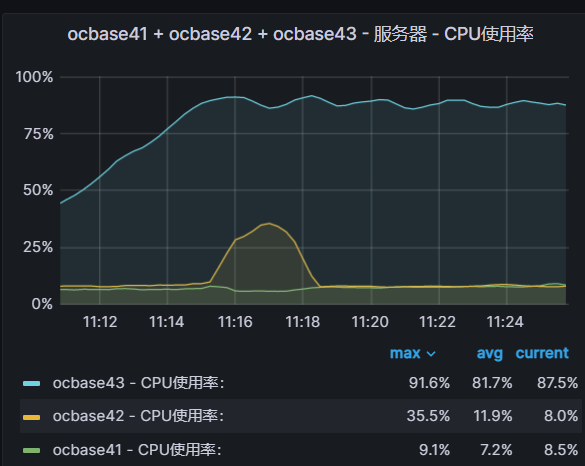
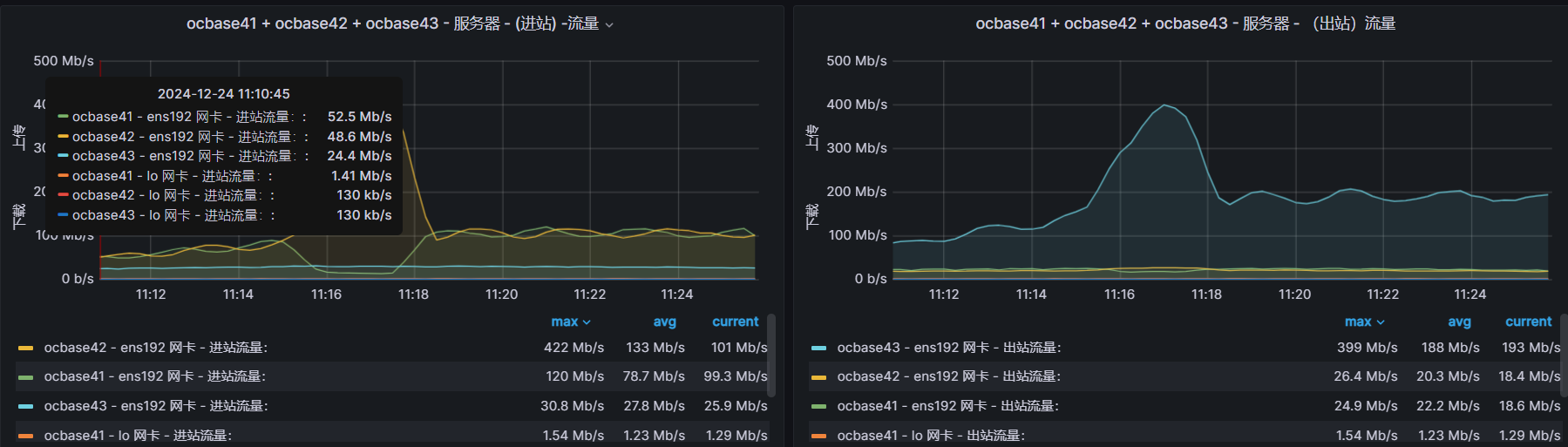
OB 三节点提供同时读写能力并不是说部署了三节点就一定都有访问。其次,都有访问的时候也并不是说三节点的负载就会严格一样。 决定节点负载的关键是租户在该节点上是否有主副本数据被业务读写,或者说是否有日志流。
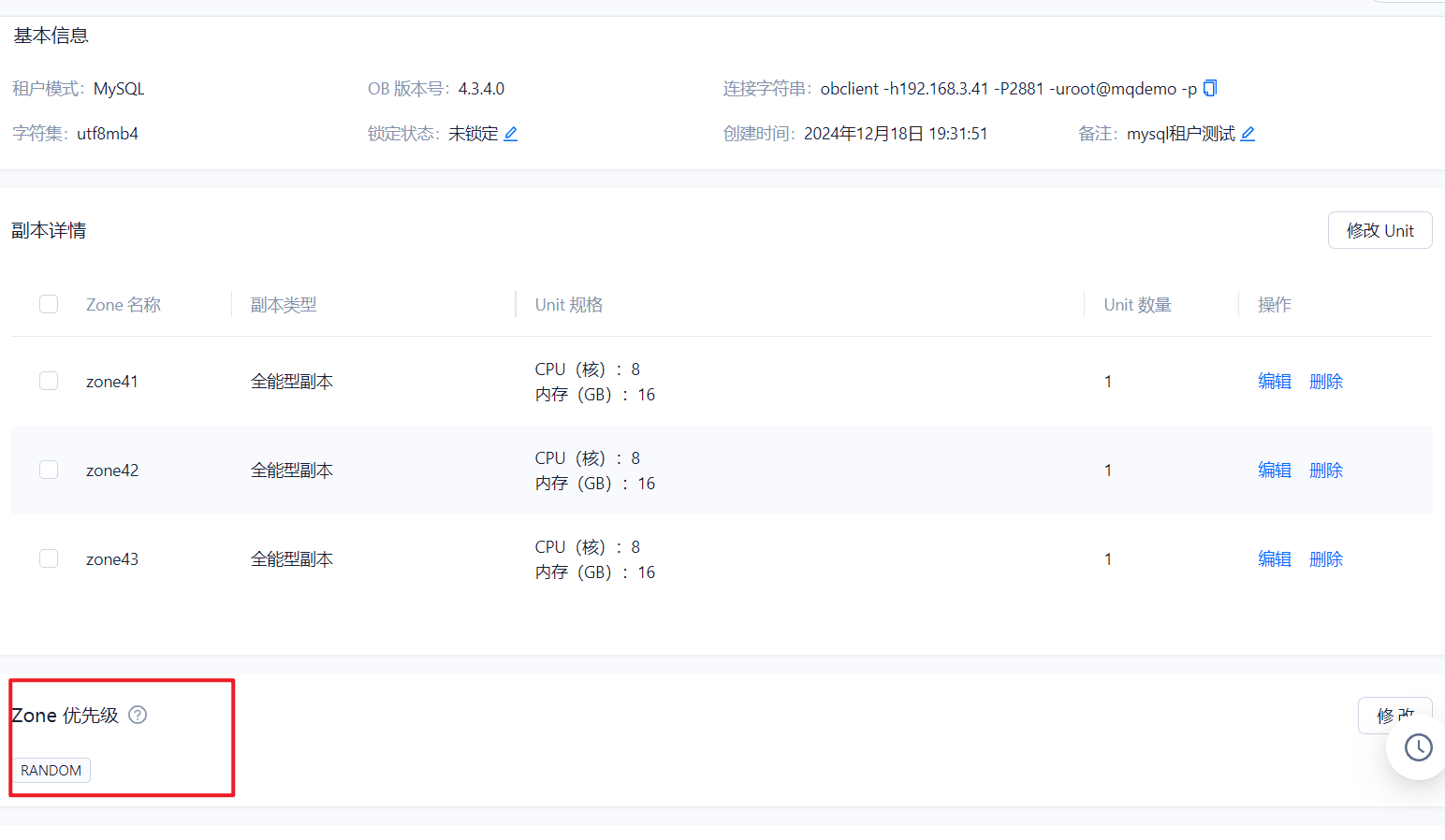
PRIMARY_ZONE 已经设置为 RANDOM , 理论上租户在每个节点上都有一个业务日志流,也有对应的表的分区的主副本在该节点上(前提是有多个表或者一个分区表)。 只要节点上有表的主副本数据,测试数据分布均匀的情形下,节点上就会有读写请求。
三节点负载是否均衡一看业务数据主副本在三节点上的分布情况,二看对应的数据访问请求分布情况。二者如果都不均匀,最终节点负载差异也会很多。一跟 OB 的能力有关,二跟业务特点有关。
所以,分析这个问题,需要两个具体的信息:
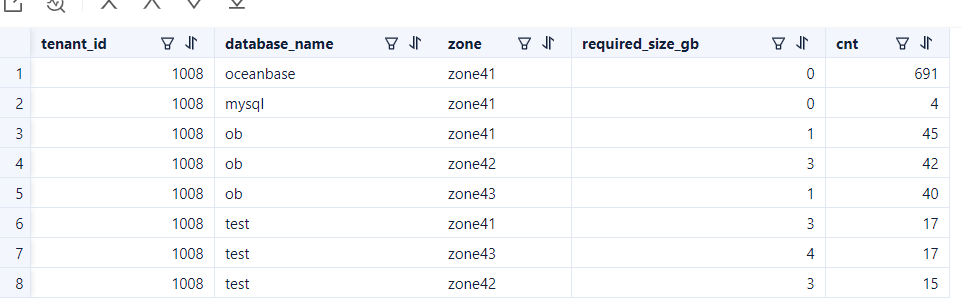
业务表的主副本分布位置特点。
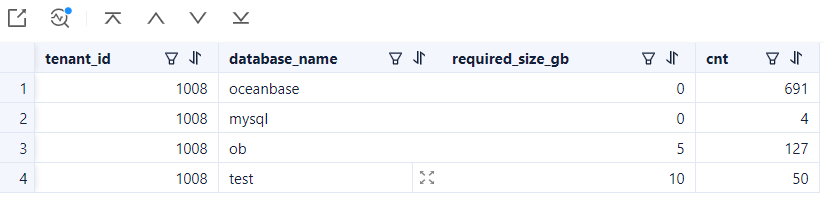
SELECT /*+ read_consistency(weak) query_timeout(1000000000) */ t1.tenant_id, t1.database_name, round(sum(t2.required_size)/1024/1024/1024) required_size_gb, count(*) cnt
FROM oceanbase.CDB_OB_TABLE_LOCATIONS t1
JOIN oceanbase.cdb_ob_tablet_replicas t2 ON (t1.tenant_id=t2.tenant_id and t1.tablet_id=t2.tablet_id AND t1.ls_id=t2.ls_id and t1.svr_ip=t2.svr_ip and t1.SVR_PORT=t2.svr_port )
WHERE t1.tenant_id in (1002) and t1.ROLE='LEADER'
GROUP BY t1.tenant_id, t1.database_name
;
SELECT /*+ read_consistency(weak) query_timeout(1000000000) */ t1.tenant_id, t1.database_name, t1.zone, round(sum(t2.required_size)/1024/1024/1024) required_size_gb, count(*) cnt
FROM oceanbase.CDB_OB_TABLE_LOCATIONS t1
JOIN oceanbase.cdb_ob_tablet_replicas t2 ON (t1.tenant_id=t2.tenant_id and t1.tablet_id=t2.tablet_id AND t1.ls_id=t2.ls_id and t1.svr_ip=t2.svr_ip and t1.SVR_PORT=t2.svr_port )
WHERE t1.tenant_id in (1002) and t1.ROLE='LEADER'
GROUP BY t1.tenant_id, t1.database_name, t1.zone
;