以上是文档资料。
version:4.3.0.1
试验如下:
obclient [test]> create table tp1(c1 int,c2 int,c3 int) partition by hash(c1) partitions 4;
Query OK, 0 rows affected (0.117 sec)
obclient [test]> create table tp2(c1 int,c2 int,c3 int) partition by hash(c1) partitions 8;
Query OK, 0 rows affected (0.117 sec)
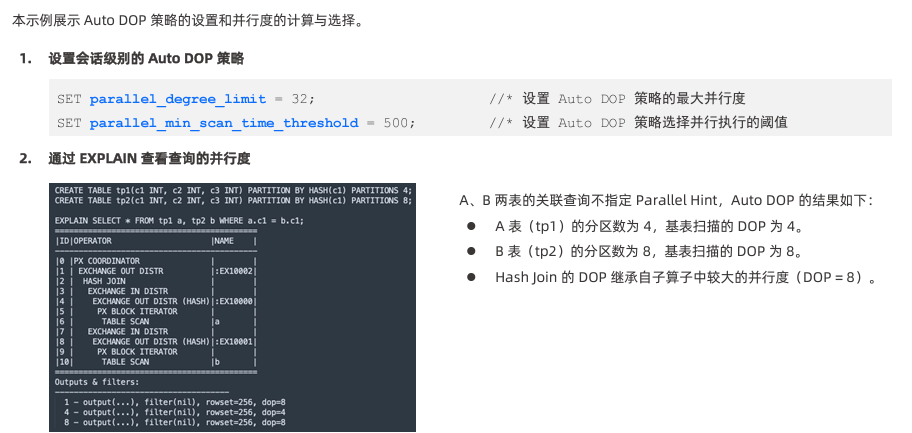
obclient [test]> SET parallel_degree_limit = 32;
Query OK, 0 rows affected (0.001 sec)
obclient [test]> SET parallel_min_scan_time_threshold = 10;
Query OK, 0 rows affected (0.001 sec)
查看执行计划:
obclient [test]> explain select * from tp1 a,tp2 b where a.c1=b.c1;
+-----------------------------------------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------------------------------------+
| ===================================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| --------------------------------------------------------------------- |
| |0 |PX COORDINATOR | |1 |31 | |
| |1 |└─EXCHANGE OUT DISTR |:EX10001|1 |30 | |
