是不是业务积压导致的内存突增
辞霜
2025 年3 月 13 日 18:13
#19
你好 近期还有该问题,建议日志等级设置低一点,之前的日志看不到相关内存信息