

一、实验背景介绍
Chat Data
Chat Data技术允许用户通过自然语言对话与数据系统进行互动。用户可以提出问题或请求,系统根据用户的意图和历史交互记录,自动生成对数据系统的查询、管理操作,并进一步提供数据可视化、分析能力。针对关系型数据库场景来说,
Text2SQL是Chat Data的技术核心,其目的是将自然语言查询转换为 SQL。用户可以用简单的自然语言描述他们想要提取的数据,比如“显示2023年销售额最高的产品”,系统能够自动解析并生成相应的 SQL 语句,比如SELECT product_name FROM sales WHERE year = 2023 ORDER BY sales_amount DESC LIMIT 1;。这种技术在数据库查询、商业智能和数据分析工具中尤为重要,使得非技术用户也能轻松进行复杂的数据查询。
GraphRAG
传统
RAG通常使用向量检索作为文档召回器,在检索精确度方面具有一定的优势,然而在处理诸如 “这篇文章的主题是什么?”、“总结一下文档” 等概括性、综合性问题时存在困难,这些问题通常涉及多个文档知识的整合,要求文档搜索的广度而非精确度。为了解决这个问题,
GraphRAG被提出。该技术创新地提出使用图结构存储外部知识,外部知识通常是"主-谓-宾"结构的,而图结构的节点可以描述主语和宾语,图中的边可以描述谓语,GraphRAG符合知识建模,从而有效提升文档召回和回答质量;此外,社区划分和总结使得在检索时考虑高层级的综合性知识,在保证搜索精度的同时,提升搜索的广度。
