Oceanbase版本:5.7.25-OceanBase_CE-v4.3.3.1
服务器配置:8核16G
服务器负荷:
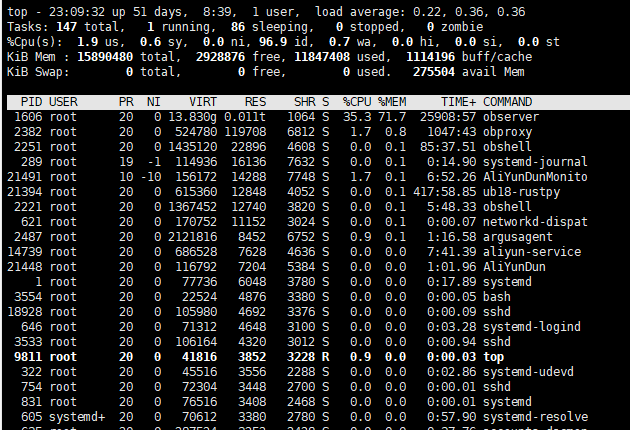
free指令

磁盘情况:

集群配置:
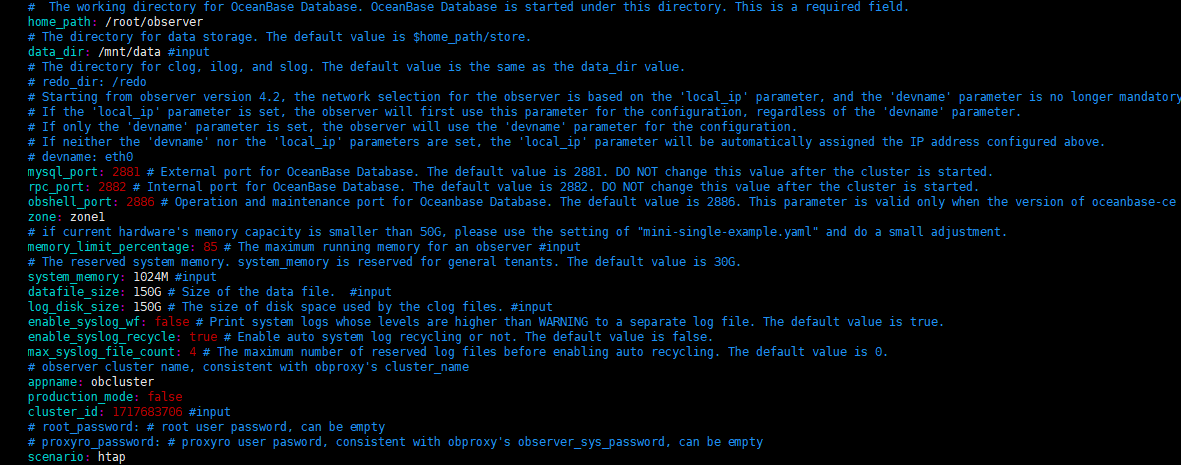
运维信息:
执行的SQL语句:
with
tatol as
(
SELECT
g.`Code` as '供应商编码',
g.Name as '供应商名称',
round(avg(b.GoodsCount),0) as '平均品种数',
round(avg(b.SaleGoodsCount),0) as '平均动销品项数',
concat(round(avg(b.SaleGoodsCount)*1.00 / avg(b.GoodsCount)*100.00,2),'%') as '动销率',
dense_Rank() over(order by avg(b.SaleGoodsCount) *100/ avg(b.GoodsCount) desc) as '动销率排名',
sum(b.SaleAllOrderNum) as '交易笔数',
dense_Rank() over(order by sum(b.SaleAllOrderNum) desc) as '交易笔数排名',
sum(b.SaleAllNum) as '交易数量',
dense_Rank() over(order by sum(b.SaleAllNum) desc) as '交易数量排名',
sum(b.SaleAllAmount) as '交易金额',
dense_Rank() over(order by sum(b.SaleAllAmount) desc) as '交易金额排名',
sum(b.SaleOrderNum) as '销售笔数',
dense_Rank() over(order by sum(b.SaleOrderNum) desc) as '销售笔数排名',
sum(b.SaleNum) as '销售数量',
dense_Rank() over(order by sum(b.SaleNum) desc) as '销售数量排名',
sum(b.SaleAmount) as '销售金额',
dense_Rank() over(order by sum(b.SaleAmount) desc) as '销售金额排名',
sum(b.SaleReturnOrderNum) as '退货笔数',
dense_Rank() over(order by sum(b.SaleReturnOrderNum) desc) as '退货笔数排名',
sum(b.SaleReturnNum) as '退货数量',
dense_Rank() over(order by sum(b.SaleReturnNum) desc) as '退货数量排名',
sum(b.SaleReturnAmount) as '退货金额',
dense_Rank() over(order by sum(b.SaleReturnAmount) desc) as '退货金额排名',
sum(b.SaleMaoli) as '毛利',
dense_Rank() over(order by sum(b.SaleMaoli) desc) as '毛利排名',
Round(sum(b.SaleMaoli)*100/sum(b.SaleAllAmount),2) as '毛利率',
dense_Rank() over(order by Round(sum(b.SaleMaoli)*100/sum(b.SaleAllAmount),2) desc) as '毛利率排名',
avg(b.Amount) as '平均库存',
dense_Rank() over(order by sum(b.Amount) desc) as '平均库存排名'
FROM PurchaseStockSaleBySupplierDaily b
INNER JOIN merchantinfo g on b.SupplierId=g.Id and g.IsDeleted=0 and g.type=2
and g.`ApplyBusinessformatId` = '3a160d58-1ab0-ffe3-40c1-f94269f06d72'
WHERE b.`TenantId` = 2
and b.`ReportDate` between '2024-12-01' and '2024-12-24'
and 1=1
and 1=1
and 1=1
and 1=1
AND b.`OrganizationId` in ('0e85e4aa-0cfa-4437-aa0f-b18f65a3469d','5a107cb3-1180-44a8-83b1-5fe2eb9bfb3c','82ce1a3e-092b-409d-be54-997f7369462a') /*当前登录机构及其权限子机构权限*/
AND 1=1 /*部门权限*/
and G.`BusinessformatId` = '3a160d58-1ab0-ffe3-40c1-f94269f06d72' /*业态权限*/
group by
g.`Code`,
g.Name
)
,
maed as
(
select
供应商编码,
供应商名称,
平均品种数,
平均动销品项数,
动销率,
动销率排名,
交易笔数,
交易笔数排名,
交易数量,
交易数量排名,
交易金额,
交易金额排名,
销售笔数,
销售笔数排名,
销售数量,
销售数量排名,
销售金额,
销售金额排名,
退货笔数,
退货笔数排名,
退货数量,
退货数量排名,
退货金额,
退货金额排名,
毛利,
毛利排名,
