ob:4.3.0
修改大表的默认值,报错:ERROR 4184 (53100): Server out of disk space
select /*+ query_timeout(30000000) */ a.TENANT_ID, a.DATABASE_NAME, a.TABLE_NAME, a.TABLE_ID,
sum(
case
when b.nested_offset = 0 then IFNULL(b.data_block_count+b.index_block_count+b.linked_block_count, 0) * 2 * 1024 * 1024
else IFNULL(b.size, 0)
end
) /1024/1024/1024 as data_size_in_GB
from CDB_OB_TABLE_LOCATIONS a left join __all_virtual_table_mgr b
on a.svr_ip = b.svr_ip and a.svr_port=b.svr_port and a.tenant_id = b.tenant_id and a.LS_ID = b.LS_ID and a.TABLET_ID = b.TABLET_ID
where a.role = 'LEADER' and a.tenant_id = 'xxxx' and a.DATABASE_NAME= 'xxxx' and a.TABLE_NAME = 'xxxx'
and b.table_type >= 10 and b.size > 0 group by a.TABLE_ID;
+----------+-----------------+
| TABLE_ID | data_size_in_GB |
+----------+-----------------+
| 501370 | 28.355468750000 |
+----------+-----------------+
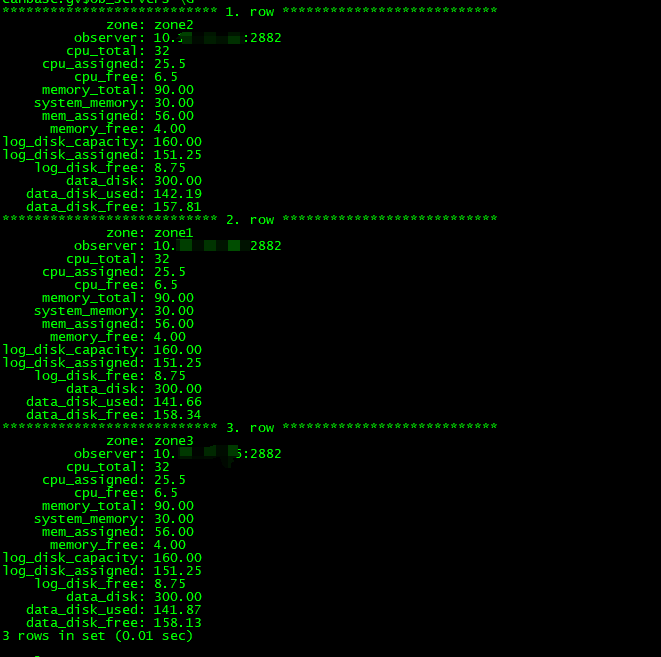
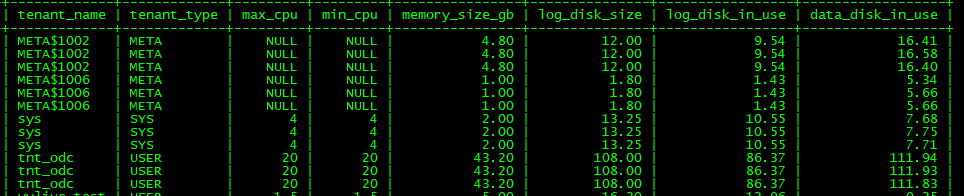
只有28G左右,但是空间显示还有很多。
*************************** 1. row ***************************
SVR_IP: 10.xx.xx.xx
SVR_PORT: 2882
ZONE: zone3
SQL_PORT: 2881
CPU_CAPACITY: 32
CPU_CAPACITY_MAX: 32
CPU_ASSIGNED: 25.5
CPU_ASSIGNED_MAX: 25.5
MEM_CAPACITY: 64424509440
MEM_ASSIGNED: 60129542144
LOG_DISK_CAPACITY: 206158430208
LOG_DISK_ASSIGNED: 162403450880
LOG_DISK_IN_USE: 129989869568
DATA_DISK_CAPACITY: 322122547200
DATA_DISK_IN_USE: 133297078272
DATA_DISK_HEALTH_STATUS: NORMAL
MEMORY_LIMIT: 96636764160
DATA_DISK_ALLOCATED: 322122547200
DATA_DISK_ABNORMAL_TIME: NULL
SSL_CERT_EXPIRED_TIME: NULL
空间显示还有很多,但是报错。