![]() DB-GPT是一个开源的AI原生数据应用开发框架(AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents)。
DB-GPT是一个开源的AI原生数据应用开发框架(AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents)。
目的是构建大模型领域的基础设施,通过开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单,更方便。
OceanBase 从 4.3.3 版本开始支持了向量数据类型的存储和检索,并且经过适配可以作为 DB-GPT 的可选向量数据库,支持 DB-GPT 对结构化数据和向量数据的存取需求,有力地支撑其上 LLM 应用的开发和落地,同时 DB-GPT 也通过 chat data、chat db 等应用为 OceanBase 提升易用性。
鉴于传统 RAG 在概括性问题上存在的问题,DB-GPT 实现了一种基于知识图谱进行相关文档召回的 RAG 技术 —— GraphRAG。实现依赖图数据库和向量数据库作为文档数据存储和检索的基础组件。TuGraph是作为一个高效的图形数据库,支持高数据量、低延迟查找和快速图形分析的图数据库,可以与 OceanBase 的向量存储功能相结合,共同支持 DB-GPT GraphRAG 功能。
二、涉及技术讲解
Chat Data / NL2SQL / Text2SQL
DB-GPT 的 chat data 功能本质是自然语言转SQL技术(或称为NL2SQL/Text2SQL),原理如下图所示:
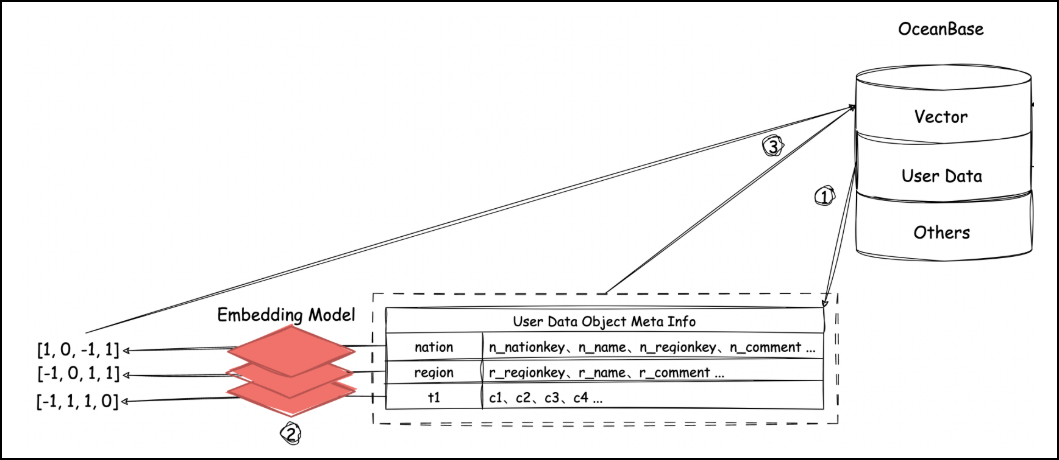
数据导入阶段
获取数据库内用户表schema,将表名、列名、约束等嵌入为向量,存储到OceanBase向量数据库
自然语言查询阶段
- 提问嵌入+向量搜索
- 获取相关表schema后生成SQL以及可视化方案
- 使用获取的数据最终输出

数据导入阶段
- 文档分块;
- 依据文档层级结构,为分块建立父子关系;
- 使用 LLM 抽取文档块中的实体以及关系三元组:在此过程中使用向量数据库搜索出与当前处理文档块语义接近的块,增强抽取时大模型对上下文的语义理解;
- 使用社区算法获取出实体关系图中的子图划分,利用大模型为每个子图生成一段总结,向量化后存入数据库;

查询阶段
- 通过社区总结的向量数据库获取出与查询问题相关的topK个社区;
- 将这些查询结果拼接为一个总的summary,让 LLM 抽取查询所需要的关键词;
