

【 使用环境 】测试环境
【 OB or 其他组件 】5台主机:3台OBServer+1台OCP+1台ODP
【 使用版本 】all-in-one安装包4.3.3版本, ARM-el7
【 信息补充】
tpch参考链接1:https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000001428761
tpch参考链接2:https://www.oceanbase.com/product/oceanbase-database-community-rn/releaseNote#V4.3.3
使用链接1提供的手动tpch步骤、建表语句、生成数据、导入数据、tpch查询语句
使用链接2提供的调优参数,sys租户和tpch租户都是、硬件规格、租户规格均按照要求设置,只是没有用链接2提到的云盘,使用的是本地nvme磁盘,日志盘和数据盘分开,且都是nvme,cpu、内存、磁盘容量都足够
注:所有的OBServer和ODP是nvme磁盘,OCP是sata盘
【tpch预期】
使用目前的3节点集群复现6+秒的100G_tpch
【tpch本地现状】
1.根基链接1提供的步骤+链接2的调优参数,单节点(只有一个OBServer)可以跑到16.8秒
2.基于单节点的经验,预期3节点只需2.8倍的提升就能达到6秒,但实际跑出17.5秒
【提问诉求】
1.想知道为何同样的配置相同的操作下,为什么3节点反而不如单节点的表现?
2.该如何复现OB4.3.3三节点100G_tpch达到6秒的水平
1 个赞
数据库的安装步骤:
1.安装obd,all-in-one里面执行sh bin/install.sh
2.obd web,部署OCP、OBServer
3.通过OCP部署ODP
2 个赞
压测首先要保证observer节点cpu跑满:
- 先查看租户cpu和内存是否足够:
select * from oceanbase.dba_ob_tenants; - 通过top查看cpu使用率是否达到租户cpu和机器上限,如果没有,top -H看看子线程是否打满;
- 如果某些子线程占用100%,那么可能是该线程成为瓶颈;
- 如果没有线程是瓶颈,那很可能是发送到observer的请求压力不够,比如obproxy的瓶颈(可以尝试直连observer的leader测试);
- 也可能是硬件瓶颈,比如网卡虽然带宽很高,但网卡队列数量过低,可以通过以下命令增加:sudo ethtool -L eth0 combined 4;或者磁盘性能不足,但一般高性能SSD就够了;
observer的CPU跑满之后,再考虑tpch的参数是否合理,observer集群的配置和租户的配置是否合适。
2 个赞
先用敏捷诊断工具obdiag拿一份巡检报告回来看看集群本身有没有啥不优的点,
全量巡检 (最常用)
obdiag check run
https://www.oceanbase.com/docs/common-obdiag-cn-1000000002200479
1 个赞
感谢回复,有几个疑问:
1.保证observer节点cpu跑满,怎么保证呢?如果top发现没跑满,该怎么办呢?
另外,根据链接2,规格要求是32c256g 机器,即使我的机器上有更多核心,但只分配32是足够的吧?
2.可能是发送到observer的请求压力不够,这个怎么感知?压力不够该怎么办?