毛利率,
毛利率排名,
平均库存,
平均库存排名
from tatol)
SELECT
供应商编码,
供应商名称,
平均品种数,
平均动销品项数,
动销率,
动销率排名,
交易笔数,
交易笔数排名,
交易数量,
交易数量排名,
交易金额,
交易金额排名,
销售笔数,
销售笔数排名,
销售数量,
销售数量排名,
销售金额,
销售金额排名,
退货笔数,
退货笔数排名,
退货数量,
退货数量排名,
退货金额,
退货金额排名,
毛利,
毛利排名,
毛利率,
毛利率排名,
平均库存,
平均库存排名
from maed
order by
销售数量排名 asc limit 0,1
执行结果:
4019 - Size overflow
查询时间: 0.044s
看之前其他朋友也遇到过这个错误,根据大神们的回复,可能是clog或者队列积压问题,我也拿到了部分日志,队列情况:
[2024-12-25 22:51:26.309036] INFO [SERVER.OMT] run1 (ob_multi_tenant.cpp:2534) [1828][MultiTenant][T0][Y0-0000000000000000-0-0] [lt=17] dump tenant info(tenant={id:1002, tenant_meta:{unit:{tenant_id:1002, unit_id:1001, has_memstore:true, unit_status:"NORMAL", config:{unit_config_id:1001, name:"myunit_1", resource:{min_cpu:6, max_cpu:6, memory_size:"8.27734375GB", log_disk_size:"1.5GB", data_disk_size:0, min_iops:9223372036854775807, max_iops:9223372036854775807, iops_weight:6, max_net_bandwidth:INT64_MAX, net_bandwidth_weight:6, }}, mode:0, create_timestamp:1730702847894150, is_removed:false, hidden_sys_data_disk_config_size:0}, super_block:{tenant_id:1002, replay_start_point:ObLogCursor{file_id=43, log_id=10330160, offset=4444845}, ls_meta_entry:{[ver=1,mode=0,seq=764551][2nd=9670]}, tablet_meta_entry:{[ver=1,mode=0,seq=0][2nd=18446744073709551615]}, is_hidden:false, version:4, snapshot_cnt:0, preallocated_seqs:{object_seq:60000, tmp_file_seq:60000, write_seq:60000}, auto_inc_ls_epoch:0, ls_cnt:0}, create_status:1, epoch:0}, unit_min_cpu:"6.000000000000000000e+00", unit_max_cpu:"6.000000000000000000e+00", total_worker_cnt:40, min_worker_cnt:26, max_worker_cnt:150, stopped:0, worker_us:162812390000, recv_hp_rpc_cnt:50054, recv_np_rpc_cnt:22229, recv_lp_rpc_cnt:0, recv_mysql_cnt:24818818, recv_task_cnt:53934, recv_large_req_cnt:0, tt_large_quries:0, pop_normal_cnt:10617784389, workers:26, nesting workers:8, req_queue:total_size=0 queue[0]=0 queue[1]=0 queue[2]=0 queue[3]=0 queue[4]=0 queue[5]=0 , multi_level_queue:total_size=0 queue[0]=0 queue[1]=0 queue[2]=0 queue[3]=0 queue[4]=0 queue[5]=0 queue[6]=0 queue[7]=0 queue[8]=0 queue[9]=0 , recv_level_rpc_cnt:cnt[0]=0 cnt[1]=0 cnt[2]=60 cnt[3]=0 cnt[4]=0 cnt[5]=956 cnt[6]=1126 cnt[7]=0 cnt[8]=0 cnt[9]=0 , group_map:{group_id:15, queue_size:0, recv_req_cnt:1384, min_worker_cnt:2, max_worker_cnt:2, multi_level_queue_:total_size=0 queue[0]=0 queue[1]=0 queue[2]=0 queue[3]=0 queue[4]=0 queue[5]=0 queue[6]=0 queue[7]=0 queue[8]=0 queue[9]=0 , recv_level_rpc_cnt:cnt[0]=0 cnt[1]=0 cnt[2]=0 cnt[3]=0 cnt[4]=0 cnt[5]=0 cnt[6]=0 cnt[7]=0 