

【 使用环境 】生产环境
【 OB or 其他组件 】OMS
【 使用版本 】OMS4.2.7, TiDBv5.1.1
【问题描述】OMS 社区版4.2.7版本开始实现 TiDB 数据库 V4.x 之后版本的增量组件,去除对 TiCDC 和 Kakfa 的依赖。
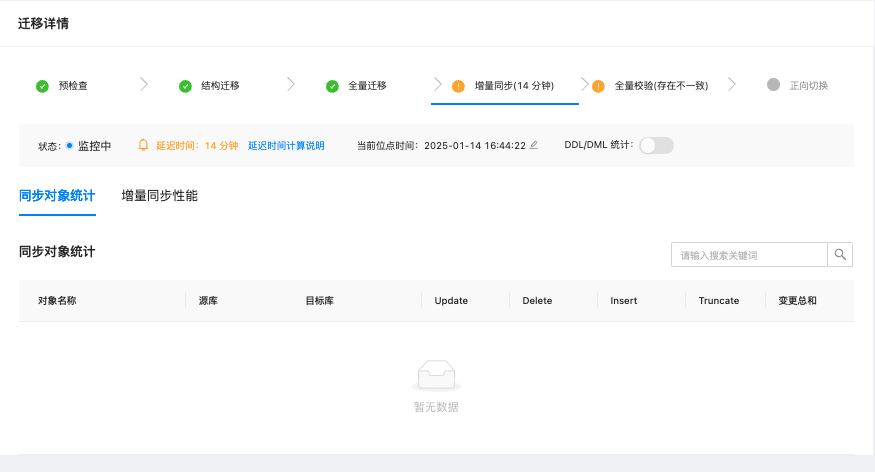
因为之前使用ticdc+kafka,tidb的checkpoint老是停滞,所以改用了OMS4.2.7将TiDB迁移到OB,但是增量同步的延迟越来越大,请问是什么问题呢?
3 个赞
查一下 组件监控 看看是哪个组件有延迟
1 个赞
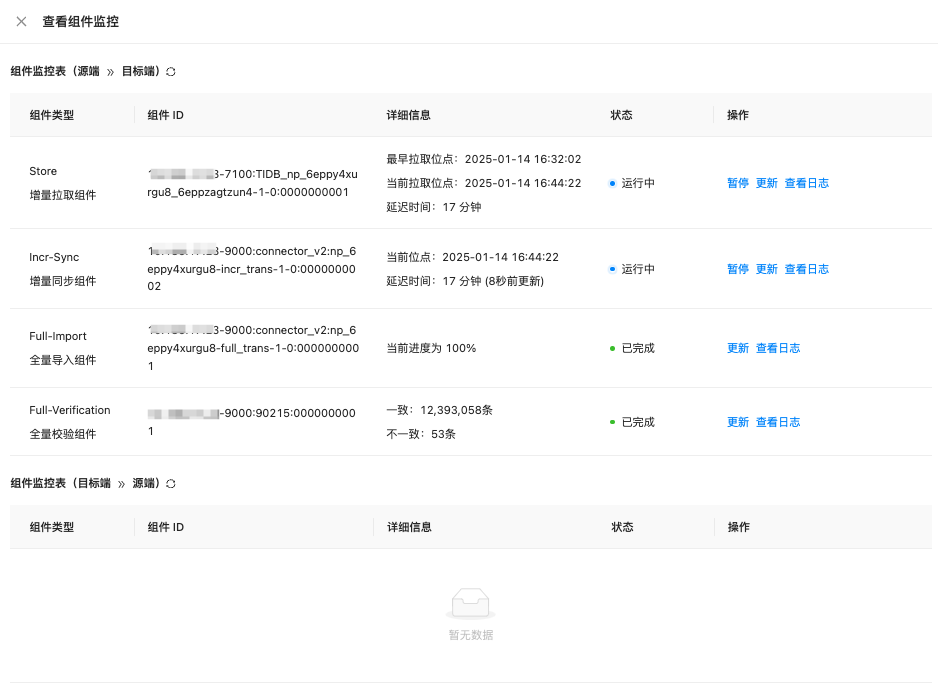
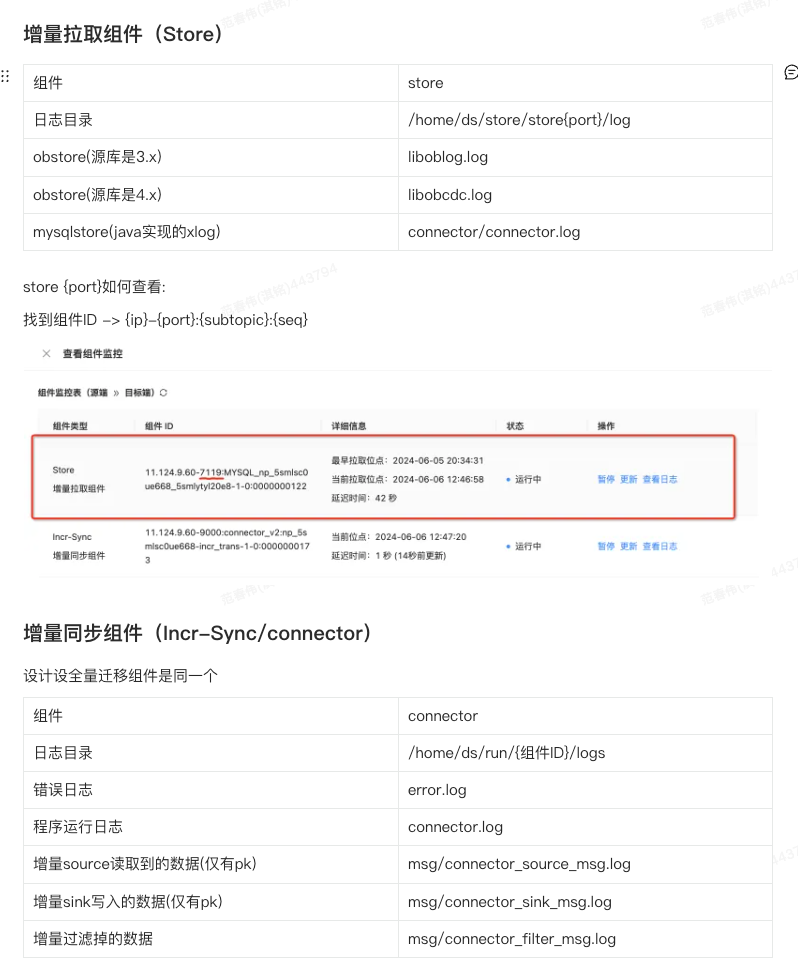
这个是需要登录到oms对应的docker后获取日志,还是直接在OMS平台上获取日志呢?
oms对应的docker后获取日志 这样比较全
1 个赞
系统租户oceanbase库 下执行如下查询SQL
WITH palf_log_stat AS (
SELECT
tenant_id,
MAX(begin_scn) AS palf_available_start_scn,
MIN(end_scn) AS palf_available_latest_scn,
SCN_TO_TIMESTAMP(MAX(begin_scn)) AS palf_available_start_scn_display,
SCN_TO_TIMESTAMP(MIN(end_scn)) AS palf_available_latest_scn_display
FROM GV$OB_LOG_STAT
WHERE tenant_id & 0x01 = 0 or tenant_id = 1
GROUP BY tenant_id
),
archivelog_stat AS (
SELECT