3.提到的硬件瓶颈我会检查一下,但是不太像是硬件的问题
1 个赞
1、那就是客户端给的压力不够
2、建议直连leader测一下试试。同时检查一下tpch客户端和observer所在机器的cpu核数:lscpu
leader的IP地址可以通过日志流的位置判断:select * from __all_virtual_ls_info where tenant_id = 1002 and ls_state=‘leader’;
3、检查单节点压测的时候磁盘性能
1 个赞
内存足够,资源跟上,参数优化
1 个赞
方针是明确的,细节是不知道哪不对
1 个赞
1.忘了说了,最初直连leader跑过,18秒,以为是没有ODP的缘故,结果有了ODP还这样
2.sql查询结果
±-------±---------±----------±------±-------------±---------±-------------±--------------------±-------------±--------------------±---------------±---------------±------------±-----------------------------±-------------±-----------±------------------------+
| svr_ip | svr_port | tenant_id | ls_id | replica_type | ls_state | tablet_count | weak_read_scn | need_rebuild | checkpoint_scn | checkpoint_lsn | migrate_status | rebuild_seq | tablet_change_checkpoint_scn | transfer_scn | tx_blocked | required_data_disk_size |
±-------±---------±----------±------±-------------±---------±-------------±--------------------±-------------±--------------------±---------------±---------------±------------±-----------------------------±-------------±-----------±------------------------+
| xxx.67 | 2882 | 1002 | 1002 | FULL | LEADER | 580 | 1739860061145385000 | NO | 1739815214564089005 | 102670295040 | 0 | 0 | 1739782239317853009 | 0 | 0 | 12895363072 |
| xxx.69 | 2882 | 1002 | 1003 | FULL | LEADER | 579 | 1739860060809929003 | NO | 1739815316979905004 | 102536085504 | 0 | 0 | 1739782225447500012 | 0 | 0 | 12718813184 |
| xxx.65 | 2882 | 1002 | 1 | FULL | LEADER | 690 | 1739860060813087002 | NO | 1739815201858738000 | 134209536 | 0 | 0 | 1739777633257055001 | 0 | 0 | 29208576 |
| xxx.65 | 2882 | 1002 | 1001 | FULL | LEADER | 580 | 1739860060813087002 | NO | 1739815231263765001 | 102670295040 | 0 | 0 | 1739782230477037004 | 0 | 0 | 12988399616 |