- 获取包含关键词的实体、以及其一跳的邻居实体;
- 获取文档块,并在 LLM 的提示词中添加实体、关系的描述;
三、实验环境介绍
Git、Docker、MySQL 客户端
四、实验 操作步骤演示
操作步骤演示
4.1 获取 OceanBase / TuGraph 数据库
推荐 OBCloud 实例,因为它部署和管理都更加简单,且不需要本地环境支持。
- 注册并开通 OBCloud 实例
- 获取数据库实例连接串
- 创建数据库
- 拉取 TuGraph 镜像
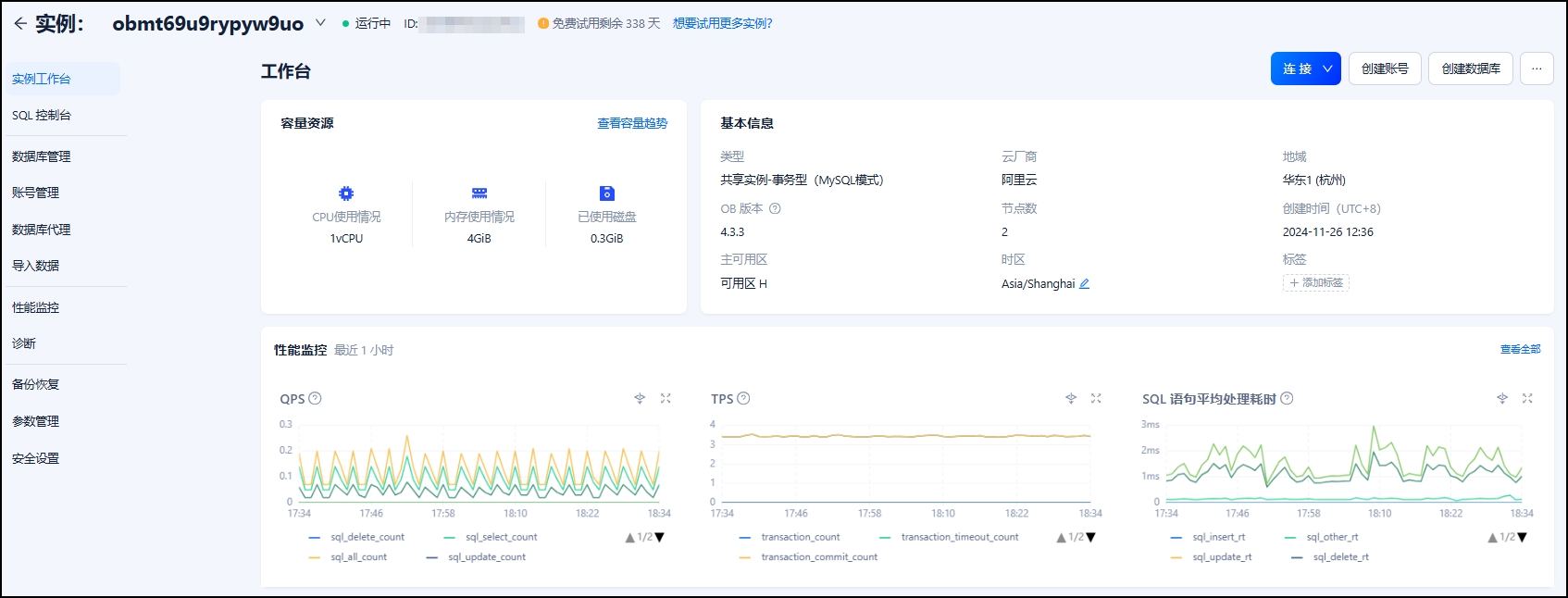
进入实例详情页的“实例工作台”,点击“连接”-“获取连接串”按钮来获取数据库连接串,将其中的连接信息填入后续步骤中创建的 .env 文件内。
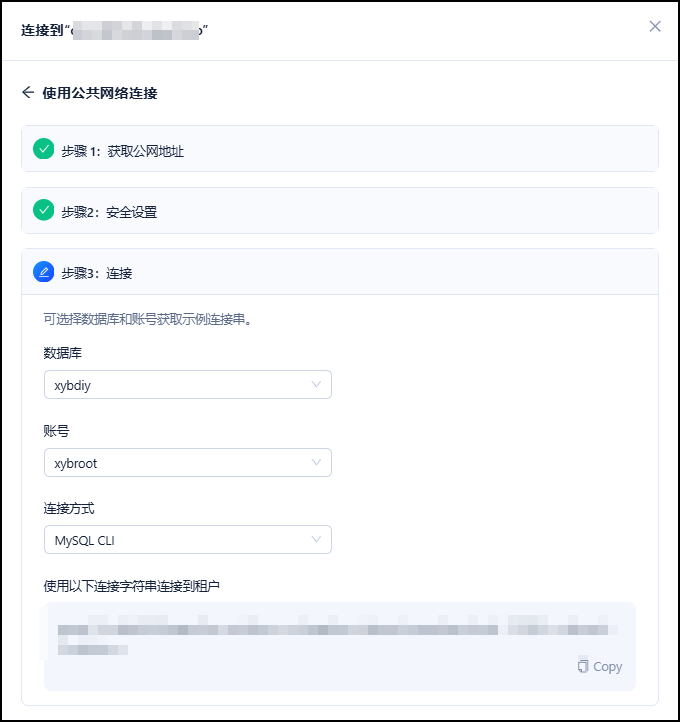
mysql -h xxxxxxxxxxxx.aliyun-cn-hangzhou-internet.oceanbase.cloud -P 3306 -u xybroot -D xybdiy -p
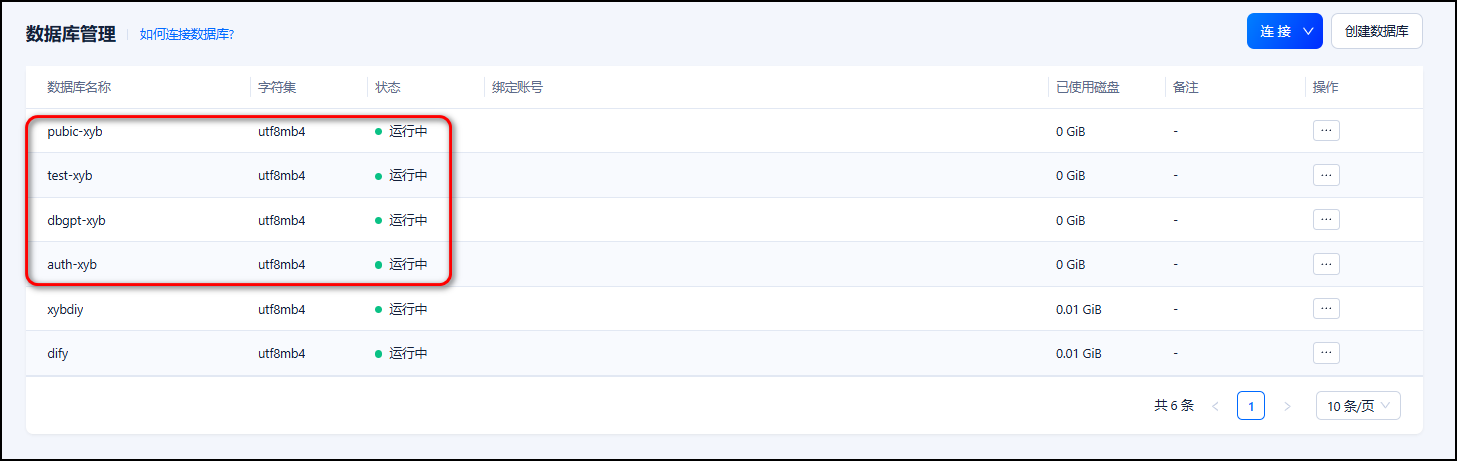
