niki
2025 年1 月 10 日 10:04
#1
【 使用环境 】 测试环境
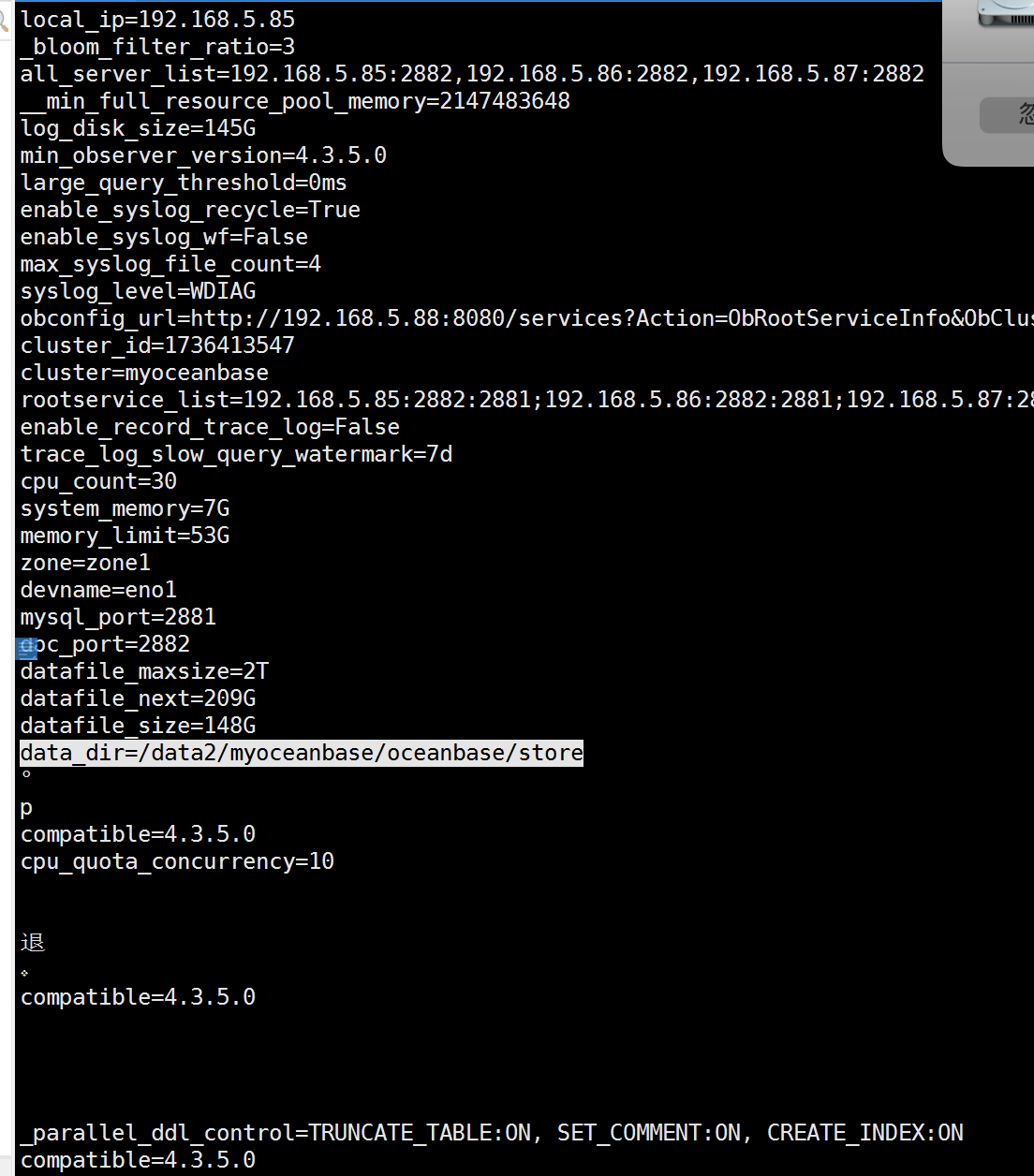
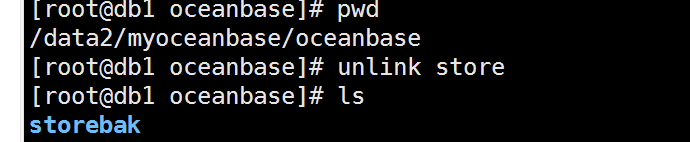
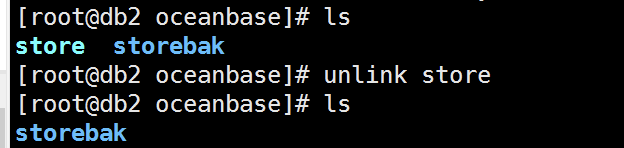
然后mv store storebak#做成软连接方式 方便后面模拟磁盘损坏
所以我现在有点茫然了,Oceanbaes查询数据表业务他的逻辑是怎么走底层的啊,现在相当于数据目录都不存在了,表数据依然可查。
【复现路径】问题出现前后相关操作
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手 ] 即可召唤小助手,欢迎试用!