±-------±---------±----------±------±-------------±---------±-------------±--------------------±-------------±--------------------±---------------±---------------±------------±-----------------------------±-------------±-----------±------------------------+
1 个赞
所有的机器都是128核的
1 个赞
参考文档中的机型是ecs.r8i.8xlarge,属于性能比较好的机型;
系统是 Alibaba Cloud Linux 3 也是比较新的系统,相对el7来说性能可能更好;
另外ob在x86上的表现比arm好20%~30%,这个是正常的。
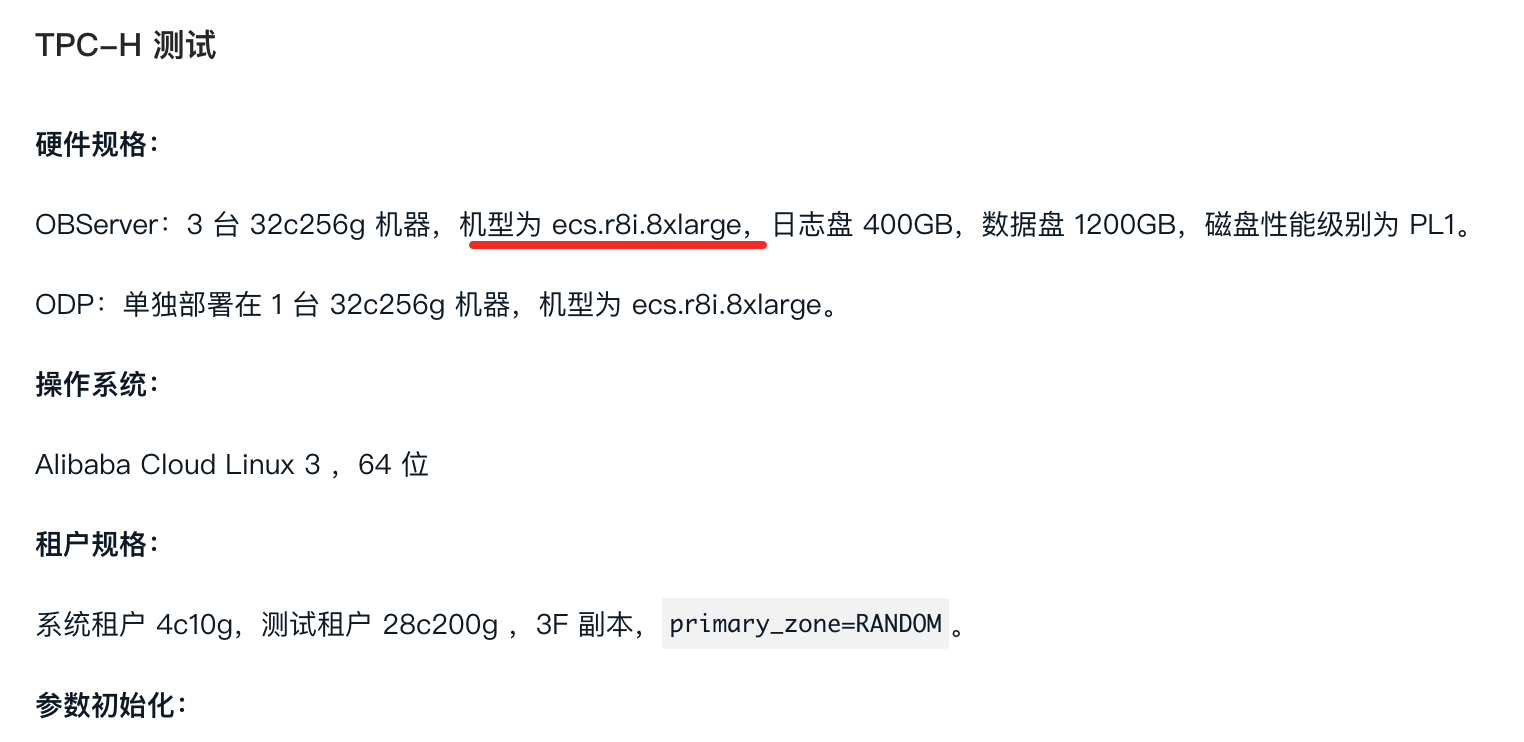
可否提供一下你是用的机器型号呢,执行:lscpu
1 个赞
$ lscpu
Architecture: aarch64
CPU op-mode(s): 64-bit
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Thread(s) per core: 1
Core(s) per socket: 64
Socket(s): 2
NUMA node(s): 4
Vendor ID: HiSilicon
Model: 0
Model name: Kunpeng-920
Stepping: 0x1
CPU MHz: 2600.000
CPU max MHz: 2600.0000
CPU min MHz: 200.0000
BogoMIPS: 200.00
L1d cache: 8 MiB
L1i cache: 8 MiB
L2 cache: 64 MiB
L3 cache: 128 MiB
NUMA node0 CPU(s): 0-31
NUMA node1 CPU(s): 32-63
NUMA node2 CPU(s): 64-95
NUMA node3 CPU(s): 96-127
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Mitigation; __user pointer sanitization
Vulnerability Spectre v2: Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm jscvt fcma dcpop asimddp asimdfhm
ecs.r8i.8xlarge 机型,cpu 基频通常在2.7 GHz到3.5 GHz之间,全核睿频可达到3.5 GHz或更高,相比2.6GHz主频的cpu,性能要高50%以上。
机器架构、内核版本以及cpu频率等三个因素叠加,性能差距在一倍以上是正常的。
可以考虑将ob版本升级到最新的4.3.5版本试试,性能预期会有提升。
此外应该还有一些调优的手段,但幅度不会太大,追求极致的话可以再探索一下。
我想问为什么使用120核也是这个水平呢?我第一次直连leader的时候分配了tpch租户120核心,就算频率低了一些,但是多核心不能有任何提升吗?
别传日志了,拿obdiag巡检的报告回来吧,下面两份文件
./check_report//obdiag_check_report_obproxy_2025-02-18-14-53-09.table
./check_report//obdiag_check_report_observer_2025-02-18-14-53-10.table
sql的并发度是多大呢?是加了hint进行指定?还是调整了全局配置项设置的?