| |2 | └─HASH JOIN | |1 |28 | |
| |3 | ├─EXCHANGE IN DISTR | |1 |10 | |
| |4 | │ └─EXCHANGE OUT DISTR (PKEY)|:EX10000|1 |10 | |
| |5 | │ └─PX PARTITION ITERATOR | |1 |9 | |
| |6 | │ └─TABLE FULL SCAN |a |1 |9 | |
| |7 | └─PX PARTITION ITERATOR | |1 |17 | |
| |8 | └─TABLE FULL SCAN |b |1 |17 | |
| ===================================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([INTERNAL_FUNCTION(a.c1, a.c2, a.c3, b.c1, b.c2, b.c3)]), filter(nil), rowset=16 |
| 1 - output([INTERNAL_FUNCTION(a.c1, a.c2, a.c3, b.c1, b.c2, b.c3)]), filter(nil), rowset=16 |
| dop=1 |
| 2 - output([a.c1], [b.c1], [a.c2], [a.c3], [b.c2], [b.c3]), filter(nil), rowset=16 |
| equal_conds([a.c1 = b.c1]), other_conds(nil) |
| 3 - output([a.c1], [a.c2], [a.c3]), filter(nil), rowset=16 |
| 4 - output([a.c1], [a.c2], [a.c3]), filter(nil), rowset=16 |
| (#keys=1, [a.c1]), dop=1 |
| 5 - output([a.c1], [a.c2], [a.c3]), filter(nil), rowset=16 |
| force partition granule |
