

17:44启动
17:47第一个节点172.69.0.90就挂了
18:03第二个节点172.69.0.92挂了
172.69.0.90-observer.7z (2.8 MB)
172.69.0.92-observer.7z (2.0 MB)
172.69.0.94-observer.7z (295.7 KB)
节点2(92)和节点3(94)都将节点1(90)拉入黑名单了,节点1报错误 IO error,io handle wait failed,大概率节点1磁盘有问题,建议更换节点1试下;节点2被节点3加入了黑名单,检查下节点2是否有网络层面的限制,例如iptables
节点2:
[2024-12-20 17:52:15.183479] WDIAG [RPC] check_blacklist (ob_poc_rpc_proxy.cpp:273) [147411][AutoLSLocRpc][T0][YB42AC45005C-000629B07FF74F03-0-0] [lt=19][errcode=-4122] address in blacklist(ret=-4122, addr="172.69.0.90:2882")
[2024-12-20 17:52:15.183574] WDIAG [RPC] post (ob_poc_rpc_proxy.h:235) [147411][AutoLSLocRpc][T0][YB42AC45005C-000629B07FF74F03-0-0] [lt=90][errcode=-4122] check_blacklist failed(addr="172.69.0.90:2882")
节点3:
将节点1加入黑名单
[2024-12-20 18:12:22.320657] WDIAG [RPC] check_blacklist (ob_poc_rpc_proxy.cpp:273) [112607][PxTargetMgr0][T0][Y0-0000000000000000-0-0] [lt=1][errcode=-4122] address in blacklist(ret=-4122, addr="172.69.0.90:2882")
[2024-12-20 18:12:22.320760] WDIAG [RPC] send (ob_poc_rpc_proxy.h:150) [112607][PxTargetMgr0][T0][Y0-0000000000000000-0-0] [lt=99][errcode=-4122] check_blacklist failed(ret=-4122)
将节点2加入黑名单
[2024-12-20 18:12:34.343942] WDIAG [RPC] check_blacklist (ob_poc_rpc_proxy.cpp:273) [112184][T1_LogUpdater][T1][Y0-0000000000000000-0-0] [lt=1][errcode=-4122] address in blacklist(ret=-4122, addr="172.69.0.92:2882")
[2024-12-20 18:12:34.344015] WDIAG [RPC] send (ob_poc_rpc_proxy.h:150) [112184][T1_LogUpdater][T1][Y0-0000000000000000-0-0] [lt=70][errcode=-4122] check_blacklist failed(ret=-4122)
[2024-12-20 18:12:34.344055] WDIAG [CLOG] post_sync_request_to_server_ (log_net_service.h:347) [112184][T1_LogUpdater][T1][Y0-0000000000000000-0-0] [lt=22][errcode=-4122] ObLogRpc post_sync_request failed(ret=-4122, palf_id=1, req={get_type:1}, server="172.69.0.92:2882")
节点1:
[2024-12-20 17:44:26.755591] WDIAG [COMMON] wait (ob_io_define.cpp:1877) [113551][observer][T0][Y0-0000000000000001-0-0] [lt=56][errcode=-4224] IO error, (ret=-4224, *result_={is_inited_:true, is_finished_:true, is_canceled_:false, has_estimated_:false, complete_size_:0, offset_:0, size_:66060288, timeout_us_:10000000, result_ref_cnt_:1, out_ref_cnt_:1, flag_:{mode:"READ", group_id_:0, func_type_:0, wait_event_id_:3, is_sync_:false, is_unlimited_:false, is_detect_:false, is_write_through_:false, is_sealed_:true, is_time_detect_:false, need_close_dev_and_fd_:false, reserved_:0}, ret_code_:{io_ret_:-4224, fs_errno_:0}, tenant_id_:500, tenant_io_mgr_:{ptr:0x2b09efdf8030}, user_data_buf_:0x2b0a1da05000, buf_:null, io_callback_:null, time_log:{begin_ts:1734687866755248, enqueue_used:-1, dequeue_used:-1, submit_used:1734687866755308, return_used:46, callback_enqueue_used:-1, callback_dequeue_used:-1, callback_finish_used:-1, end_used:1734687866755563}})
[2024-12-20 17:44:26.755692] WDIAG [COMMON] read (ob_io_manager.cpp:473) [113551][observer][T0][Y0-0000000000000001-0-0] [lt=97][errcode=-4224] io handle wait failed(ret=-4224, info={tenant_id_:500, fd_:{first_id:-1, second_id:186, third_id:-1, fd_id:-1, slot_version:-1, device_handle:0x2b09eec4a080}, offset_:0, size_:66060288, timeout_us_:10000000, flag_:{mode:"READ", group_id_:0, func_type_:0, wait_event_id_:3, is_sync_:false, is_unlimited_:false, is_detect_:false, is_write_through_:false, is_sealed_:true, is_time_detect_:false, need_close_dev_and_fd_:false, reserved_:0}, callback_:null, buf_:null, user_data_buf_:0x2b0a1da05000, part_id:-1}, info.timeout_us_=10000000)
1 个赞
怎样才能保证磁盘没问题? 节点1已经是更换过一次了,之前使用OCP部署集群的时候有个IO问题,当时是把节点1更换成了现在这个
1 个赞
我也想知道
一些年久老旧的磁盘会经常有问题,建议经常做下巡检,关注相关告警,及时替换有问题的磁盘,另外建议使用SSD盘。
有什么性能标准要求吗?现在就是SSD盘
SSD盘就可以的
高技术含量
这个问题有进展了吗?