创建数据库以存放示例数据以及向量数据。需要注意的是,在设置数据库名称的时候,为了便于用户在 DB-GPT 前端界面进行后续的操作,强烈不建议用户使用以下四种名称:(因为以下四种数据库名被 DB-GPT 保留,用户虽然能成功在 DB-GPT 侧建立连接,但是无法在 Web UI 中进行后续的应用管理操作)
- auth(auth-xyb)
- dbgpt(dbgpt-xyb)
- test(test-xyb)
- public(pubic-xyb)
安装Docker服务并启用。
[root@db-gpt ~]# yum update -y
[root@db-gpt ~]# yum install -y docker
[root@db-gpt ~]# systemctl start docker
[root@db-gpt ~]# systemctl enable docker
[root@db-gpt ~]# systemctl status docker
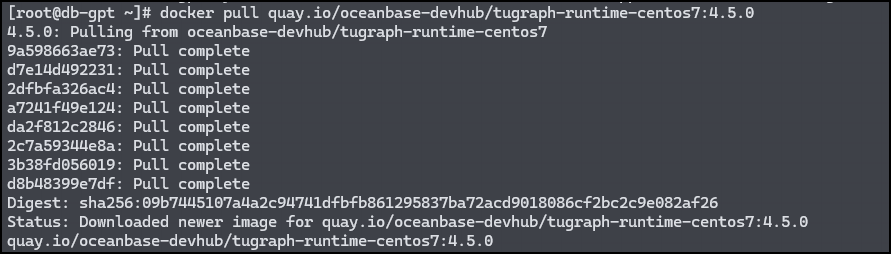
使用以下命令拉取 TuGraph 镜像:
docker pull quay.io/oceanbase-devhub/tugraph-runtime-centos7:4.5.0

4.2 申请模型 API KEY
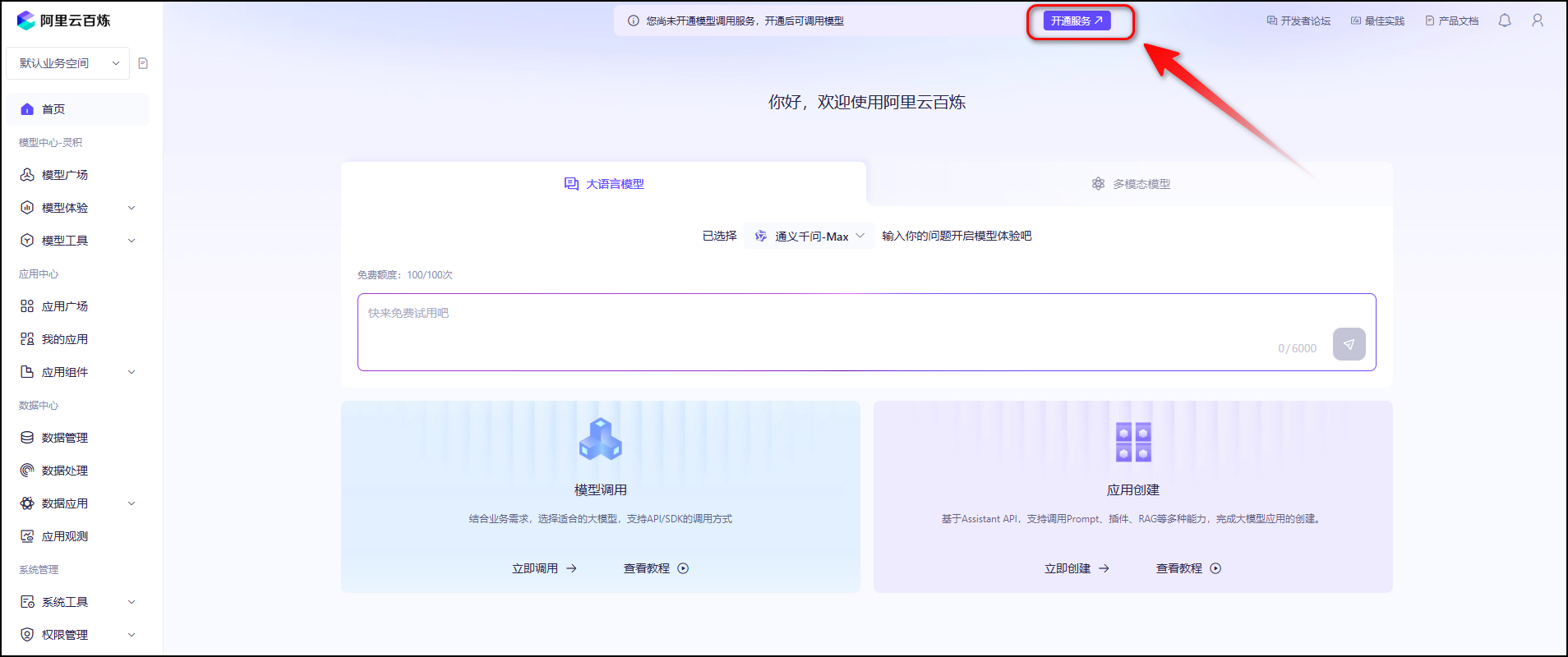
注册链接![]() :https://bailian.console.aliyun.com/
