

前言
在人工智能快速发展的今天,智能体已经不再是科幻小说中的产物,而是逐步渗透到我们生活和工作的各个方面。从智能助手到自动化决策系统,AI的应用正在改变着我们与技术互动的方式。为了打造高效、个性化的智能体平台,选择合适的技术栈至关重要。
本篇文章将带您走进 Dify 和 OceanBase 的世界,探索如何结合这两者的优势,构建一个专属于您的智能体平台。Dify 作为一款高效的机器学习平台,能够帮助您在复杂数据中提取出有价值的信息,而 OceanBase 则作为一款高可扩展、高性能的分布式数据库,能够为大规模数据存储和实时计算提供强有力的支持。通过 Dify 和 OceanBase 的结合,我们可以为不同业务场景量身定制智能体解决方案,满足多样化的需求。
接下来,我们将深入探讨如何将 Dify 和 OceanBase 融合,打造一个智能体平台,从而赋能您的业务创新,推动行业进步。
一、什么是向量检索文本嵌入(Text Embedding)?
文本嵌入是一种将文本转换为数值向量的技术。这些向量能够捕捉文本的语义信息,使计算机可以"理解"和处理文本的含义。具体来说:
- 文本嵌入将词语或句子映射到高维向量空间中的点。
- 在这个向量空间中,语义相似的文本会被映射到相近的位置。
- 向量通常由数百个数字组成(如 512 维、1024 维等)。
- 可以用数学方法(如余弦相似度)计算向量之间的相似度。
- 常见的文本嵌入模型包括 Word2Vec、BERT、BGE 等。
在开发 RAG 应用时,我们通常需要将文本数据进行嵌入处理转换为向量之后存储在向量数据库中,而其他结构化数据存储在关系型数据库中。OceanBase 4.3.3 版本开始支持将向量作为一种字段类型在关系表中进行存储,使得向量和传统标量数据能够有序、高效地存储在 OceanBase 这一款数据库中。
OceanBase 提供了存储、索引、检索 Embedding 向量数据的能力。具体包括:
| 核心功能 | 描述 |
|---|---|
| 向量数据类型 | 支持最大 16,000 维的 float 向量数据存储。 |
| 向量索引 | 支持精确搜索和近似最近邻搜索。支持 L2 距离、内积和余弦相似度计算。支持 HNSW 索引,索引列最大维度为 2000。 |
| 向量搜索 SQL 运算符 | 支持向量加、减、乘、比较、聚合等基础运算操作符。 |
