【 使用环境 】生产环境 or 测试环境
【 使用版本 】4.0+
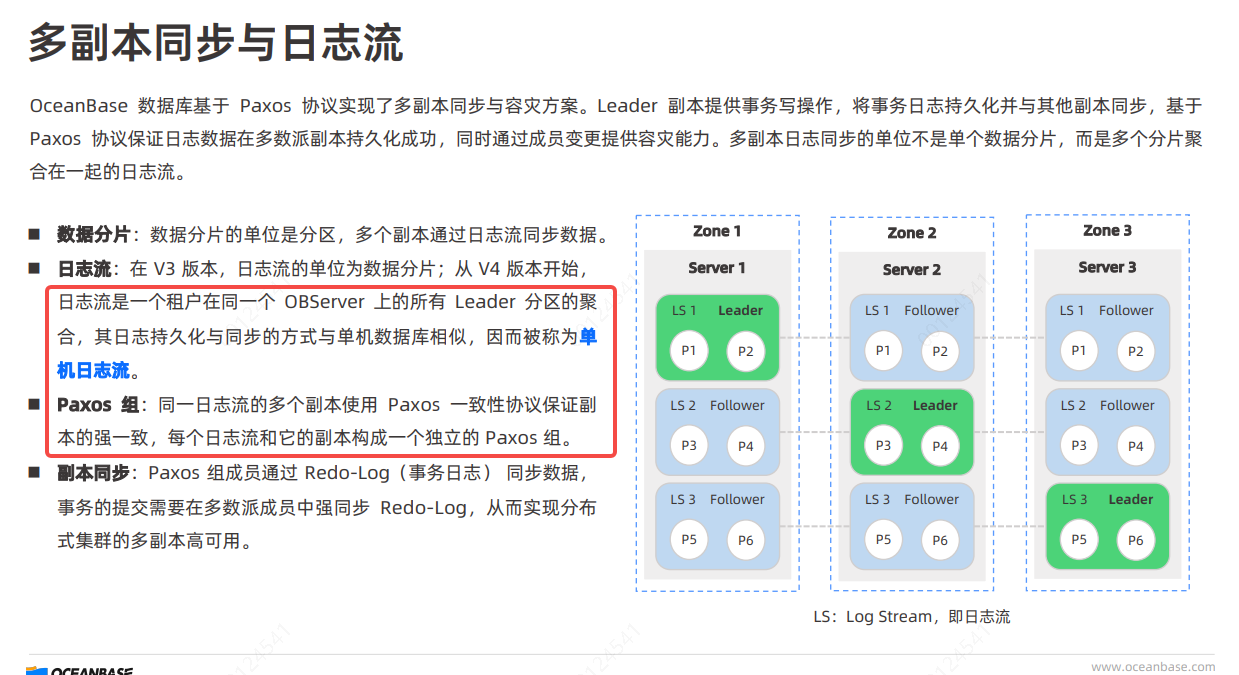
4.0最大改变之一就是日志流,从而实现单机承载从之前的3-8万个表,提升到100万级个表。
根据如下PPT内容,我的理解如下,确认一下。
如果一个集群是3-3-3,数据量足够多,Zone 优先级=random。那9台observer,每台都leader分区数据,也就说每台observer都是单机日志流,就是有9个日志流,分别也对应9个paxos同步组。
这样理解有问题吗?
【 使用环境 】生产环境 or 测试环境
【 使用版本 】4.0+
4.0最大改变之一就是日志流,从而实现单机承载从之前的3-8万个表,提升到100万级个表。
根据如下PPT内容,我的理解如下,确认一下。
如果一个集群是3-3-3,数据量足够多,Zone 优先级=random。那9台observer,每台都leader分区数据,也就说每台observer都是单机日志流,就是有9个日志流,分别也对应9个paxos同步组。
这样理解有问题吗?
下面是我总结的关于你这个问题的回答,期望对你有所帮助
在了解日志流的概念之前,有必要去了解下面三个概念
| Partition(分区) | 用户创建的逻辑对象 | |
|---|---|---|
| Tablelet(分片) | 承载数据的物理存储单位,与分区一一对应,数据均衡最小单元 | |
| LS(日志流 Log Stream) | Tablelet 容器,支持添加和管理。Tablelet 数据,允许 Tablelet 在不同日志流之前转移(Transfer),paxos 实现高可用 |
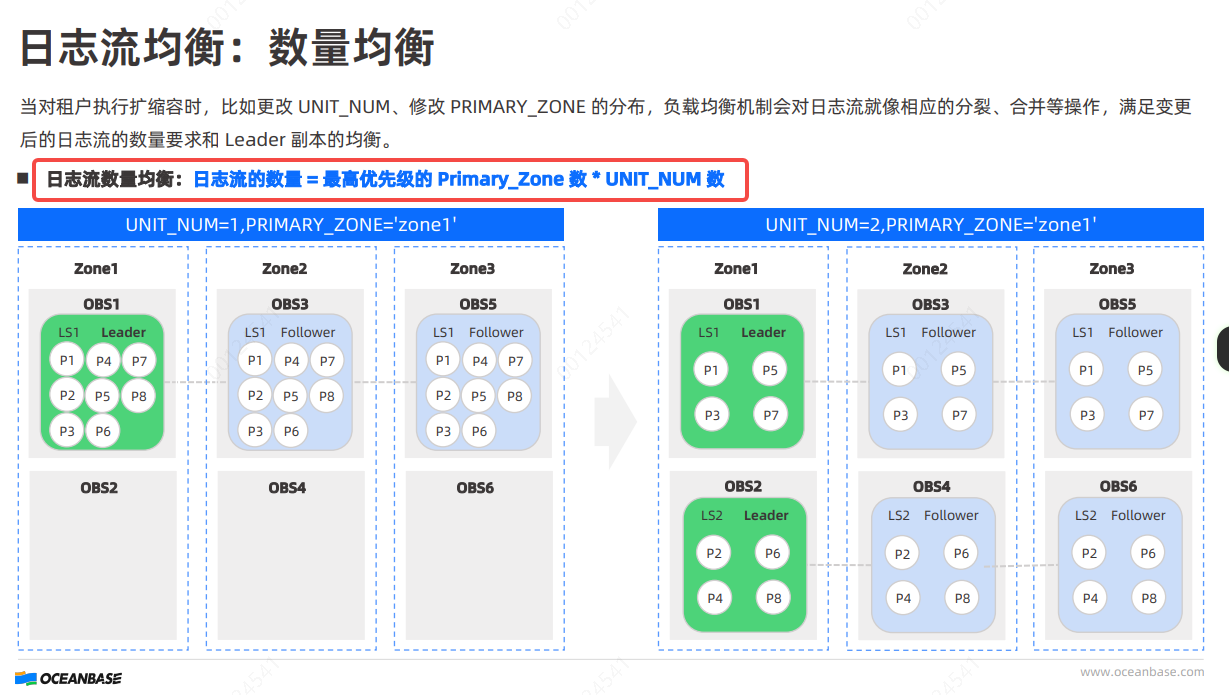
关于日志流数量OB是有一个计算公式的
LS_num=unit_num![]() first_level_primary_zone_num(第一优先级副本)
first_level_primary_zone_num(第一优先级副本)
也就是说日志流数量取决于unit数量,还有就是第一优先级的zone
还有下面给出一个例子说明这个优先级从zone1>zone2>zone3为最高优先级变化为random,但是9个日志流不是绝对的还是取决于这边的分区数量还有就是tablegroup规则
对于不同的 primary_zone 设置,查看日志流分布的 SQL 语句和结果如下:
obclient[SYS]> select ls_id,zone,role from dba_ob_ls_locations where role='LEADER';
| LS ID | ZONE | ROLE |
|---|---|---|
| 1 | z 1 | LEADER |
| 1001 | z 1 | LEADER |
obclient[SYS]> select ls_id,zone,role from dba_ob_ls_locations where role='LEADER';
| LS ID | ZONE | ROLE |
|---|---|---|
| 1 | z 1 | LEADER |
| 1001 | z 1 | LEADER |
| 1002 | z 2 | LEADER |
| 1003 | z 3 | LEADER |