| 6 - output([a.c1], [a.c2], [a.c3]), filter(nil), rowset=16 |
| access([a.c1], [a.c2], [a.c3]), partitions(p[0-3]) |
| is_index_back=false, is_global_index=false, |
| range_key([a.__pk_increment]), range(MIN ; MAX)always true |
| 7 - output([b.c1], [b.c2], [b.c3]), filter(nil), rowset=16 |
| affinitize, force partition granule |
| 8 - output([b.c1], [b.c2], [b.c3]), filter(nil), rowset=16 |
| access([b.c1], [b.c2], [b.c3]), partitions(p[0-7]) |
| is_index_back=false, is_global_index=false, |
| range_key([b.__pk_increment]), range(MIN ; MAX)always true |
+-----------------------------------------------------------------------------------------------+
35 rows in set (0.052 sec)
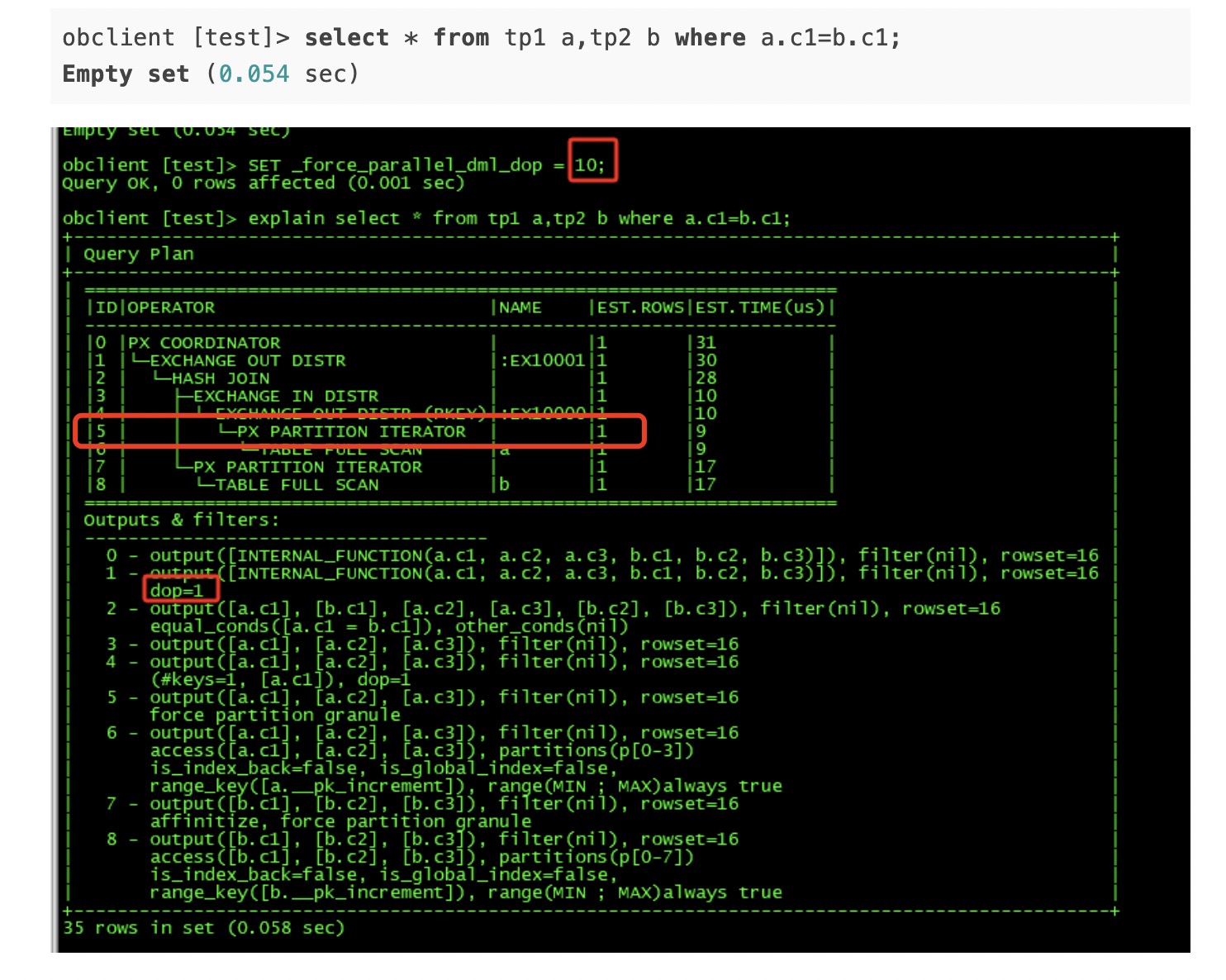
obclient [test]> select * from tp1 a,tp2 b where a.c1=b.c1;
Empty set (0.054 sec)
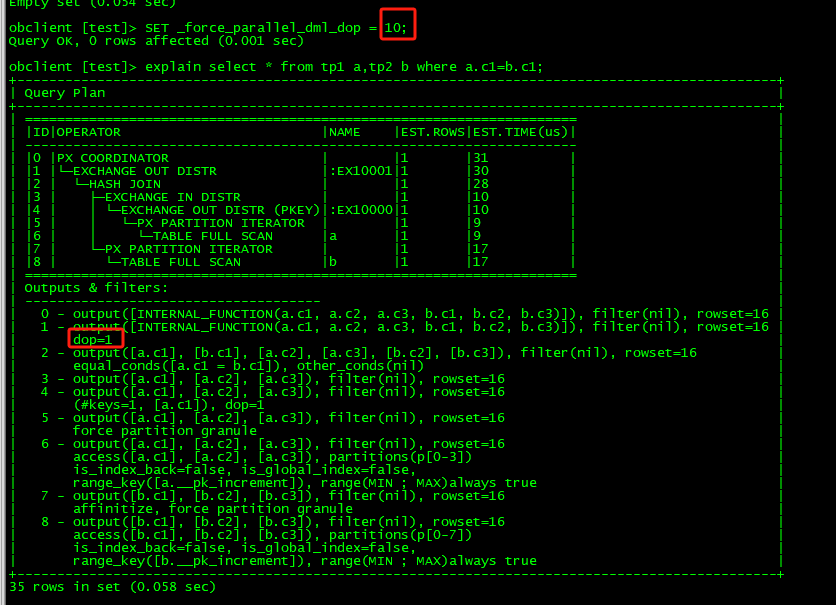
即便开启强制并行,还是没有达到预期!
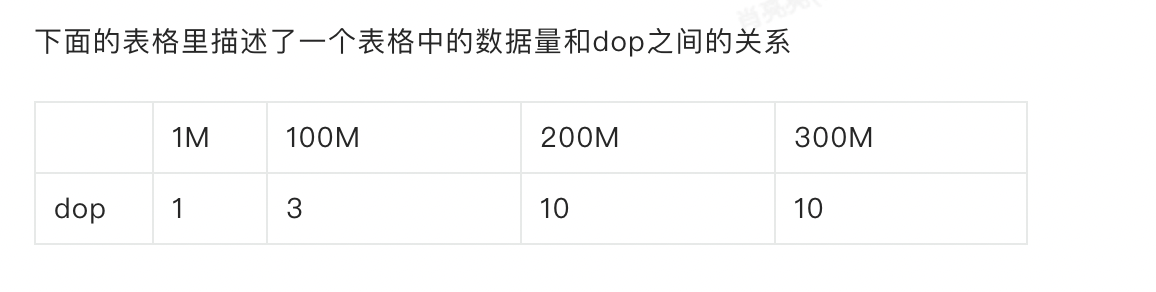
1、查询耗时54ms,远远超过parallel_min_scan_time_threshold = 10,为什么不走并行呢?
2、为什么这里的dop不是像文档中显示的4或者8呢?