1 个赞
论坛小助手
2025 年1 月 10 日 10:05
#3
日志采集场景: 集群基础信息
为了更好地理解这一现象并确保没有潜在的风险,建议您使用上述命令收集集群的基础信息。这将帮助我们确认当前集群的配置和状态。
另外,为了确定具体的问题,在此需要您提供一些信息:
您能否提供具体的 OceanBase 版本号?
在模拟磁盘损坏前,是否进行了完整的备份操作?如果有,请说明备份的方式和位置。
您提到两个 zone 的数据目录都不存在的情况下还能正常查询,能否确认这两个 zone 是否真的没有任何数据文件存在,还是只是通过软链接的方式改变了路径?
您是否有查看过系统的日志或告警信息,是否存在任何警告或错误提示?
当前集群的副本分布情况是怎样的,是否存在其他隐藏的副本或者额外的 zone?
请根据以上问题提供更详细的信息,并上传通过 obdiag 收集的日志压缩包,以便我们进一步分析。
附上敏捷诊断工具 obdiag 使用帮助链接
1 个赞
淇铭
2025 年1 月 10 日 10:53
#4
sys租户下 查看一下 select * from __all_server;
1 个赞
niki
2025 年1 月 10 日 14:25
#5
你好!
当前集群环境:
集群是1:1:1 模式
租户是1:1:1 模式
每一个zone下只有一个observer
每一个observer下只有一个数据盘和一个日志盘
现在模拟的就是3台observer 的数据盘全丢失了的情况下,通过obclient 上 oceanbase 依然可以查询数据!继续把clog日志盘弄丢失的情况下还是可以查询,该条件下只有重启observer的情况才会出现异常会出现重启不成功!如果不重启的情况下导入数据会在最后的commit状态下无限刷进度,这应该是最后写入磁盘的时候找不到磁盘路径的原因! 但是查询不受影响,包含模拟数据丢失到丢失后的各种语句查询!
1 个赞
niki
2025 年1 月 10 日 14:34
#7
其实可以理解是破坏式的!