LS_num=unit_num![]() first_level_primary_zone_num(第一优先级副本)
first_level_primary_zone_num(第一优先级副本)
也就是说日志流数量取决于unit数量,还有就是第一优先级的zone
恩,之前理解的不严谨,跟据这个公式理解就对,不是按observer,而是按unit数量。
您好,根据提问我想跟着请教一个问题。
提问中的单机日志流的数量是9个,这样的理解是对的吗?
我不是特别理解在4.x版本中的日志流和单机日志流的关系
单机环境一个租户就一个日志流
单机环境一个租户就一个日志流,这个日志流的数量没什么问题,那么这个日志流叫单机日志流吗?
提问里的3-3-3环境,primiary zone为random的场景下,这9个日志流能被叫做9个单机日志流吗?
就是日志流
单机日志流事务是指在OceanBase数据库中,当事务涉及的日志流Leader全部位于同一台Server上时的事务处理模型。具体可以分为两种情况:
本地单日志流事务:这是最简单的事务模型,要求事务涉及的操作总共只涉及一个日志流,并且该日志流的Leader与创建Session的Server相同。这种情况下,事务提交采用了高度优化的方式,以确保高效性。(参考自“本地事务 → 单日志流事务”章节)
本地多日志流事务:类似于本地单日志流事务,但涉及到多个日志流,这些日志流的Leader必须在同一台Server上,并且这个Server也是创建Session的Server。尽管这本质上是分布式事务,但由于所有参与者副本都分布在同一台机器上,OceanBase对此类事务进行了特别优化,从而提高了性能。(参考自“本地事务 → 单机多日志流事务”章节)
综上所述,在单机环境中,如果事务所涉及的所有日志流Leader都在同一台Server上,则该事务将被归类为单机日志流事务,并享受相应的性能优化。
官方大佬。我就是想理解提问中图片中描述的,“日志流是一个租户在同一个OBServer上的所有Leader分区的聚合,其日志持久化与同步的方式与单机数据库相似,因而被成为单机日志流”这句话,日志流和单机日志流是能画上等号的对吗?
是一个东西,这个图应该是OBCP的培训资料,官网并未明确单机日志流这种称呼都是称为日志流
好的,感谢
主副分区同步好像是通过日志流同步的,参与paxos选举
日志流的个数决定与需要提供读写节点的个数,比如3-3-3的集群,要想9台服务器都提供读写的服务,那么日志流的个数就是9
根据文档库中的信息,您的理解存在一些偏差。以下是详细的解释:
日志流(Log Stream, LS)和Paxos组的关系:
关于集群配置3-3-3的理解:
日志流数量的决定因素:
UNIT_NUM和PRIMARY_ZONE等参数决定。当对租户执行扩缩容操作时,如更改UNIT_NUM或修改PRIMARY_ZONE的分布,负载均衡机制会对日志流进行相应的分裂、合并等操作,以满足变更后的日志流数量要求和Leader副本的均衡。参考文档:负载均衡。综上所述,您的理解中提到“9台observer,每台都leader分区数据,也就说每台observer都是单机日志流,就是有9个日志流”的说法是不准确的。实际上,日志流的数量和分布更加复杂,依赖于多种因素,并且Leader副本会在所有Observer之间尽可能均匀分布,以确保系统的高可用性和性能优化。
详情请参考: