【 使用环境 】生产环境
【 OB or 其他组件 】
【 使用版本 】
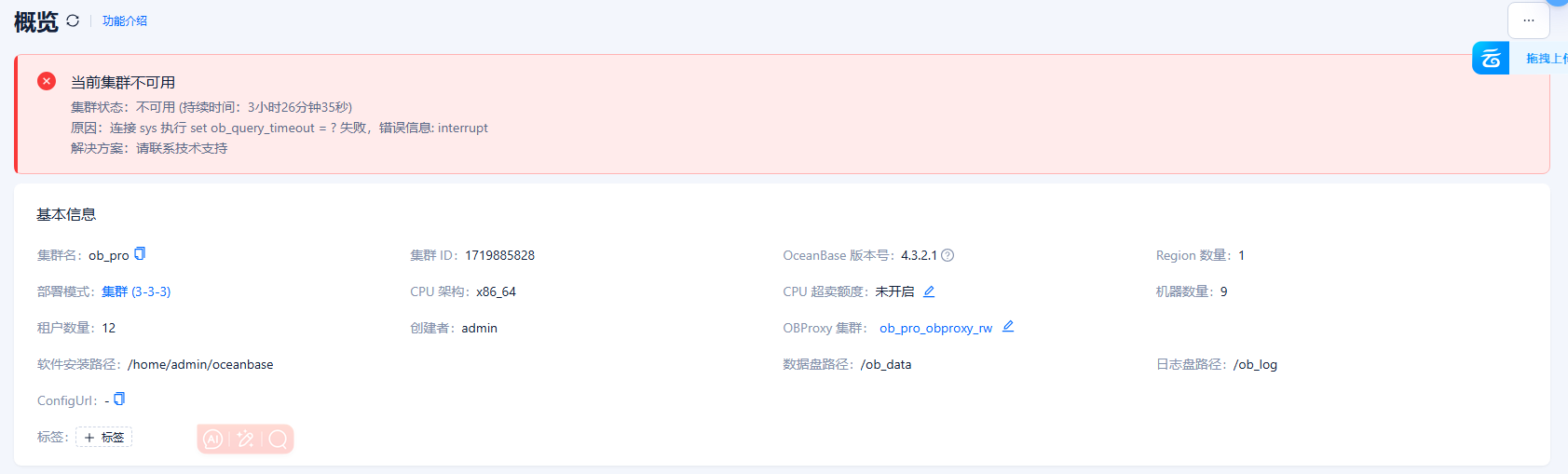
【问题描述】集群由2-2-2的部署扩容到3-3-3后大概30分钟后,ocp现在集群无法连接,提示如题:
查看系统也未发现可疑日志,所有服务器均在线,各租户也访问正常,能使用sys租户登陆集群。请问这种情况如何处理。
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
论坛小助手
#3
日志采集场景: 集群无法连接
日志采集命令: obdiag gather scene run --scene=observer.cluster_down
推荐使用 obdiag 工具进行日志采集,并且将采集到的日志提供给我们以便确认问题所在。上述命令将会收集与集群连接性相关的信息,有助于我们分析为什么 OCP 在 OceanBase 集群扩容后无法连接集群。
另外,为了确定具体的问题,在此需要您提供一些信息:
- 扩容操作的具体步骤和时间点是什么?这可以帮助我们了解是否有特定的操作触发了当前的问题。
- 在尝试连接 sys 并执行 set ob_query_timeout 时,具体的错误堆栈或日志信息能否提供更详细的描述?这可以让我们更准确地定位问题。
- 扩容前集群是否稳定运行,是否存在任何警告或错误信息?
- 您能否检查并提供 OCP 和 OceanBase 集群之间的网络连通性情况?例如,是否存在网络延迟或丢包现象。
- 执行
set ob_query_timeout 命令的完整语句是什么?以及该命令执行前后是否有其他相关操作?
请您根据以上建议进行日志采集,并提供更多信息,我们将根据这些信息进一步帮助您解决问题。
附上敏捷诊断工具 obdiag 使用帮助链接
1 个赞
论坛小助手
#5
根据您提供的日志信息,存在以下两个主要问题:
-
租户内存达到上限:
日志中频繁出现 tenant memory has reached the upper limit 的警告信息,表明租户 1038 的内存使用量已经达到了其分配的上限。这可能导致某些操作失败或性能下降。
-
RPC 包延迟较大:
日志中还提到 The RPC packet delay is large,建议检查时钟偏差(clock skew)和 TCP 重传率(TCP retransmission rate),这可能是由于时钟不同步或网络延迟引起的。进一步来说,也可能是机器硬件或软件故障导致的问题。
解决方案
1. 租户内存达到上限
-
增加租户内存限制:如果当前租户的内存限制不足以支持业务需求,可以考虑适当增加租户的内存限制。可以通过以下 SQL 语句调整租户的内存配置:
ALTER TENANT tenant_name SET MEMORY_SIZE = new_memory_size;
其中 tenant_name 是租户名称,new_memory_size 是新的内存大小。请根据实际情况调整。
-
优化查询和应用逻辑:检查是否有大查询或不必要的数据操作占用了大量内存。优化这些查询或减少不必要的数据处理可以释放内存资源。
-
监控和分析:使用 OCP 或其他监控工具持续监控租户的内存使用情况,确保不会再次触及上限。可以设置告警规则,在接近上限时及时通知管理员。
2. RPC 包延迟较大
-
检查网络状况:确保所有节点之间的网络连接稳定,没有明显的延迟或丢包现象。可以通过 ping 或 traceroute 等命令测试网络连通性。
-
同步服务器时间:确保所有节点的时间同步,避免时钟偏差影响系统正常运行。可以使用 NTP(Network Time Protocol)服务来保持时间同步。
-
排查硬件和软件故障:检查各节点的硬件状态,如 CPU、内存、磁盘等是否正常工作;同时检查操作系统和数据库软件是否存在异常。
进一步建议
-
收集诊断信息:继续使用 obdiag 工具收集更多诊断信息,特别是关于网络和内存使用的详细日志,以便更深入地分析问题原因。
-
联系技术支持:如果上述措施无法解决问题,建议联系 OceanBase 技术支持团队获取专业帮助。
希望以上建议能帮助您解决 OCP 无法连接 OB 集群的问题。如果有任何疑问或需要进一步的帮助,请随时告知。
更多信息请查看:
- 使用命令行进行运维
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
1 个赞
这个租户是业务租户,应该不会影响到ocp采集集群信息吧?
旭辉
#7
1.麻烦发下ocp的版本
2.ocp-server.log
3.ocp数据库的observer.log
1 个赞
ocp的版本是版本号: 4.3.1-20240805192406
ocp-server日志:
ncms-ocp-2.zip (16.0 MB)
ocp数据库的observer.log有点多 我稍等上传
这是一半ocp数据库observer的日志太大。我只下载10分钟的日志行不行?
不会写SQL
#10
observer.log (19.2 MB)
这个是一个observer节点的日志
辞霜
#11
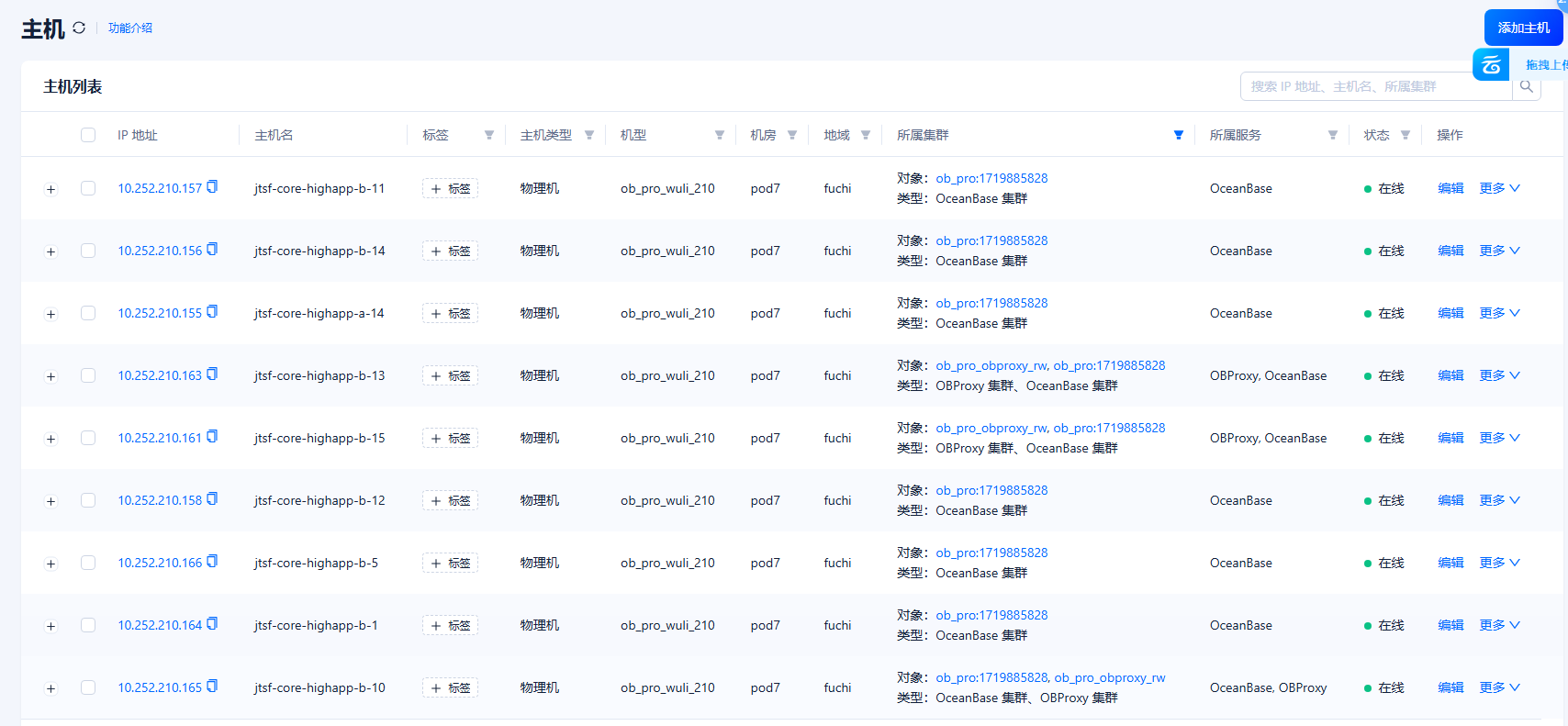
截一个ocp界面主机列表图,看一下该集群的所包含的主机状态
1 个赞
不会写SQL
#13
ocp上一直提示是网络的问题,我使用obclient在ocp-server的服务器上通过2883端口登陆正常,且也能执行命令。
不会写SQL
#16
没有,就要是ocp显示集群不可用,进入集群界面就是报错:
不会写SQL
#17
ocp上面的告警都是一些sql执行计划恶化的租户告警。
辞霜
#19
也有可能是勿告警,你把最近的ocp日志再发一份看看
不会写SQL
#20
这个是在ocp无法连接集群期间的ocp-server的日志:
ocp-server.log.2025-01-07.3.gz (7.7 MB)
有个猜想,是在中午13点40左右扩容后,集群在做资源平衡时迁移租户副本时导致集群负载升高,当下午上班后业务流量升高以后导致系统负载较高,查询超时导致的。我在日志中也没有找到什么信息。
因为集群是使用ocp安装的,也没有其他的运维工具,当ocp连接不上集群的时候,有点抓瞎了。
旭辉
#21
那应该是这个时间段业务集群的负载非常高,ocp连接业务集群执行 set ob_query_timeout=xxx 就失败了,麻烦发下业务集群当时的 monagent.log,ocp_monagent.error.log