1 个赞
这个应该是操作系统打开文件以后,文件就有一个引用计数。后续你删掉这个文件,或者挪动这个文件的位置。那个文件实际在内核里面还存在的。
1 个赞
这个说法是对的。
OB 是单进程软件,数据文件就一个,跟 mysql和pg大不一样。所以,你在 OS 里删除数据文件,observer 进程依然持有文件句柄,文件并没有被真正删除。
OB V4 的日志文件使用特点相比 V3 也发生变化,clog disk 采取预分配使用的方式,每个租户对用的clog disk 文件都是预分配好的。所以估计删除 clog 目录 OB 也不会马上报错,除非此时还调整租户的资源规格中的 log disk 大小(调整的原理就是一些预分配文件从 租户目录移动到 默认目录,或者反向)。
OB 这个设计好也挺好的,就是误删文件数据库不会马上出故障。如果你知道自己误操作了,还是有挽回的余地(切换,重建误操作的节点)。不好之处就是真有人误删除了,没人立即知道。
2 个赞
论坛小助手
2025 年1 月 14 日 20:08
#12
根据您提供的信息,您的集群配置为每个 Zone 仅有一个 Observer,并且每个 Observer 下只有一个数据盘和一个日志盘。在模拟磁盘损坏的过程中,您通过移动实际的数据目录并创建软链接来模拟磁盘丢失的情况。接下来我将解释为什么即使在所有 Observer 的数据盘都“丢失”的情况下,OceanBase 仍然能够正常查询数据。
OceanBase 是一个分布式数据库系统,具有强大的高可用性和容错能力。它通过多副本机制确保数据的可靠性和可用性。具体来说:
多副本机制 :
在您的环境中,集群和租户都是 1:1:1 模式,意味着每个分区都有三个副本,分别位于不同的 Zone 中。
当一个 Zone 的数据盘不可用时,OceanBase 会自动切换到其他 Zone 的副本进行读取操作。因此,只要还有一个可用的副本,查询操作就不会受到影响。
Leader 和 Follower 角色 :
在 OceanBase 中,每个分区有一个 Leader 和多个 Follower。Leader 负责处理写入请求,而 Follower 只负责同步数据。
如果某个 Zone 的 Leader 数据盘不可用,OceanBase 会自动将该分区的 Leader 切换到其他 Zone 的 Follower 上,以确保服务的连续性。
CLog(提交日志)的作用 :
CLog 记录了所有的事务提交信息。即使数据盘不可用,只要 CLog 存在并且可以访问,OceanBase 就可以从 CLog 中恢复未完成的事务。
在您的测试中,即使取消了 CLog 的软链接,查询操作仍然不受影响,因为 CLog 主要用于保证事务的持久性和一致性,而不是直接参与查询操作。
内存中的缓存和索引 :
OceanBase 在内存中维护了大量的缓存和索引结构,这些结构可以帮助加速查询操作。即使数据盘不可用,内存中的缓存和索引仍然可以提供快速的查询响应。
查询操作正常 :由于 OceanBase 的多副本机制和 Leader 切换功能,即使主 Zone 的数据盘不可用,查询操作仍然可以通过其他 Zone 的副本进行。
导入数据时的问题 :当您尝试导入数据并在最后的 COMMIT 阶段出现问题时,这是因为写入操作需要将数据持久化到磁盘上。如果磁盘路径不存在,写入操作将无法完成,导致进度卡住。
重启 Observer 后异常 :重启 Observer 时,系统会尝试重新加载数据和日志文件。如果这些文件不存在或路径不正确,Observer 将无法成功启动。
为了更好地理解和验证这一现象,建议您:
检查副本分布 :使用以下 SQL 查询确认当前各分区的副本分布情况:
SELECT * FROM oceanbase.__all_tablet WHERE tenant_id = (SELECT tenant_id FROM oceanbase.__all_tenant WHERE tenant_name = 'your_tenant_name');
查看 Leader 分布 :确认各个分区的 Leader 分布情况:
SELECT * FROM oceanbase.DBA_OB_TABLE_LOCATIONS WHERE ROLE='LEADER';
监控日志 :查看 Observer 的日志文件,特别是与 Leader 切换和副本同步相关的日志信息,以确保没有潜在的错误或警告。
恢复测试 :尝试恢复部分或全部数据盘,观察系统的恢复过程和性能表现。
通过以上步骤,您可以更全面地了解 OceanBase 在高可用场景下的行为,并确保在实际生产环境中具备足够的冗余和容错能力。
如果您有更多问题或需要进一步的帮助,请随时联系 OceanBase 的技术支持团队。
更多信息请查看:
合并 使用命令行进行运维 联接算法
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
1 个赞