:https://bailian.console.aliyun.com/
注册完阿里云百炼账号后,点击
开通服务。
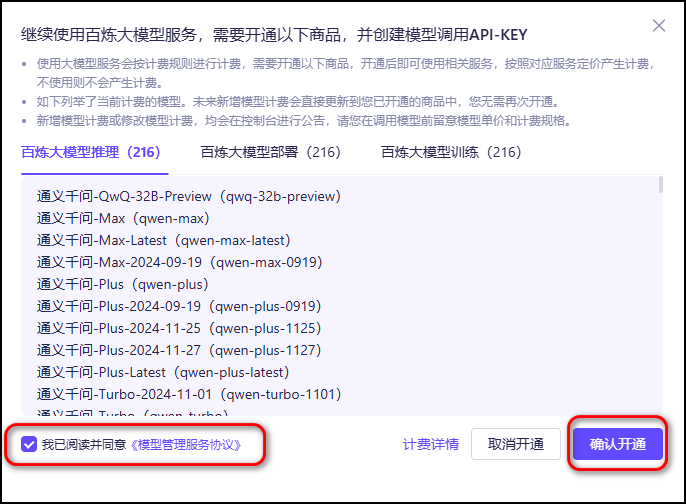
点击
我已阅读并同意《模型管理服务协议》
提示开通成功。
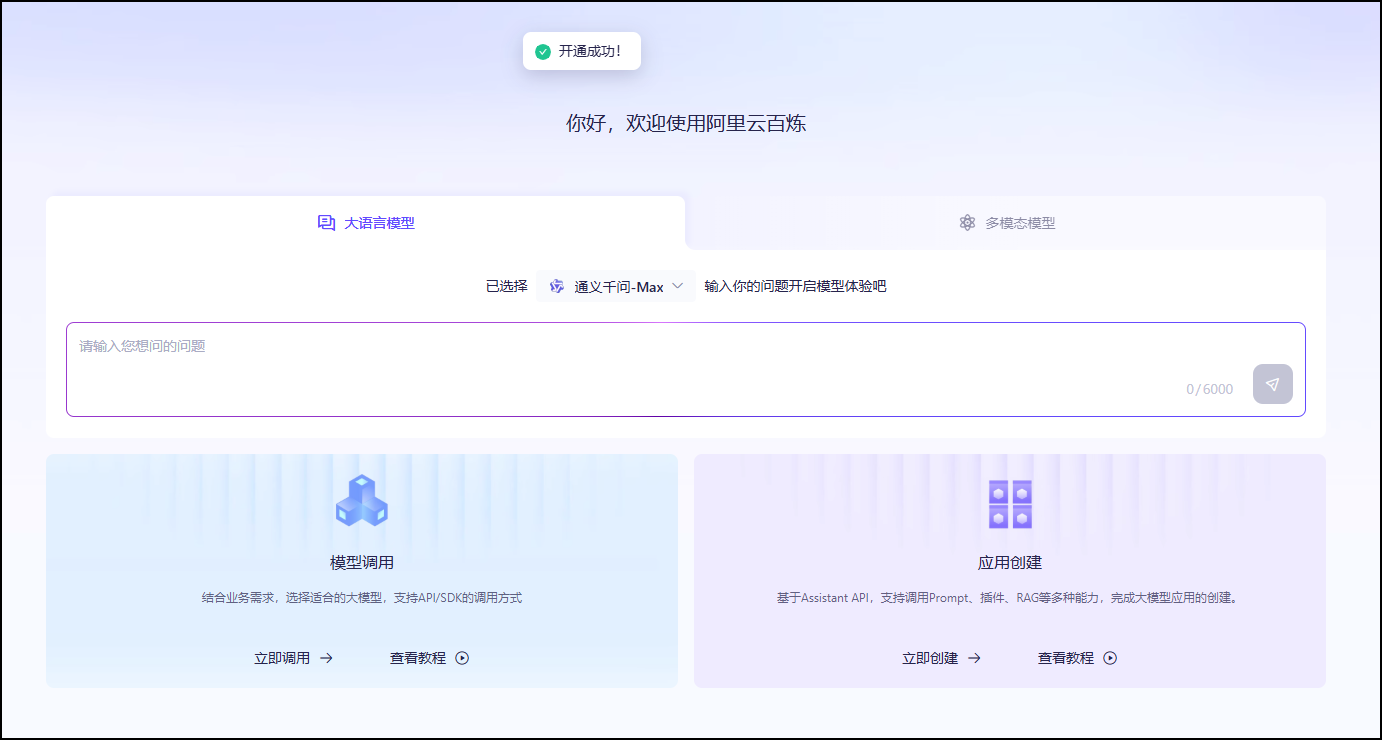
接下来,我们获取API-KEY。

创建API KEY。

我的API-KEY
sk-88exxxxxxxxxxxxxxx96
记录并保存下来。

4.3 克隆项目
用以下指令下载项目代码
git clone https://github.com/oceanbase-devhub/DB-GPT

4.4 拉取 Docker 镜像
docker pull quay.io/oceanbase-devhub/dbgpt:latest

4.5 启动 Docker 容器
进入项目代码所在的目录(以克隆 DB-GPT 项目所在的目录为根目录):
cd ./DB-GPT/docker/compose_examples
执行
create_container_with_config_check.sh脚本:
./create_container_with_config_check.sh
下面请按照脚本要求逐项填写参数配置:
