【 使用环境 】
测试环境
【 OB or 其他组件 】
OB
【 使用版本 】
observer version: OceanBase_CE 4.2.1.2, revision: 102000042023120514-ccdde7d34de421336c5362483d64bf2b73348bd4,
sysname: Linux, os release: 3.10.0-1160.el7.x86_64, machine: x86_64
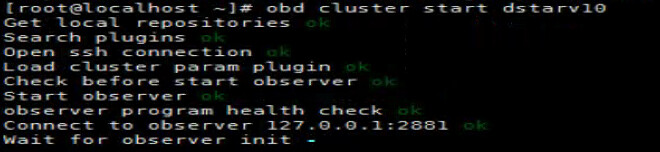
【问题描述】节前(20250127)使用正常,节后(20250206)重启直接启动不了了
【复现路径】
使用obd cluster strat dstarv10 ,启动 dstarv10 实例
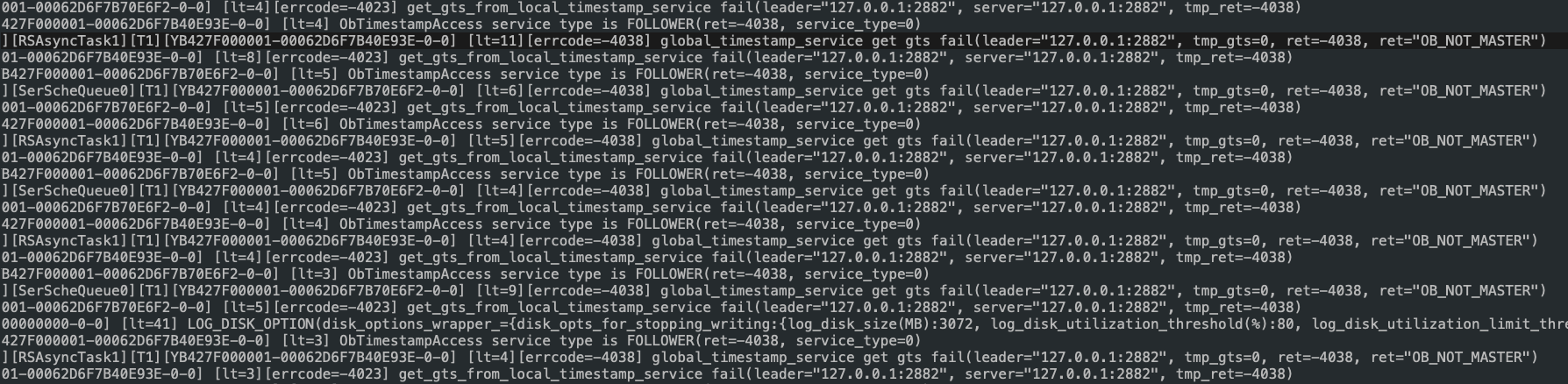
日志中有大量报错
【附件及日志】
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
observer.log.zip (25.5 MB)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
1 个赞
论坛小助手
#3
日志采集场景: observer无故重启
日志采集命令: obdiag gather scene run --scene=observer.restart
推荐使用 obdiag 工具进行日志采集,并且将采集到的日志提供给我们以便确认问题所在。此命令将会收集与 OceanBase 重启相关的信息,包括但不限于日志文件、配置文件等,有助于我们分析为什么在重启时会卡在 ‘Wait for observer init’ 并出现错误码 -4038 和 -40237。
另外,为了确定具体的问题,在此需要您提供一些信息:
- 您能否提供更详细的日志片段?特别是包含这些错误码上下文的日志内容。
- 在出现问题之前,是否对系统进行了任何更改(如升级、配置变更等)?
- 您的 OceanBase 集群当前的版本是什么?
- 这些错误首次出现的具体时间是什么时候?是偶尔发生还是每次重启都会遇到这个问题?
通过上述信息,我们可以进一步缩小问题范围并找到可能的原因。请执行上述命令后将生成的日志压缩包发送给我们,这将帮助我们更快地定位和解决问题。
附上敏捷诊断工具 obdiag 使用帮助链接
2 个赞
有4023错误
有4038错误
还有log_disk_size空间问题导致的写入错误
你的log_disk_size和datafile_size是怎么配置的?大概率是磁盘空间问题引起的,可以删除点日志
1 个赞
淇铭
#5
1、obd cluster edit-config dstarv10 --查一下配置文件 保存在文本里 提供一下
2、obd.log 日志发一下
1 个赞
dblog20250206.txt (3.3 KB)
环境已经重新装了,这是配置, obd.log 没有了
1 个赞
论坛小助手
#8
根据您提供的配置文件和问题描述,您的 OceanBase 集群在重启时卡在了 Wait for observer init,并且日志中出现了错误码 -4038 和 -40237。这些错误通常与全局时间戳服务(Global Timestamp Service, GTS)有关,具体来说是由于无法从 GTS 获取时间戳导致的。
分析与建议
-
GTS 服务问题:
- 错误码
-4038 (OB_NOT_MASTER) 表明当前节点尝试获取 GTS 时,发现 GTS 的领导者不在本地或不可用。
- 错误码
-40237 (OB_GET_GTS_TIMEOUT) 表明获取 GTS 超时。
-
检查 GTS 配置和服务状态:
- 确认 GTS 服务是否正常运行。您可以检查 GTS 服务的日志,确保其没有异常。
- 如果 GTS 服务是在同一台机器上运行,请确认其配置正确,并且网络连接正常。
-
网络配置检查:
- 您的配置文件中指定了
devname: lo,这意味着使用的是回环接口(loopback interface)。这通常是用于单机测试环境的配置。请确保您的集群确实是在单机环境中运行,如果是多机环境,请更改为实际的网络接口名称(如 eth0)。
- 确保防火墙或其他网络设备不会阻止必要的端口通信(如
mysql_port: 2881 和 rpc_port: 2882)。
-
资源限制检查:
- 检查系统资源是否足够,特别是内存和 CPU。您的配置中设置了
memory_limit: 13G 和 cpu_count: 6,请确保这些资源在系统中可用。
-
日志分析:
- 尽管
obd.log 文件已经丢失,但您可以重新启动集群并收集新的日志。使用 obdiag gather scene run --scene=observer.restart 命令来收集详细的日志信息,以便进一步分析。
-
重装后的问题:
- 既然您提到环境已经重新安装,确保所有配置文件和数据目录路径正确无误。特别是
home_path 和 data_dir 等关键路径。
具体操作步骤
-
检查 GTS 服务状态:
obd cluster status dstarv10
-
查看 GTS 日志:
tail -f /home/esunny/dstardb/log/observer.log
-
验证网络配置:
- 确认
devname 设置正确,如果是多机环境,请更改为实际的网络接口名称。
- 使用
ping 和 telnet 命令测试网络连通性和端口开放情况。
-
收集诊断日志:
obdiag gather scene run --scene=observer.restart
-
检查系统资源:
free -m
top
通过以上步骤,您可以进一步排查和解决 Wait for observer init 的问题。如果问题仍然存在,建议联系 OceanBase 的技术支持团队以获取更多帮助。
更多信息请查看:
- oceanbase.DBA_PART_TABLES
- V$OB_PARAMETERS
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
1 个赞
重新安装后,用 1月27 号的 数据还原的,使用正常
1 个赞
淇铭
#12
不过ob4212发版很久了 建议升级到425版本 这个是长期维护的版本