提供一个排查方法:目前看来节点3是没有问题的,3个节点你可以分别独立部署,验证下是否每个节点都能部署并运行成功;然后分别1和3,2和3部署 看下是否都能部署成功,这样一步步排除问题
麻烦确认下
1.操作系统类型及版本
2.你说的挂掉是observer进程不在了吗?ps -ef|grep observer
3.发下节点3单独部署的yaml文件

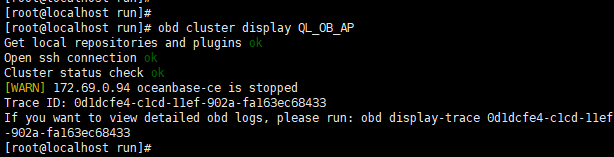
挂掉了,我是从obd命令看的
在分析中
1.麻烦参考这两篇文档配置下core参数及路径,然后再将昨天单独部署的节点3启动下,应该会有core文件出来
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000001576682
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000001576680
2.lscpu 看下
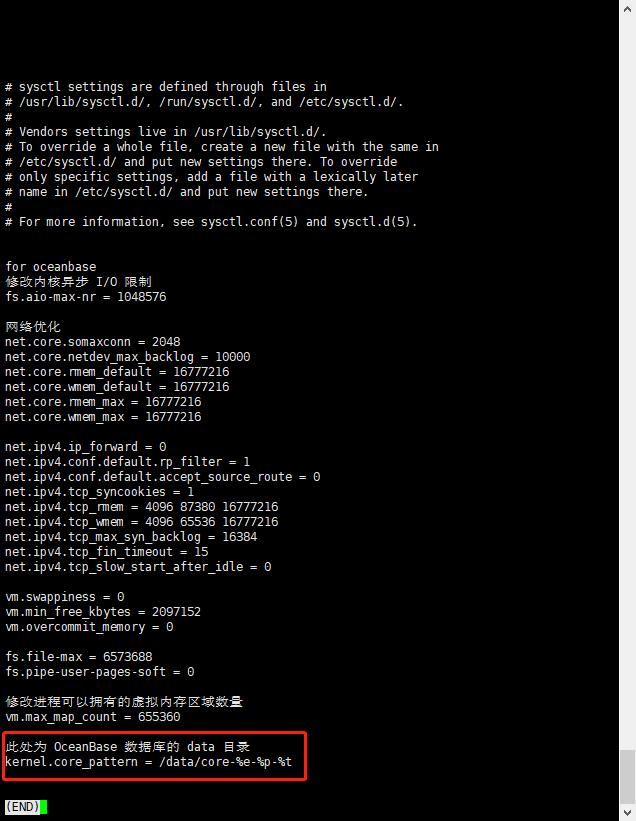
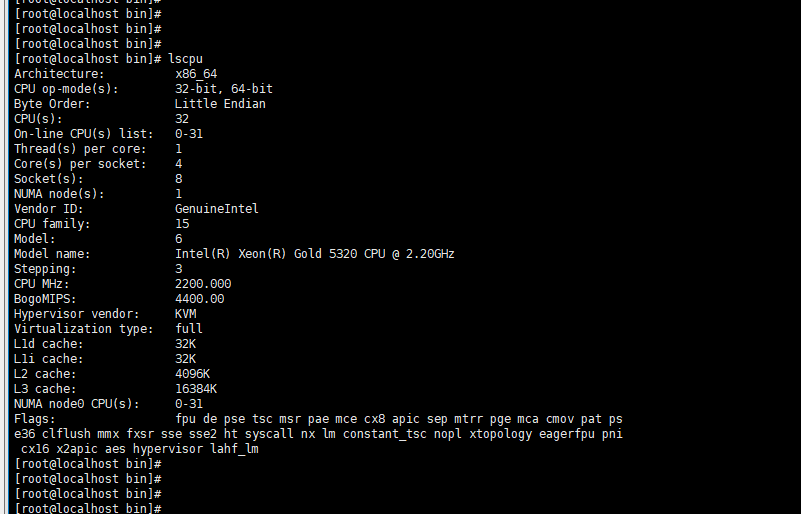
是的,由于没有配置data_dir,默认就在home_path下store目录
好的 我修改下路径进行启动看看,您说的core文件出来,是从哪里看