二、实验架构说明

架构说明:将文档以向量的形式批量存储在 OceanBase 数据库内。用户通过 UI 界面提问,程序使用模型将提问内容嵌入成为向量并在数据库中检索相似向量,得到相似向量对应的文档内容后,应用将它们会同用户提问一起发送给 LLM,LLM 会根据提供的文档生成更加准确的回答。
三、动手实验操作演示
3.1 获取 OceanBase 数据库
- 注册并开通 OBCloud 实例
- 获取数据库实例连接串
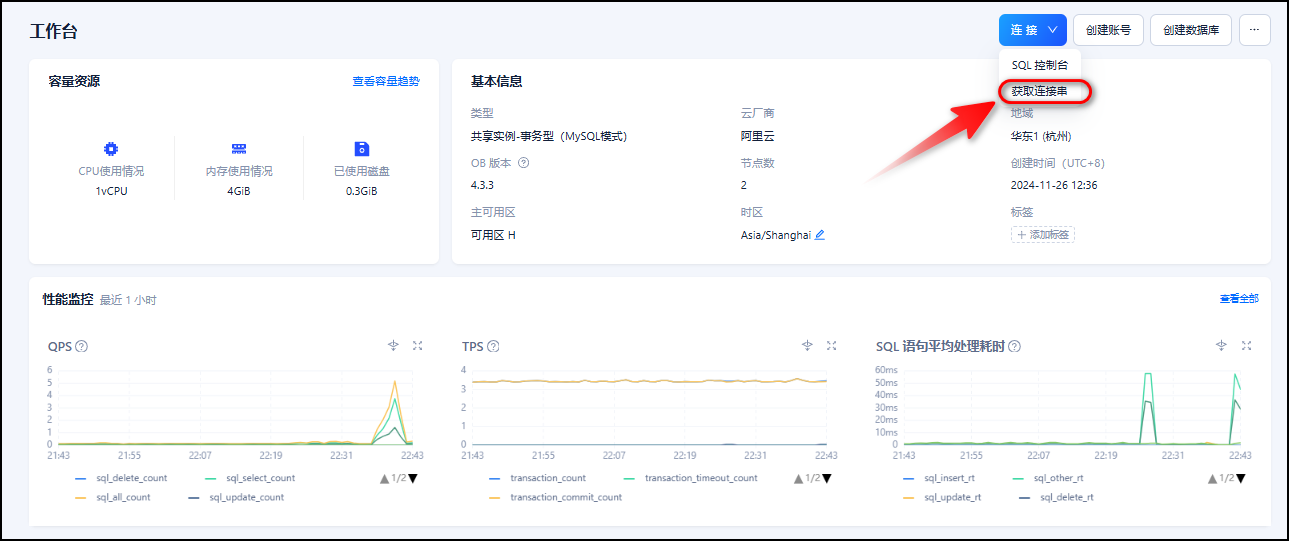
Copy如下连接字符串的代码。

- 创建多个数据库

3.2 克隆Github项目
针对 Dify 的 0.12.1 版本进行了 MySQL 协议兼容的修改,并且上传到了我们 fork 的代码仓库中。大家网络条件好的话推荐克隆 Github 上的版本,否则克隆 Gitee 上的版本。
$ yum install -y git(若没有git,则直接执行该命令安装即可)
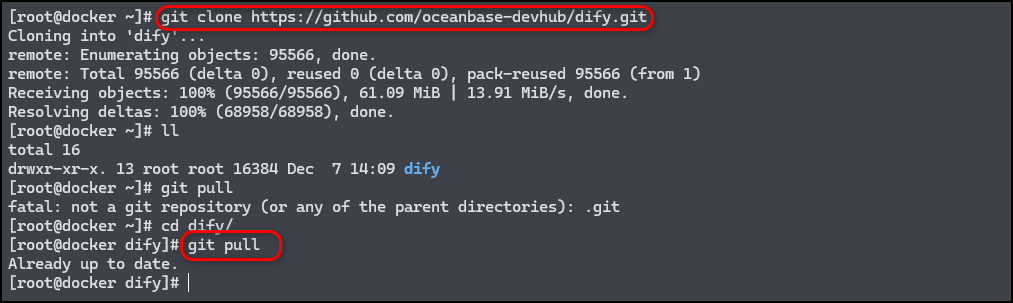
$ git clone https://github.com/oceanbase-devhub/dify.git
或
$ git clone https://gitee.com/oceanbase-devhub/dify.git
PS:为保证 dify 目录的代码是最新的状态,需要执行 git pull 命令,拉取最新的代码。
$ cd dify
$ git pull
3.3 安装并启动Docker服务
$ yum install -y docker
$ systemctl start docker && systemctl enable docker && systemctl status docker
3.4 安装Docker Compose 服务
# To download and install the Docker Compose standalone, run:
$ curl -SL https://github.com/docker/compose/releases/download/v2.30.3/docker-compose-linux-x86_64 -o /usr/local/bin/docker-compose