cnt[8]=0 cnt[9]=0 , worker_cnt:0, nesting_worker_cnt:0, token_change:1735137895097606}{group_id:20, queue_size:0, recv_req_cnt:38673, min_worker_cnt:6, max_worker_cnt:150, multi_level_queue_:total_size=0 queue[0]=0 queue[1]=0 queue[2]=0 queue[3]=0 queue[4]=0 queue[5]=0 queue[6]=0 queue[7]=0 queue[8]=0 queue[9]=0 , recv_level_rpc_cnt:cnt[0]=0 cnt[1]=0 cnt[2]=0 cnt[3]=0 cnt[4]=0 cnt[5]=0 cnt[6]=0 cnt[7]=0 cnt[8]=0 cnt[9]=0 , worker_cnt:0, nesting_worker_cnt:0, token_change:1735063262139213}{group_id:2, queue_size:0, recv_req_cnt:35483370, min_worker_cnt:6, max_worker_cnt:150, multi_level_queue_:total_size=0 queue[0]=0 queue[1]=0 queue[2]=0 queue[3]=0 queue[4]=0 queue[5]=0 queue[6]=0 queue[7]=0 queue[8]=0 queue[9]=0 , recv_level_rpc_cnt:cnt[0]=0 cnt[1]=0 cnt[2]=0 cnt[3]=0 cnt[4]=0 cnt[5]=0 cnt[6]=0 cnt[7]=0 cnt[8]=0 cnt[9]=0 , worker_cnt:6, nesting_worker_cnt:0, token_change:1730702857416280}{group_id:21, queue_size:0, recv_req_cnt:3100, min_worker_cnt:6, max_worker_cnt:150, multi_level_queue_:total_size=0 queue[0]=0 queue[1]=0 queue[2]=0 queue[3]=0 queue[4]=0 queue[5]=0 queue[6]=0 queue[7]=0 queue[8]=0 queue[9]=0 , recv_level_rpc_cnt:cnt[0]=0 cnt[1]=0 cnt[2]=0 cnt[3]=0 cnt[4]=0 cnt[5]=0 cnt[6]=0 cnt[7]=0 cnt[8]=0 cnt[9]=0 , worker_cnt:0, nesting_worker_cnt:0, token_change:1735050623554516}, rpc_stat_info: pcode=0x150a:cnt=40 pcode=0x150b:cnt=40, token_change_ts:1735050571263847, tenant_role:1})
看输出应该是无积压队列,clog我看是建议配置成内存的3倍,之前的确实有点小,1.5G,,查看租户clog信息如下:
±-------------±---------±----------±--------------±----------------+
| SVR_IP | SVR_PORT | TENANT_ID | LOG_DISK_SIZE | LOG_DISK_IN_USE |
±-------------±---------±----------±--------------±----------------+
| 172.17.149.3 | 2882 | 1002 | 1610612736 | 1285945425 |
±-------------±---------±----------±--------------±----------------+
将资源clog配置成30G
±-------------±---------±----------±--------------±----------------+
| SVR_IP | SVR_PORT | TENANT_ID | LOG_DISK_SIZE | LOG_DISK_IN_USE |
±-------------±---------±----------±--------------±----------------+
| 172.17.149.3 | 2882 | 1002 | 28991029248 | 1286013524 |
±-------------±---------±----------±--------------±----------------+
问题依旧。
附带日志错误:

完整错误信息
observer.log (1.0 MB)
跟数据貌似有关系,我注释了SQL中的其中一行
-- AND b.`OrganizationId` in ('0e85e4aa-0cfa-4437-aa0f-b18f65a3469d','5a107cb3-1180-44a8-83b1-5fe2eb9bfb3c','82ce1a3e-092b-409d-be54-997f7369462a') /*当前登录机构及其权限子机构权限*/
竟然就不报错,按说去掉一个条件数据量应该更大更容易出错才对,去掉一个where条件反而没事。整体数据库不大,with的tatol中的行数其实才几十行。
因为是客户环境有问题,我们测试环境也没有重现,请大神帮忙分析一下,感谢。