

【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】ob
【 使用版本 】4.2.1-10BP
【问题描述】
集群已正常运行半年
1-1-1集群。 仅其中一台出现MEMSTORE卡转储问题。
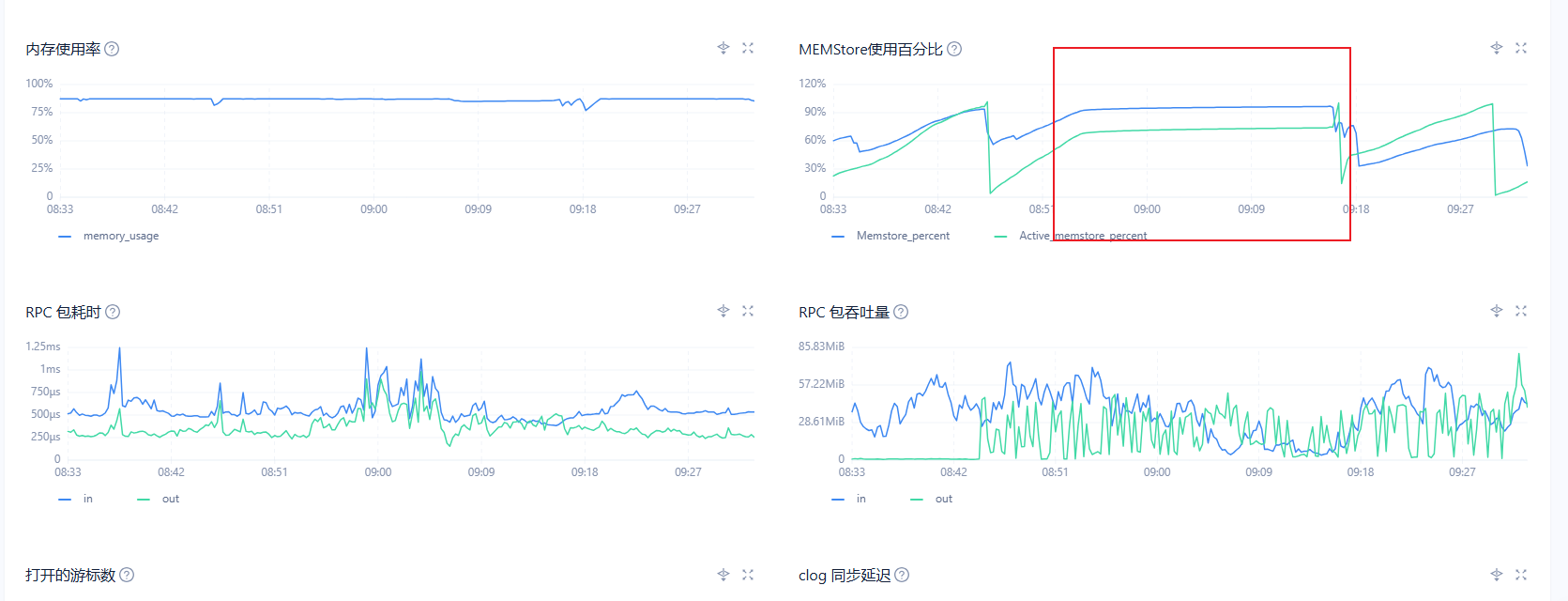
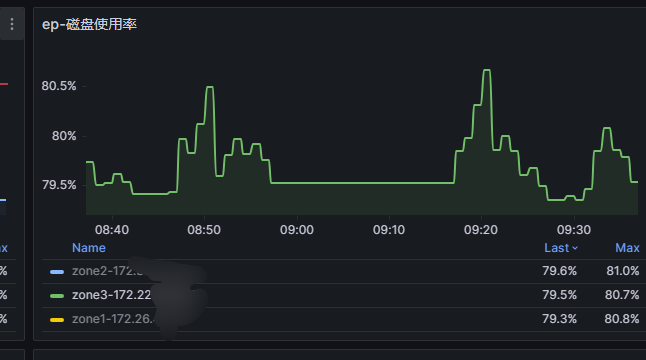
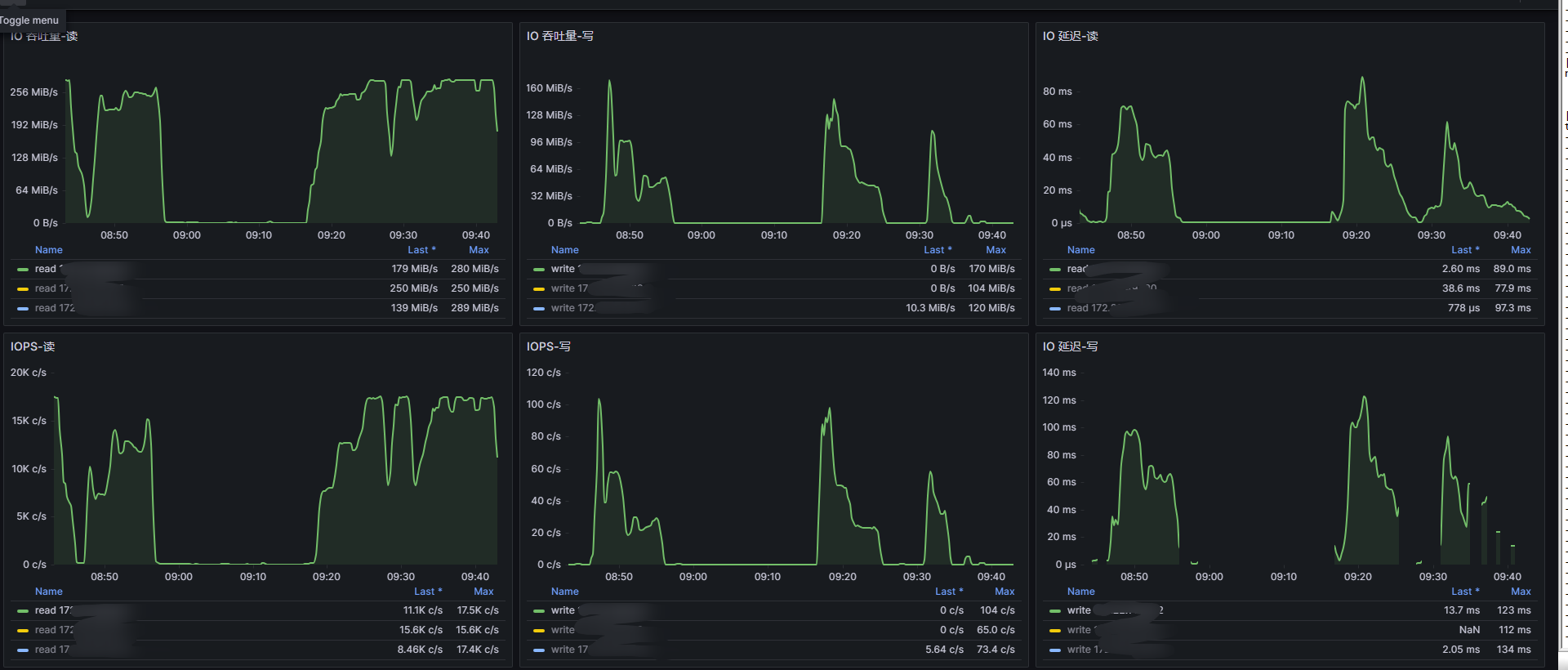
查看ob日志,逐个功能点分析
1 个赞
查一下 下面的信息 三个节点的rootservice.log和observer.log日志发一下
目的:判断是否存在冻结异常,如长时间挂住无法冻结完成。
select svr_ip,tenant_id, ls_id, unix_timestamp(start_time),state,diagnose_info
from __all_virtual_minor_freeze_info
where (unix_timestamp(now()) - unix_timestamp(start_time) > 10 * 60) and state < 3 and state >= 1;
目的:判断是否存在已经满足转储条件的memtable,但是长时间无法转储。
freeze_ts指明了memtable冻结时间。
freeze_state指明了当前memtable状态。
select svr_ip,tenant_id, ls_id, freeze_ts, freeze_state, compaction_info_list from __all_virtual_memstore_info where (unix_timestamp(now()) - freeze_ts / 1000 / 1000 > 10 * 60) and freeze_state = “READY_FOR_FLUSH”;