# Apply executable permissions to the standalone binary in the target path for the installation.
$ chmod +x /usr/local/bin/docker-compose
# docker-compose version
Docker Compose version v2.30.3
3.5 拉取 Docker 镜像
进入到 dify 的工作目录中的docker目录下,执行docker-compose --profile workshop pull
$ cd docker
$ docker-compose --profile workshop pull

3.6 修改环境变量
在docker目录下存放着一个.env.example文件,其中包含了若干 Dify 运行所需的环境变量,我们需要把其中几个重要的配置项填写上。
[root@docker docker]# pwd
/root/dify/docker
[root@docker docker]# cat .env.example
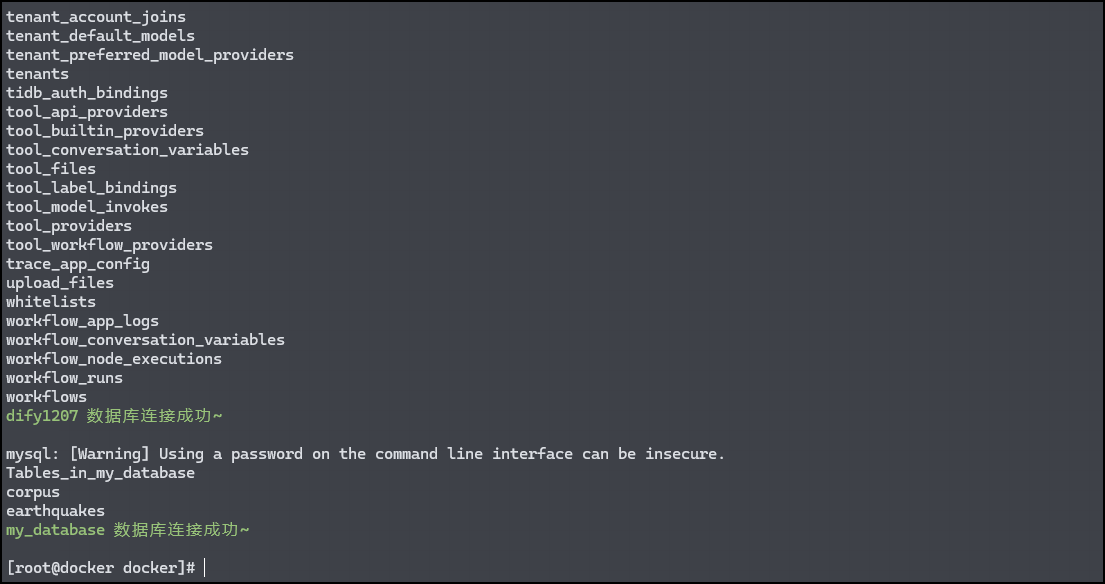
在 docker/scripts 目录下提供了一个脚本 setup-env.sh 用来交互式地获取数据库连接信息,填入 .env 文件中并且完成数据库连接校验。
bash ./scripts/setup-env.sh
按照提示输入数据库连接信息即可,大致形式如下:

如果在检测数据库连接步骤中,两个数据库都连接成功,则说明数据库连接信息填写正确,可以继续进行下一步。