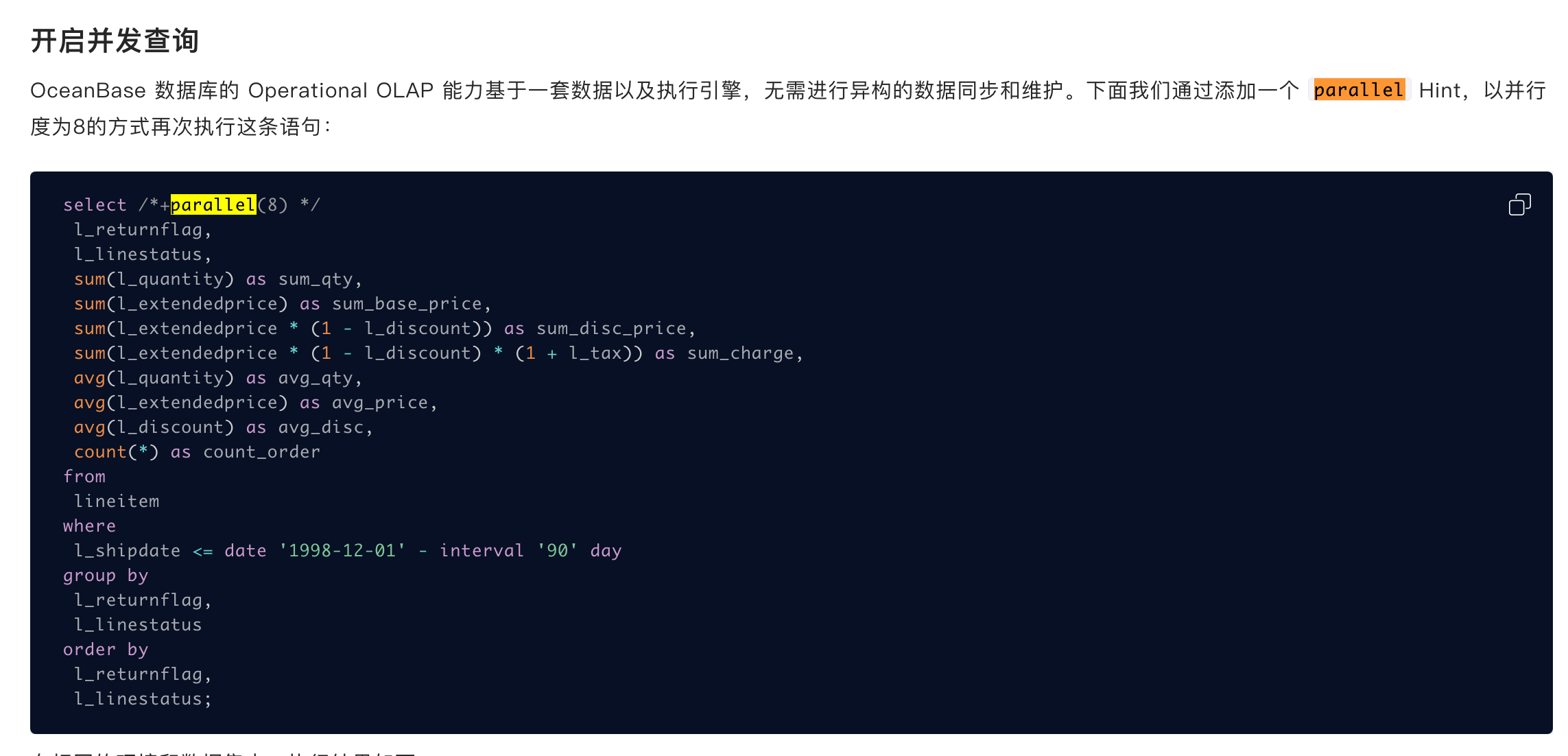
可以通过查询 gv$ob_sql_audit 视图看看sql。
另外测试过程中top看一下cpu是否跑满了,有的时候分配了很多cpu但没有用上,性能也跑不上去。
链接1有提到
select sum(max_cpu) from DBA_OB_UNITS ;
按照这个值跑的