另外:
t2表结构定义:
obclient [test]> show create table t2 \G
*************************** 1. row ***************************
Table: t2
Create Table: CREATE TABLE `t2` (
`c1` int(11) NOT NULL,
`c2` int(11) DEFAULT NULL,
`c3` int(11) DEFAULT NULL,
PRIMARY KEY (`c1`),
KEY `i2` (`c2`) BLOCK_SIZE 16384 GLOBAL
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 3 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0
partition by hash(c1)
(partition `p0`,
partition `p1`,
partition `p2`,
partition `p3`)
1 row in set (0.003 sec)
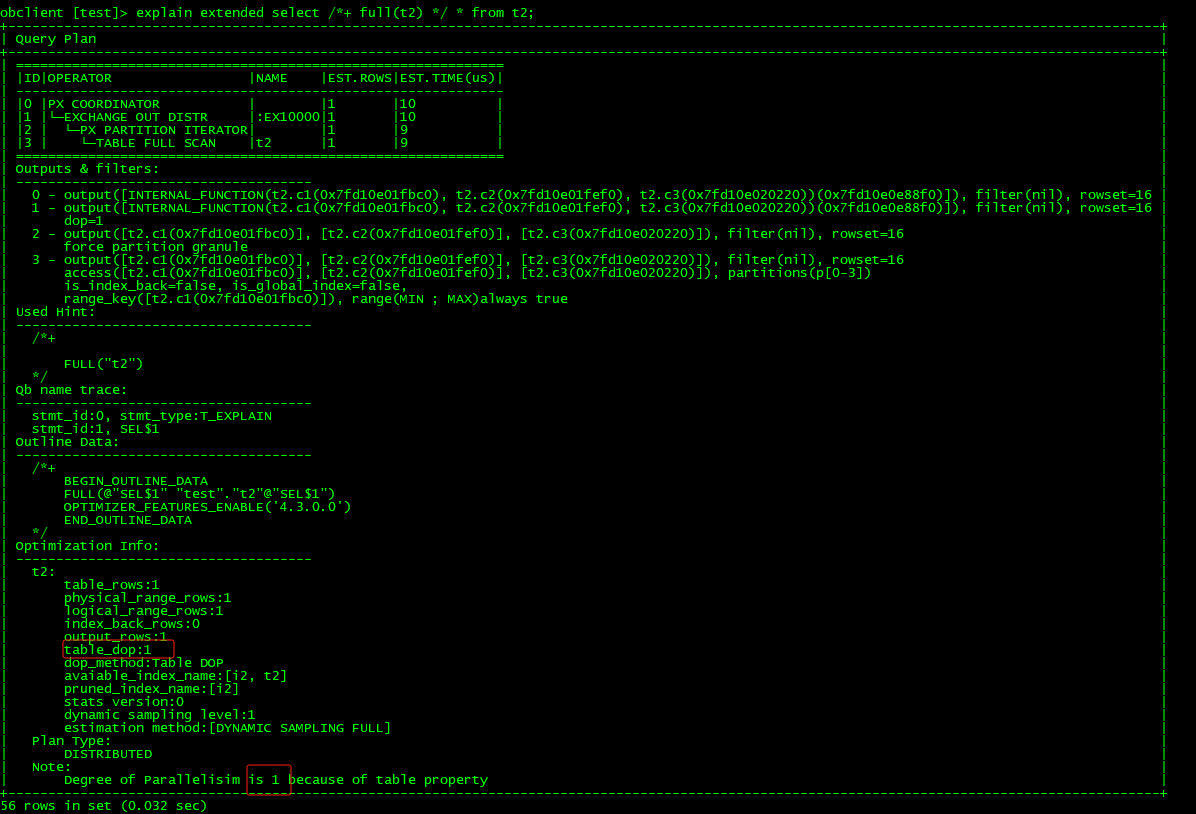
这是dop也是1,但是官方文档这样描述的:

那是不是 select /*+ full(t2) */ * from t2; 这个查询应该是dop=4才符合预期呢?