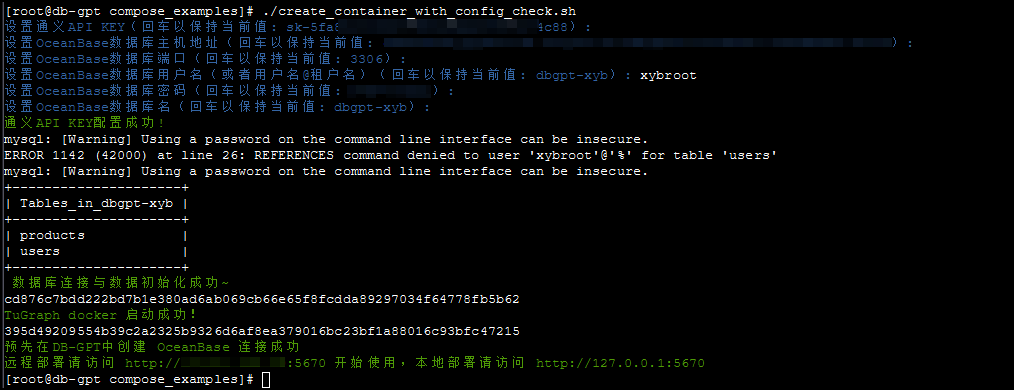
五、访问 DB-GPT 平台
默认情况下,DB-GPT 的前端页面会启动在本机的5670端口上,也就是说可以通过访问当前机器的 IP 来访问 DB-GPT 的界面。也就是说如果我在笔记本上运行的话,我在浏览器上访问localhost即可(或者是内网 IP);如果在服务器上部署 DB-GPT,则需要访问服务器的公网 IP。
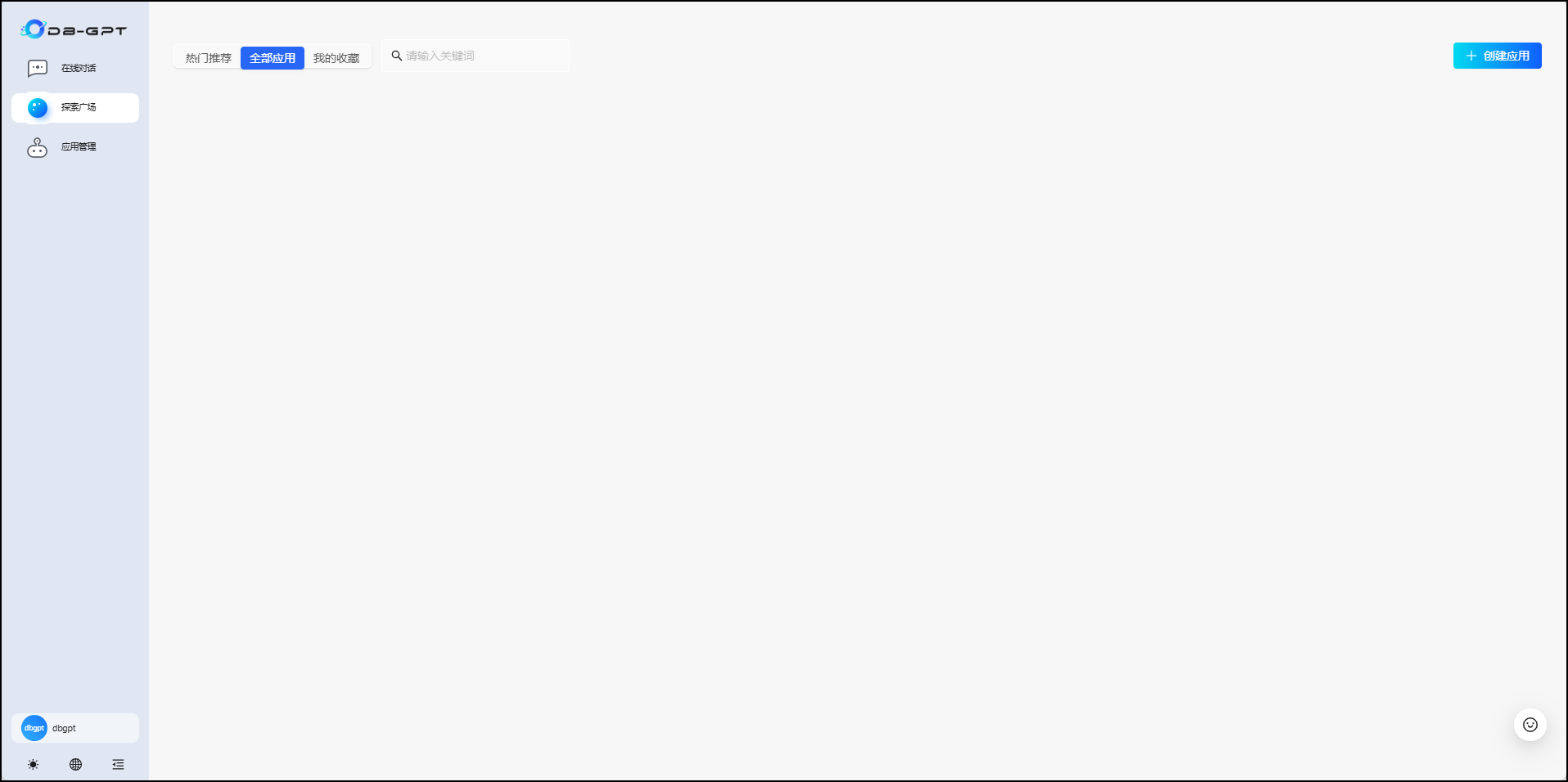
初始界面下是不包含应用的,点击应用管理进入创建流程:
接下来将演示如何创建两种应用类型:
- 典型的知识库
RAG应用; - 基于
text2SQL的chat data应用;
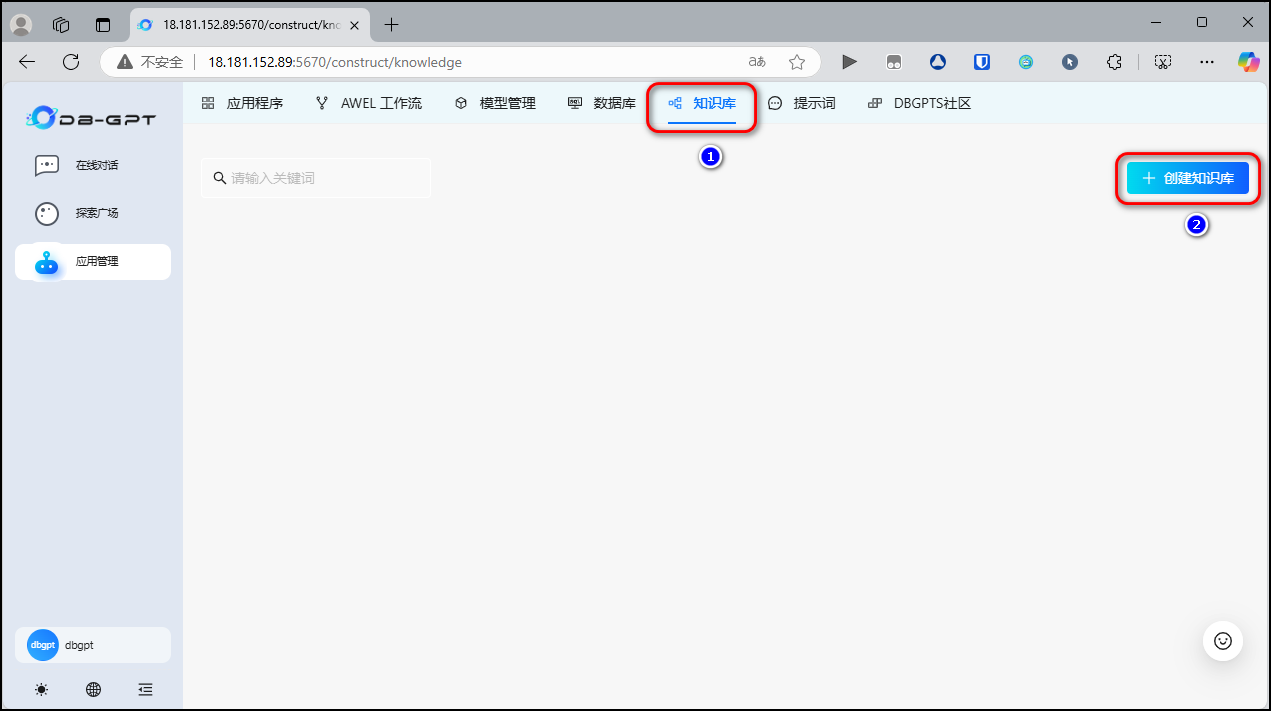
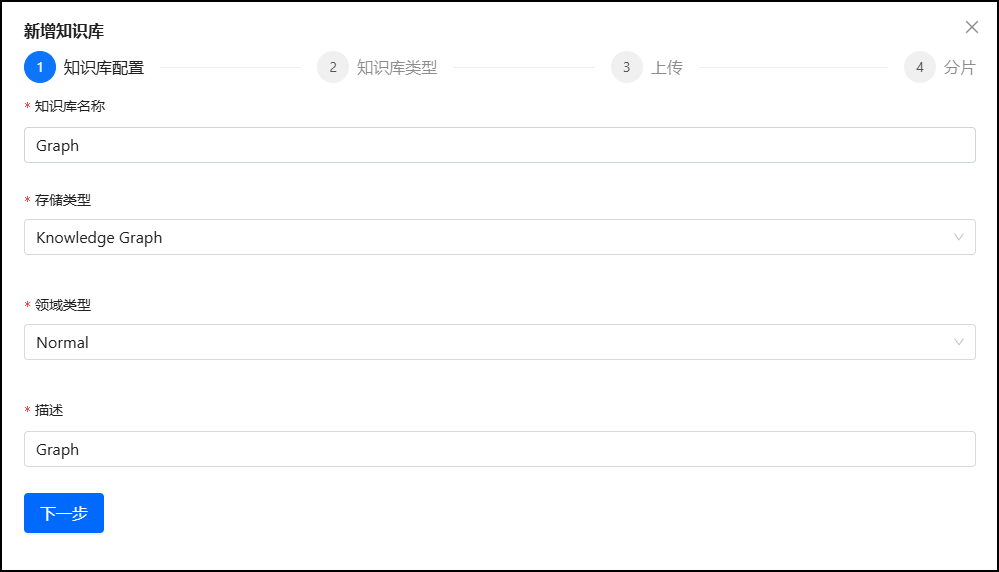
5.1 创建知识库

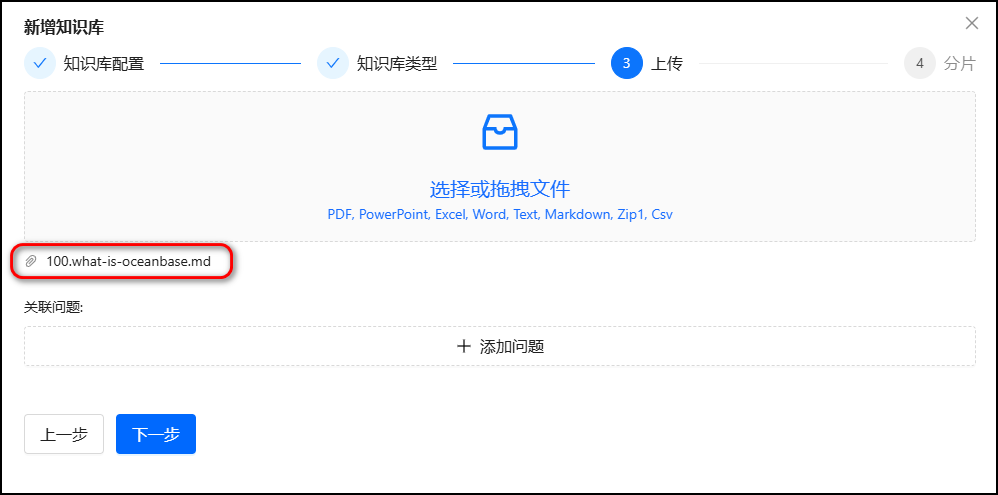
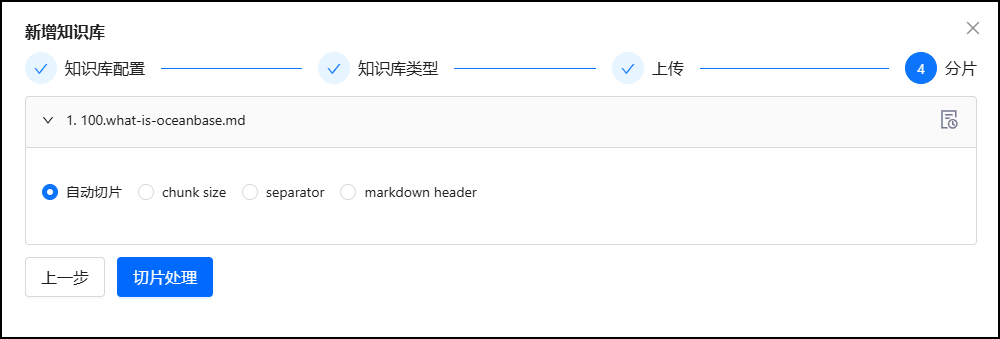
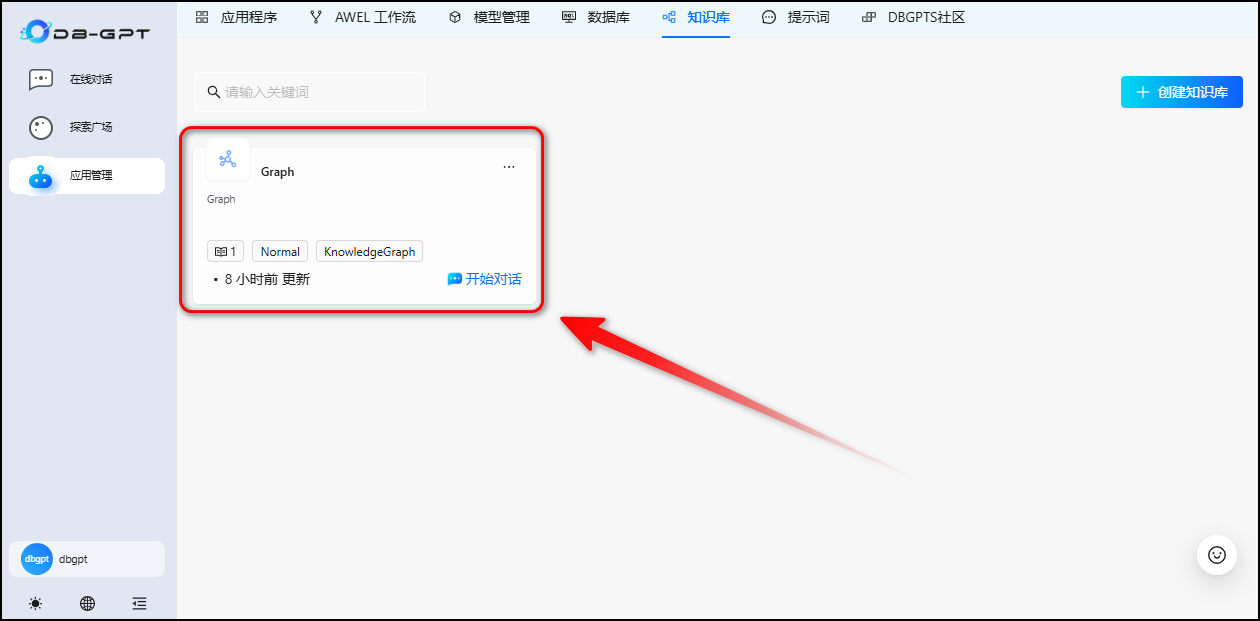
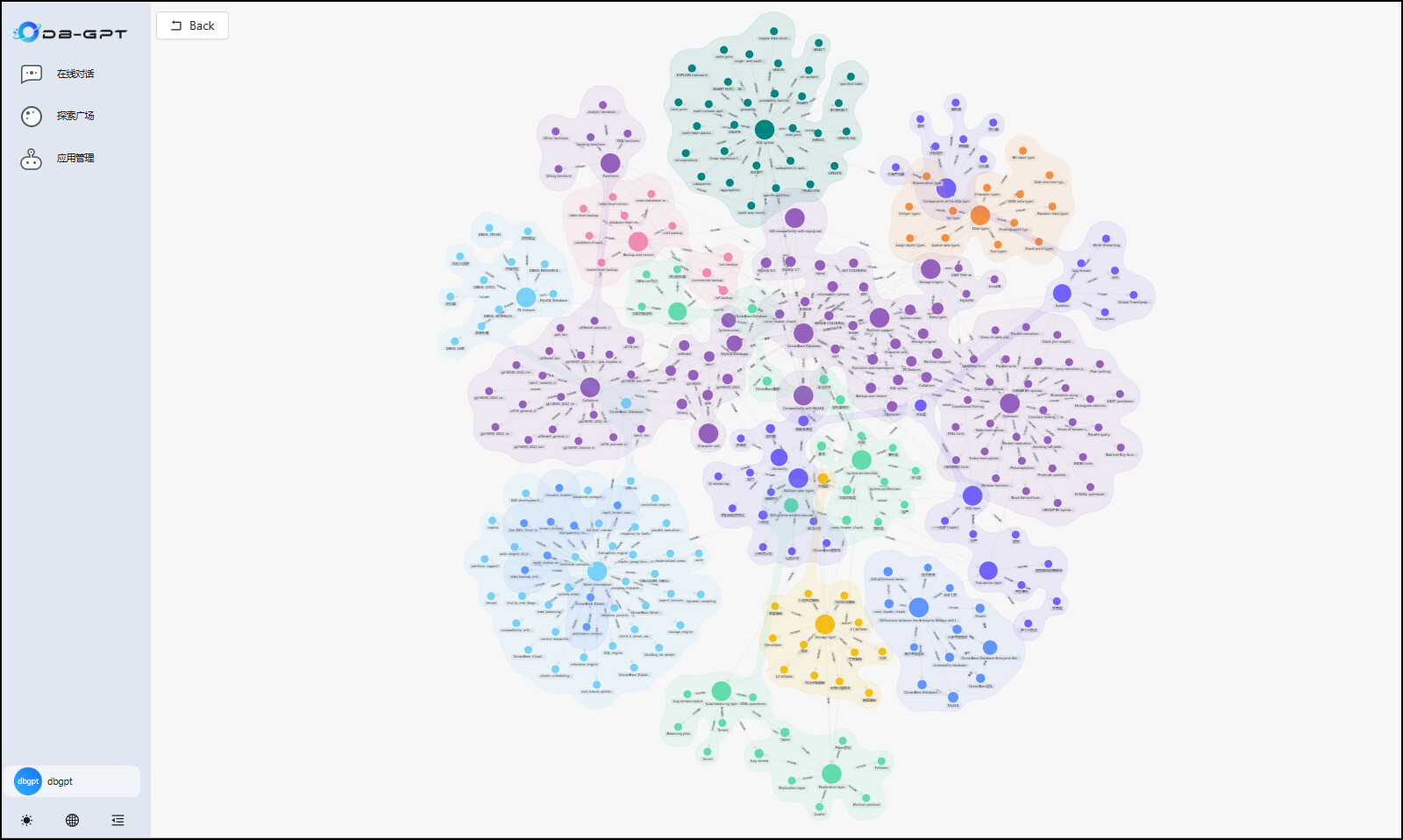
