福利斯.干
#1
【 使用环境 】测试环境
【 OB or 其他组件 】OB
【 使用版本 】Server version: 5.6.25 OceanBase_CE 4.3.5.0 (r100000202024123117-5d6cb5cbc3f7c1ab6eb22e40abec8e160a8764d5) (Built Dec 31 2024 17:35:01)
【问题描述】清晰明确描述问题
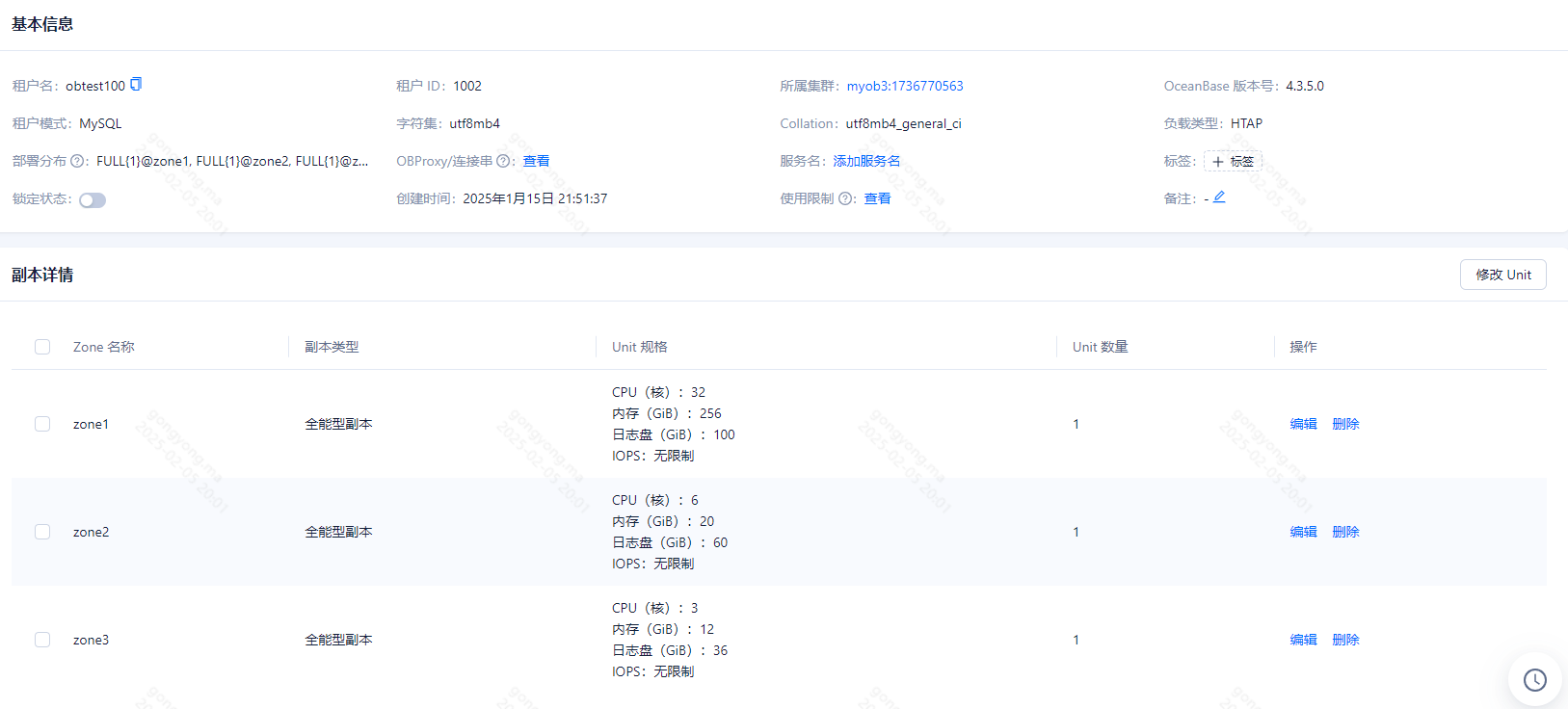
使用ocp部署了一套集群进行测试,observer是3台物理机(1-1-1模式),还有另外一台是obproxy,新建了一个测试租户是obtest100,3个副本的配置是zone1 : 32c , zone2 : 6c , zone3 : 6c ,优先级是zone1;zone2,zone3
使用sysbench测试,发现tps不稳定,100个并发,刚开始跑,tps能到10000,大概过了300秒,tps降到8000多,再过大约100秒,tps降低至6000多,最后到5000左右,cpu的负载一直是比较高的,90%左右
sysbench测试命令如下:
sysbench --db-driver=mysql /usr/share/sysbench/tests/include/oltp_legacy/oltp.lua --mysql-host=192.168.40.201 --mysql-port=2883 --mysql-user=u_sysbench@obtest100#myob3 --mysql-db=sbtest --mysql-password=123456 --oltp-test-mode=complex --oltp-tables-count=8 --oltp-table-size=1000000 --threads=100 --time=6000 --report-interval=2 run
请问这样正常么
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
2 个赞
论坛小助手
#3
推荐使用 obdiag 工具进行日志采集,并且将采集到的日志提供给我们以便确认问题所在。
日志采集场景: CPU高
日志采集命令: obdiag gather scene run --scene=observer.cpu_high
为了更好地帮助您分析和解决问题,建议您按照以下步骤操作:
- 执行上述obdiag命令进行日志采集。该命令会收集与CPU高负载相关的诊断信息,包括系统资源使用情况、SQL执行情况等。
- 将采集到的日志压缩包提供给我们,以便我们进一步分析。
另外,为了确定具体的问题,在此需要您提供一些信息:
- 请提供sysbench测试的具体配置参数,例如线程数、表大小等。
- 在TPS下降期间,是否有其他异常现象发生,如磁盘I/O升高或内存使用率突增?
- 是否对OceanBase集群进行了任何配置更改或软件更新?
- 请确认是否启用了自动合并功能,以及合并的频率和时间安排。
- 请提供OCP平台上的告警信息或者最近的操作记录。
附上敏捷诊断工具 obdiag 使用帮助链接
4 个赞
辞霜
#5
可能是数据频繁发生插入更新变化导致。
可以从GV$OB_SQL_AUDIT 中,根据 SQL 执行耗时(elapsed_time)筛出tps高和低时候的 TOP10的sql。进行对比。查看两者的实际返回行数是否存在差异
3 个赞
靖顺
#6
用敏捷诊断工具obdiag 巡检一下,执行 sysbench 时的巡检任务集合
obdiag check run --cases=sysbench_run
https://www.oceanbase.com/docs/common-obdiag-cn-1000000002200479
3 个赞
旭辉
#7
我复现了这个情况, 结合之前的case分析结论是 冻结、转储、合并一定程度上会导致tps抖动,冻结转储时tps可能会下降20%左右,32c64g的租户,转储时tps可能下降10%
,特别是小规格时影响较明显,主要是后台冻结、转储、合并线程占用了较多cpu,导致业务线程的cpu资源大幅降低,因此tps也大幅下降,机器规格越大,受冻结、转储、合并影响越小
可以降低cpu使用率或者扩大规格再测试看下
2 个赞