a.tenant_id AS tenant_id,
MIN(b.start_scn) AS archive_start_scn,
a.checkpoint_scn AS archive_latest_scn,
a.checkpoint_scn_display AS archive_available_latest_scn_display
FROM CDB_OB_ARCHIVELOG a
LEFT JOIN CDB_OB_ARCHIVELOG_PIECE_FILES b
ON a.tenant_id = b.tenant_id AND a.round_id = b.round_id
AND b.file_status != ‘DELETED’ AND a.STATUS = ‘DOING’
GROUP BY a.tenant_id
)
SELECT
pls.tenant_id,
pls.palf_available_start_scn,
pls.palf_available_latest_scn,
pls.palf_available_start_scn_display AS palf_available_start_scn_display,
pls.palf_available_latest_scn_display AS palf_available_latest_scn_display,
als.archive_start_scn AS archive_available_start_scn,
als.archive_latest_scn AS archive_available_latest_scn,
CASE WHEN als.archive_start_scn IS NOT NULL THEN SCN_TO_TIMESTAMP(als.archive_start_scn) ELSE NULL END AS archive_available_start_scn_dispalay,
als.archive_available_latest_scn_display
FROM palf_log_stat pls
LEFT JOIN archivelog_stat als ON pls.tenant_id = als.tenant_id
GROUP BY pls.tenant_id, pls.palf_available_start_scn;
2 个赞
connector_source_msg.log (185.0 KB)
connector_sink_msg.log (178 字节)
incr_connector.log (3.8 KB)
store_connector.log (264.7 KB)
error.log和connector_filter_msg.log文件内容是空的
没找到下面这2个文件

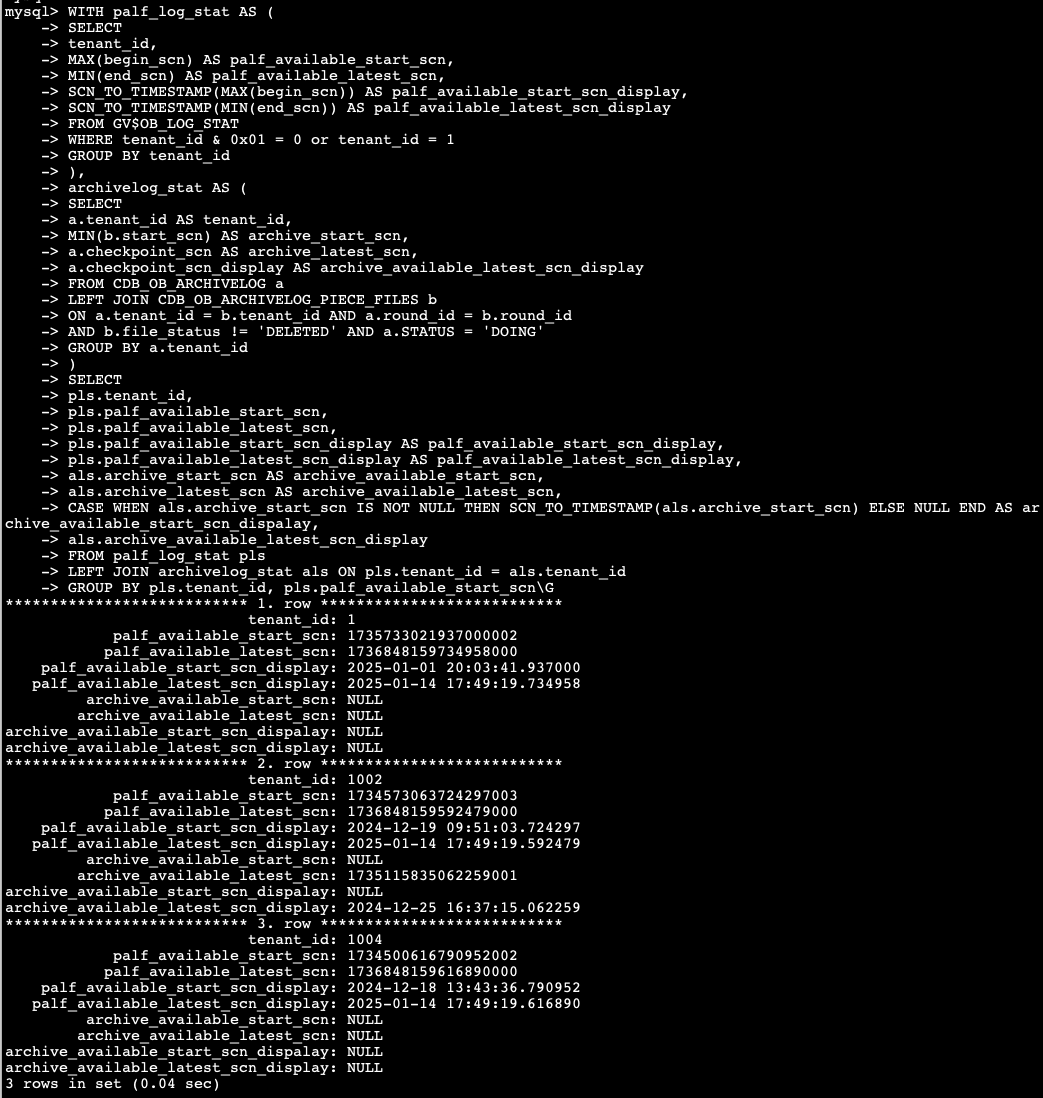

没错
store重启一下看看
1 个赞

这个是tidb端region状态有变动,一般重启下store就好了
1 个赞
好的好的,多谢
现在又有了一个新的问题,隔一段时间 Store增量拉取组件又开始延迟了(今天已经出现2次了),重启store增量同步又恢复了,这种情况有什么优化方式吗?
跟我之前使用ticdc+kafka+oms的现象有点像,不过之前是ticdc的check不往前推进了
你可以按照上面发的 把日志提供出来 看看具体的问题
1 个赞
上面已经发过了,还需要最新的日志吗?
最新的日志需要的 可以定位最新延迟的问题
最新的日志
msg:connector_sink_msg.log (62.1 KB)
msg:connector_source_msg.log (6.5 KB)
incr_error.log (18.2 KB)
incr_connector.log (27.2 KB)
store_connector.log (107.6 KB)