5.2 创建数据库连接
点击数据库,选择OceanBase数据库,Create Now:

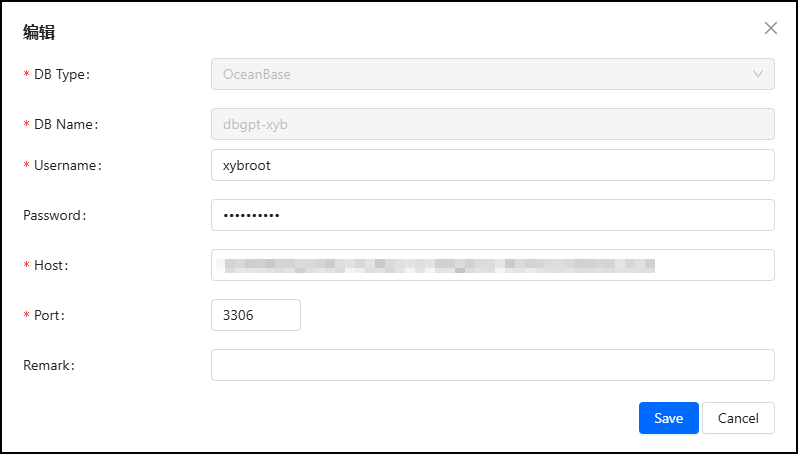
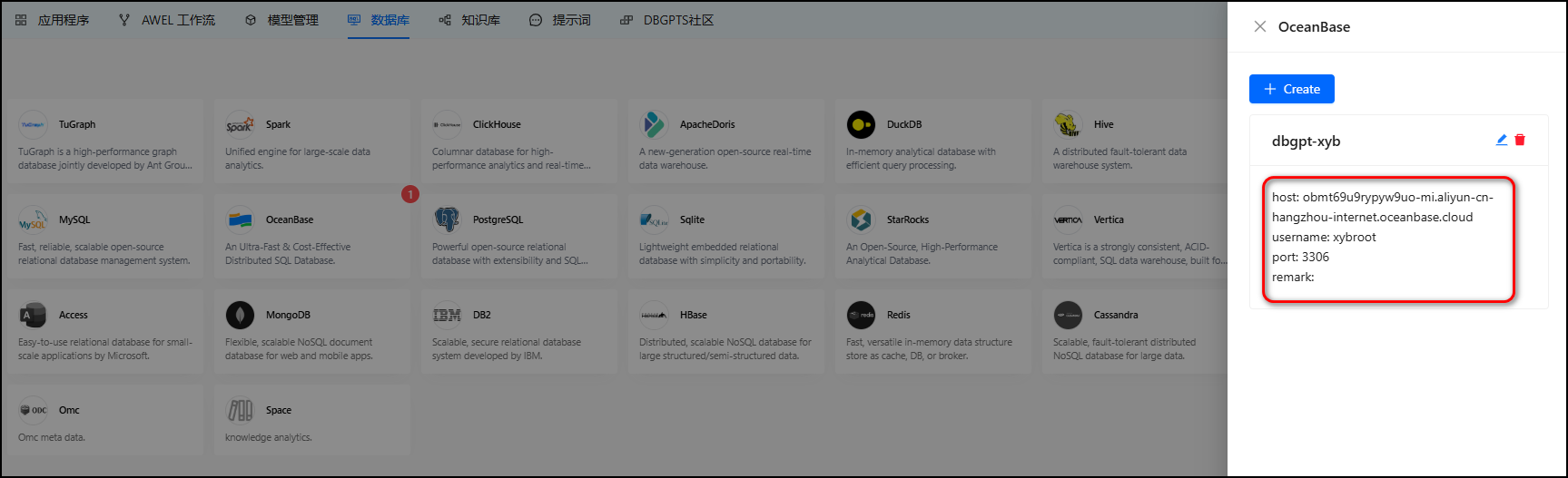
5.3 创建知识库应用
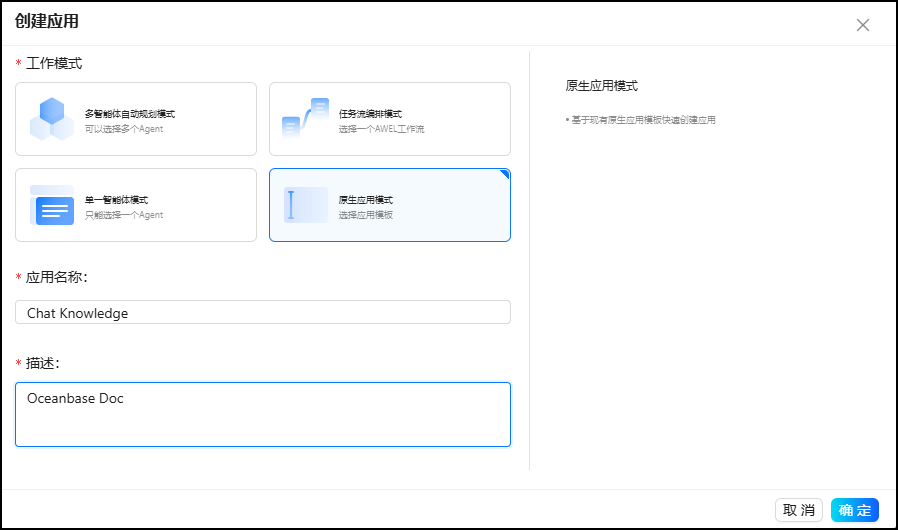
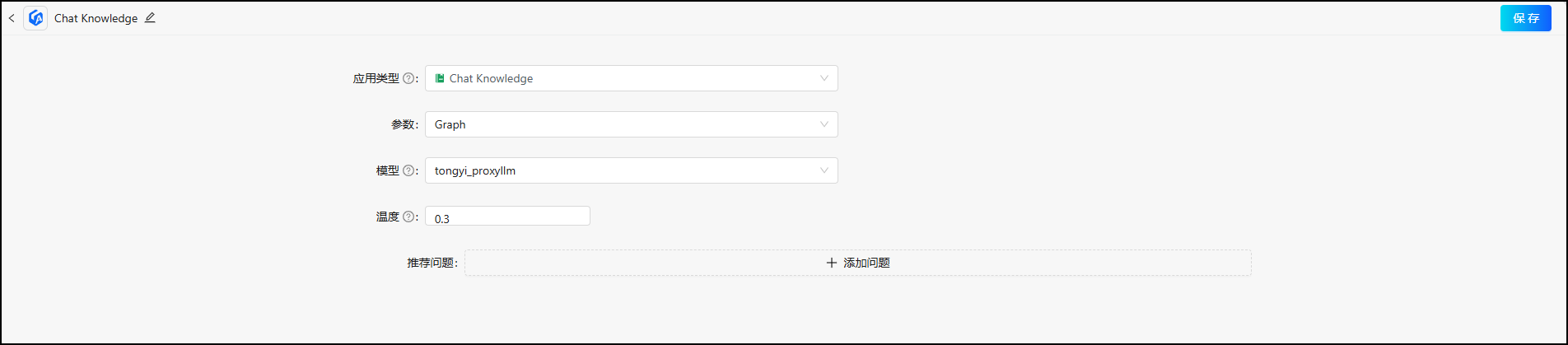
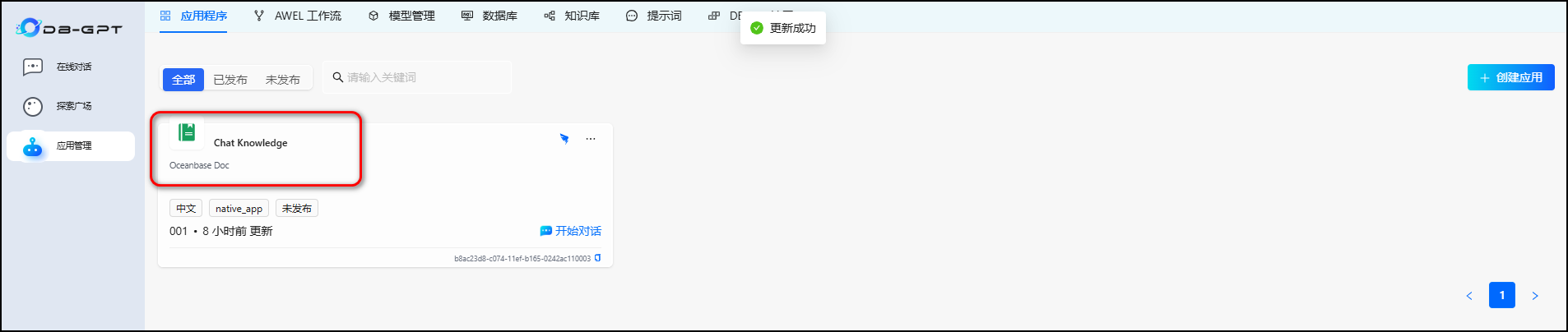
然后我们继续类似地创建 chat data 应用:
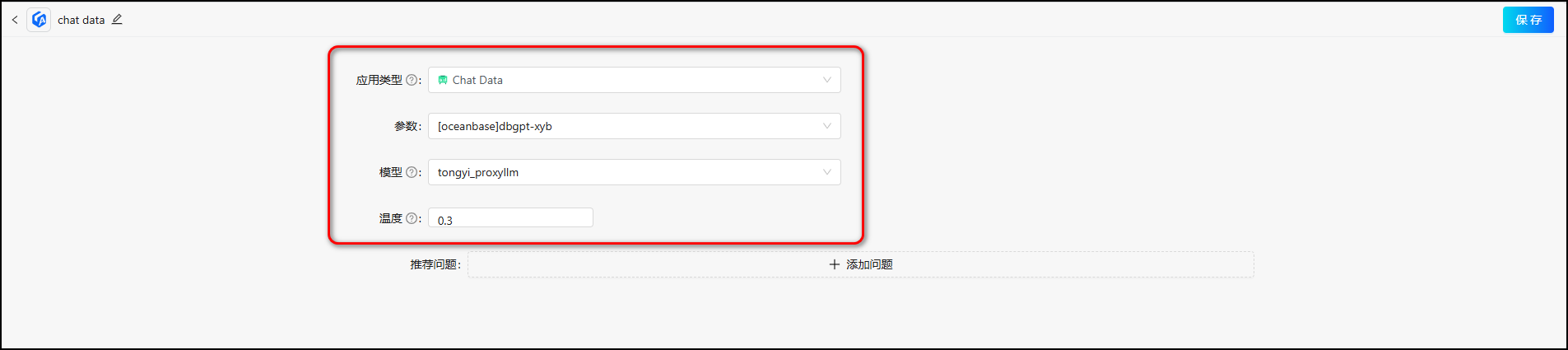
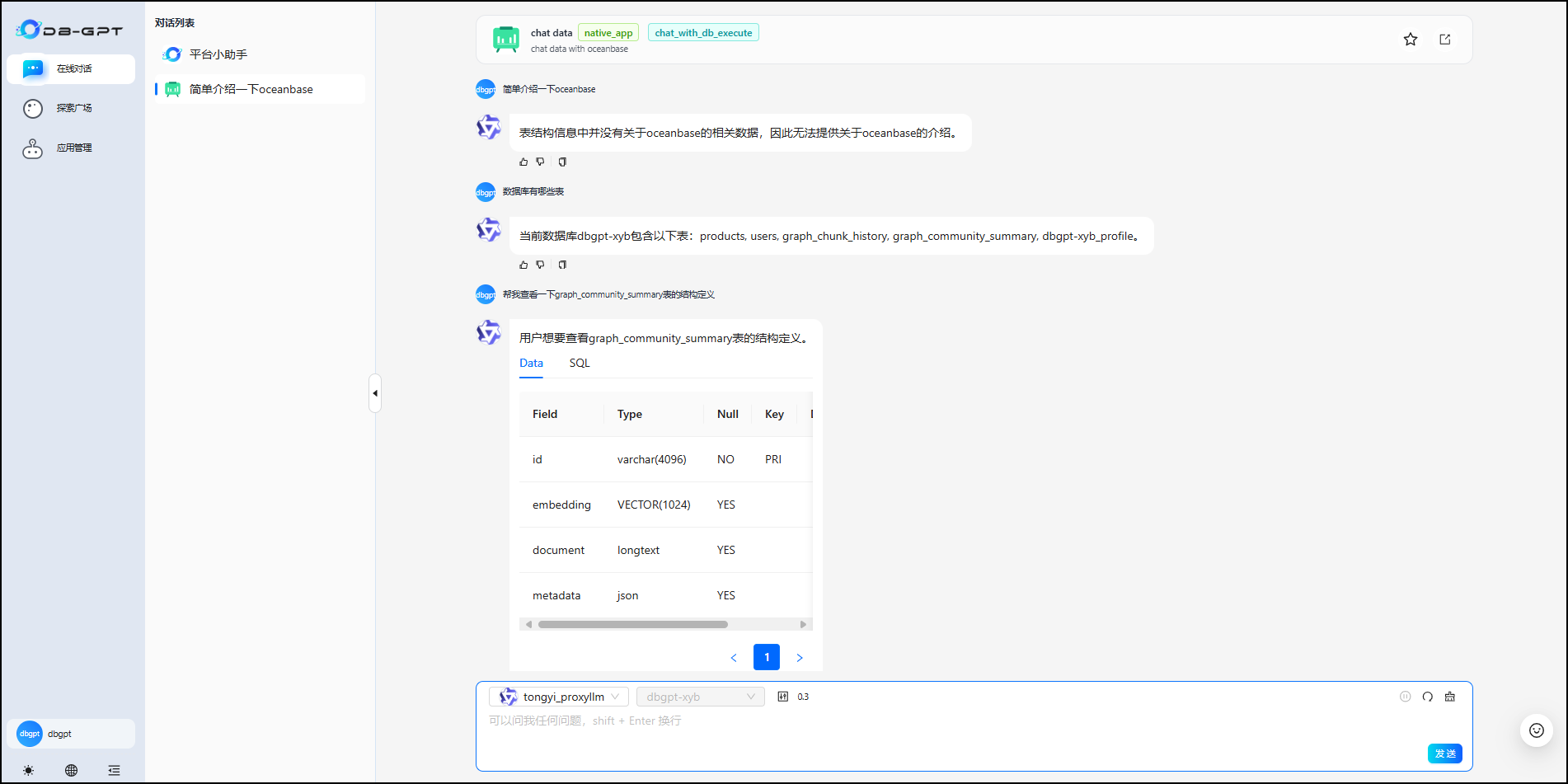
5.4 使用应用
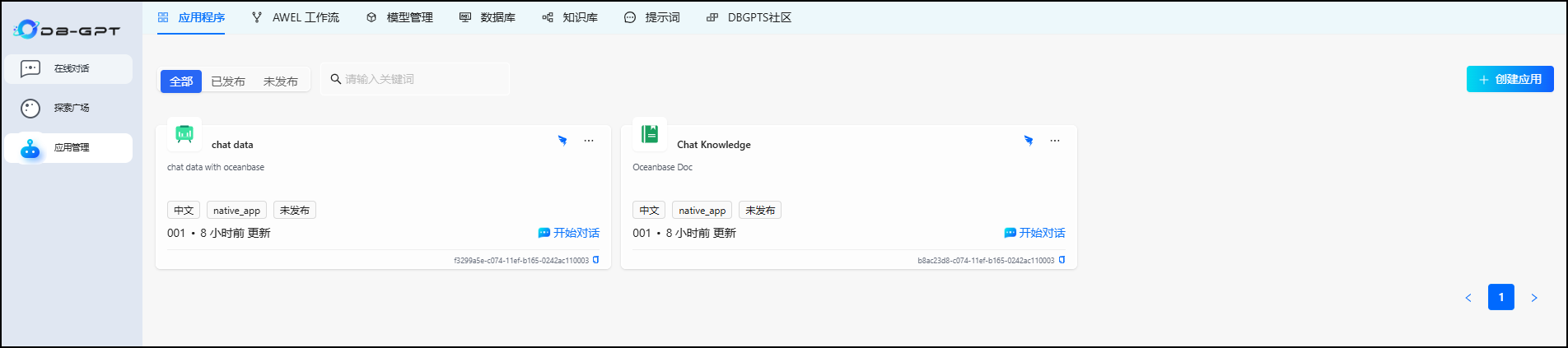
回到应用程序页面,点击开始对话可以进入使用流程:
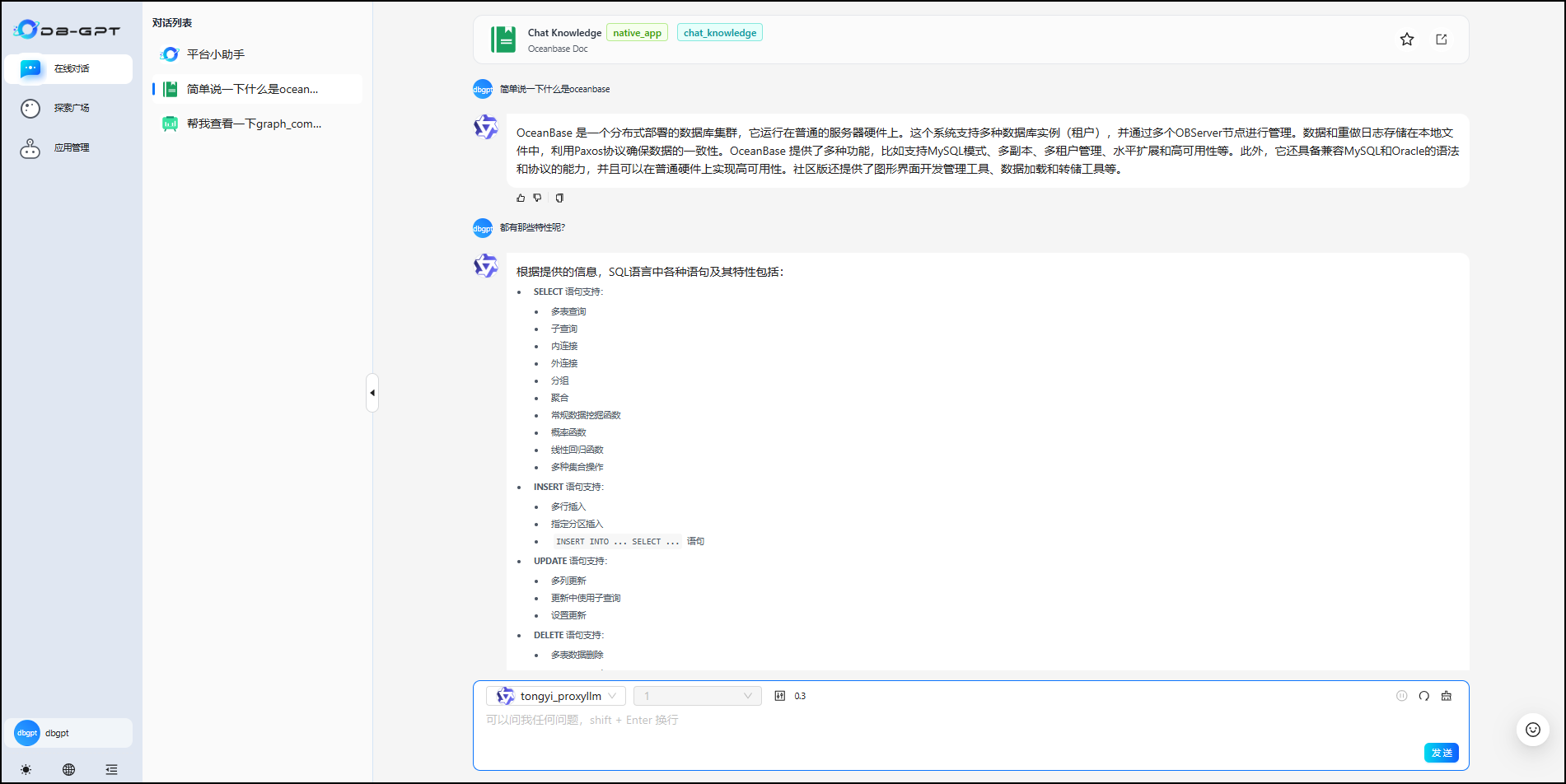
知识库应用——直接键入文本进行交互即可:
六、参考链接
DB-GPT/docker/compose_examples/ob_dbgpt_tutorial.md at main · oceanbase-devhub/DB-GPT