2 个赞
先用敏捷诊断工具obdiag拿一份 巡检报告回来,看下集群情况:https://www.oceanbase.com/docs/common-obdiag-cn-1000000002200479
2 个赞

1.查看下该节点是否存在未提交的事务。
SELECT * FROM __all_virtual_trans_stat WHERE state = 0;
2.确认下磁盘使用情况。看看使用率目前多少
3.看一下哪个内存模块占用的多
SELECT * FROM gv$ob_memstore;
SELECT * FROM oceanbase.GV$OB_MEMORY
WHERE tenant_id = <租户ID> AND svr_ip = '<服务器IP>' AND svr_port = <端口号>;
当前是已经恢复了吧?这个需要在卡住时候查询。
2 个赞
已经恢复了
2 个赞
可以按照楼上发的 obdiag巡检 可以快速定位问题日志信息 如果无数据 代表目前没有长时间挂住无法冻结完的 也没有长时间无法转储。
2 个赞
我这边表的主副本大都在另外一台机器上。这台机器是个从副本。 也会存在由于长事务未提交,导致无法转储的问题?
2 个赞
活跃事务会持有 MemTable 的引用,如果事务长时间不结束,MemTable 冻结之后无法释放,可能导致内存写满 所以就有了MEMSTORE爆满问题
2 个赞
我建了个大表组。 基本所有表都在这个表组里面。所有表主副本都在另一台机器上。
出现卡转储的机器,是个从副本。开启事务也只会对主副本有影响吧
1 个赞
事务确实会影响主副本。如果想将主副本放一起,直接设置租户优先级即可,primary zone
那就需要收集下这个了内存模块占用
SELECT * FROM oceanbase.GV$OB_MEMORY
WHERE tenant_id = <租户ID> AND svr_ip = ‘<服务器IP>’ AND svr_port = <端口号>;
1 个赞