

问题:数据库运行一年发现truncate table 变慢
OceanBase版本:5.7.25-OceanBase_CE-v4.2.1.7
问题:__all_table_history表的truncate记录没有自动清理,现在都600万了,单表15万, ;
参数 schema_history_expire_time =7d, schema_history_recycle_interval=10m。现在导致truncate偶发性卡住导致10分钟超时。请问这个怎么解决(清理)?
1 个赞
七天之外的数据 没有清理么?__all_table_history 这个表的数据 按照时间降序排序 limit20 查出来看看
1 个赞
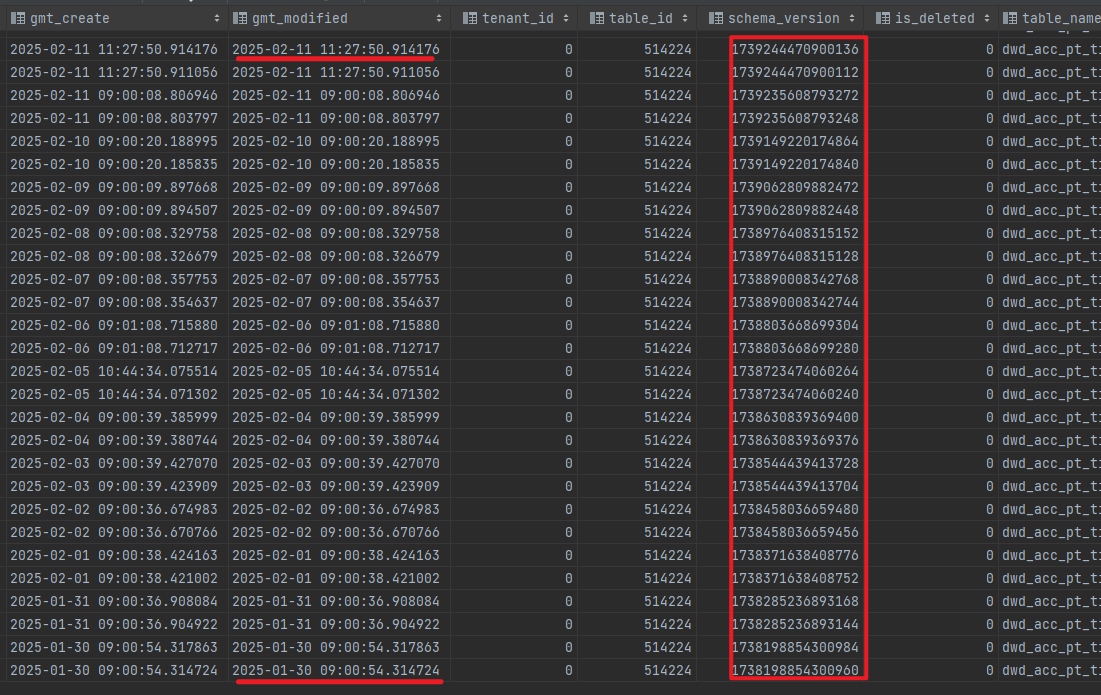
是的,通过 select COUNT(1),MIN(gmt_create) from oceanbase.__all_table_history WHERE TABLE_NAME=‘xxx’ 查询,单表有十几万,最小日期为oceanbase重新部署时的日期2024-08
这个表的数据 你查一下 查出来 截个图看看
2 个赞
用诊断工具obdiag拿回来巡检报告先看下
obdiag check run
https://www.oceanbase.com/docs/common-obdiag-cn-1000000002200479
1 个赞
感觉这个超时和 history 表的记录有没有清理没有直接关系,可能要通过日志看下是什么原因导致的哪个超时时间超时了?
1 个赞
已经运维巡检了,暂时未发现找到对应异常日志
超时报错应该有日志吧?
1 个赞
是个已知问题 421bp10之后应该就不会变慢了 暂时规避的方法是不要频繁使用truncate删除数据 目前解决办法 要么重建表,drop table之后create table,table history就可以正常清理,要么_parallel_ddl_control里把并行truncate关掉。
2 个赞
会话设置的10分钟超时,应用层会出现The last packet successfully received from the server was 599,756 milliseconds ago. The last packet sent successfully to the server was 599,755 milliseconds ago. 查看会话偶尔会发现多个truncate执行时间超长约7m。
目前也建议升级 可以升级到ob425 是长期支持的版本
2 个赞
谢谢,测试了drop table之后create table,table history还没有清理;
升级到5.7.25-OceanBase_CE-v4.2.1.10,这个表数据还没有清理,执行效率有提升。
后续准备升级到ob425,再验证一下。
应该还没有来的及清理呢 明天在观察看看 是否会清理
1 个赞
好的,我这边明天再观察一下
看了一下升级到5.7.25-OceanBase_CE-v4.2.1.10,今天这个表数据还没有清理。
我们这边还部署了一个4.3版本的,这个表好像一直也没有清理。
看了一下源码查了一下 rootservice.log |grep ob_schema_history_recycler,发现没有相关日志。
请问这个表正常会清理吗?或者哪里可以看到这个任务的状态,或者运行日志?
删除表以后 会按照时间重新计算 你设置的schema_history_expire_time是七天 目前这个版本至少是两天 你可以设置两天 后面在观察看看 升级后解的是schema刷新不受存量table history的影响 就是会提升性能
这个语句可以查看schema回收的调度 后面可以通过这个查看
select * from __all_rootservice_event_history where event like “%recycle%” and value1 = {租户id} order by gmt_create desc limit 1;
1 个赞
查了一下select * from __all_rootservice_event_history where event like “%recycle%”,没有数据。

找到一个事件表oceanbase.GV$SYSTEM_EVENT,显示:latch: obcdc progress recycle lock wait

后面观察一下吧 没有清理 没有数据正常 后面等到时间了观察看看 如果再有问题 可以重开帖子 在交流
2 个赞