3.7 启动 Dify 容器组
使用下列命令启动 Dify 的容器组
docker-compose --profile workshop up -d

3.8 查看 Dify 后端服务日志
$ docker logs -f docker-api-1
$ docker logs -f docker-worker-1
3.9 访问 Dify 应用
默认情况下,Dify 的前端页面会启动在本机的80端口上,也就是说可以通过访问当前机器的 IP 来访问 Dify 的界面。
① 如果在笔记本上运行的话,则直接在浏览器上访问localhost即可(或者是内网 IP);
② 如果在云服务器上部署 Dify,则需要访问服务器的公网 IP。
初次访问 Dify 应用会进入“设置管理员账户”的页面,设置完成后即可使用该账号登录。
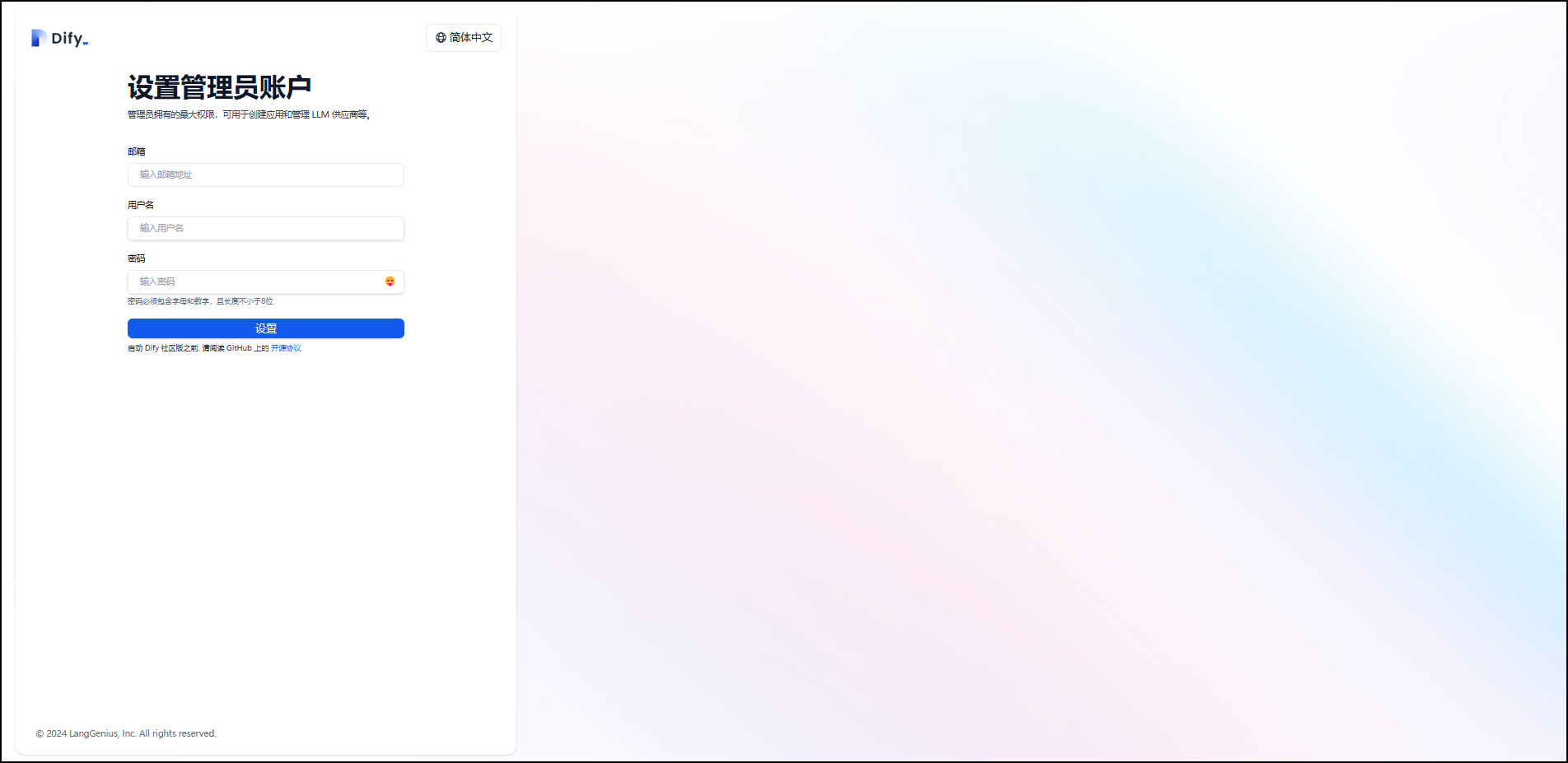
设置完管理员账号后,点击登录。
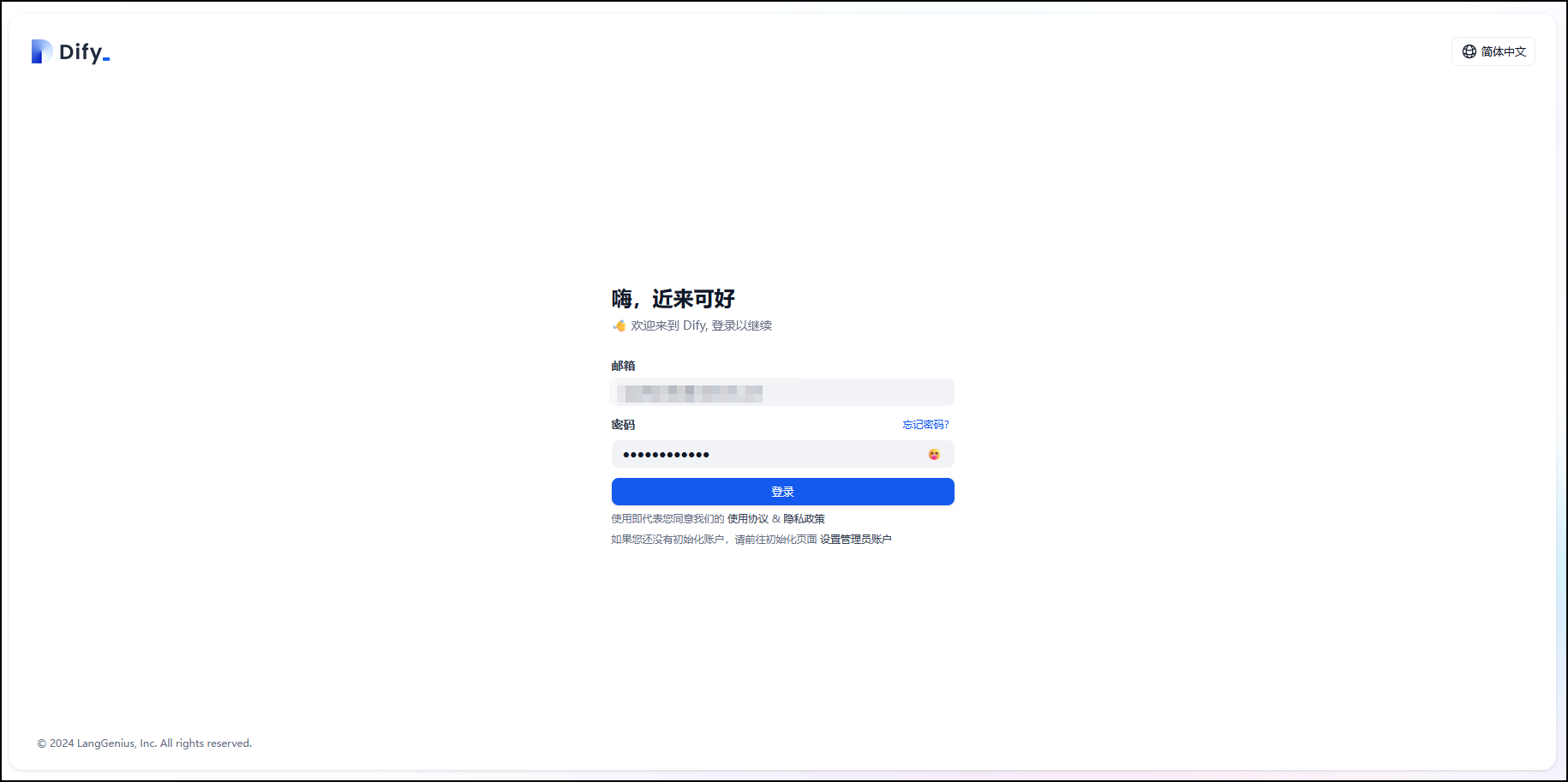
登录至Dify控制台, 完成搭建部署。
3.10 开通阿里云百炼模型调用服务并获取 API KEY
注册链接![]() :https://bailian.console.aliyun.com/
:https://bailian.console.aliyun.com/
注册完阿里云百炼账号后,点击开通服务。
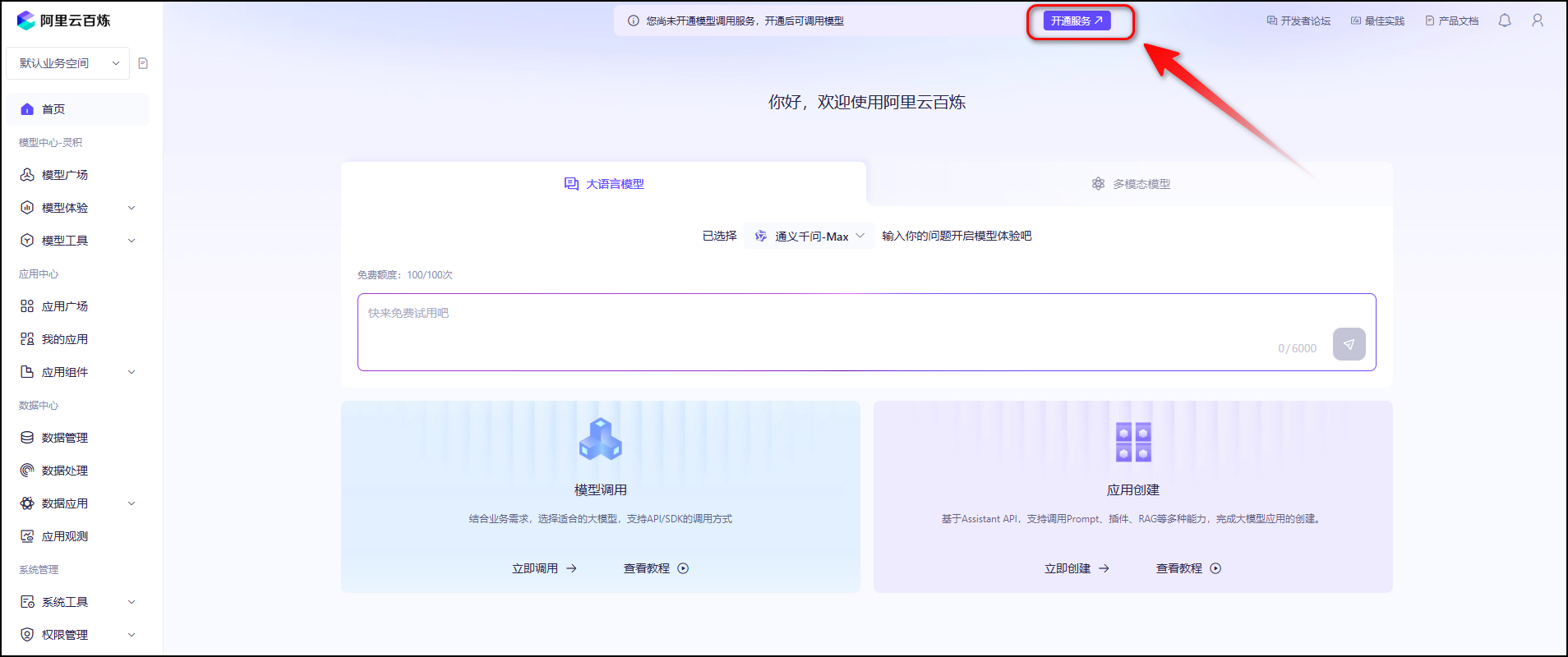
点击我已阅读并同意《模型管理服务协议》
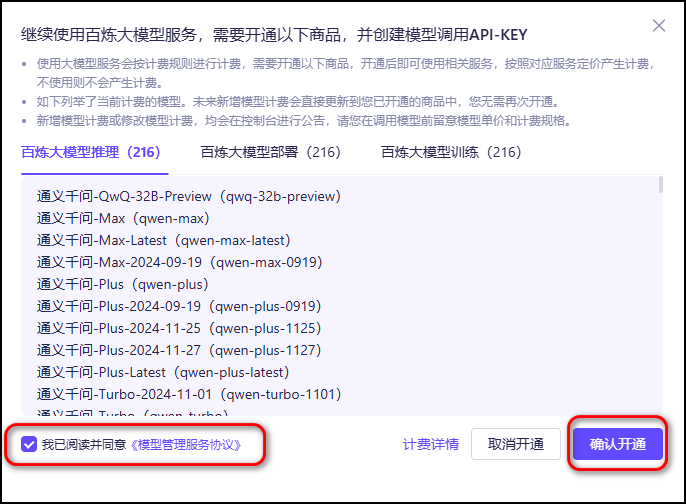
提示开通成功。
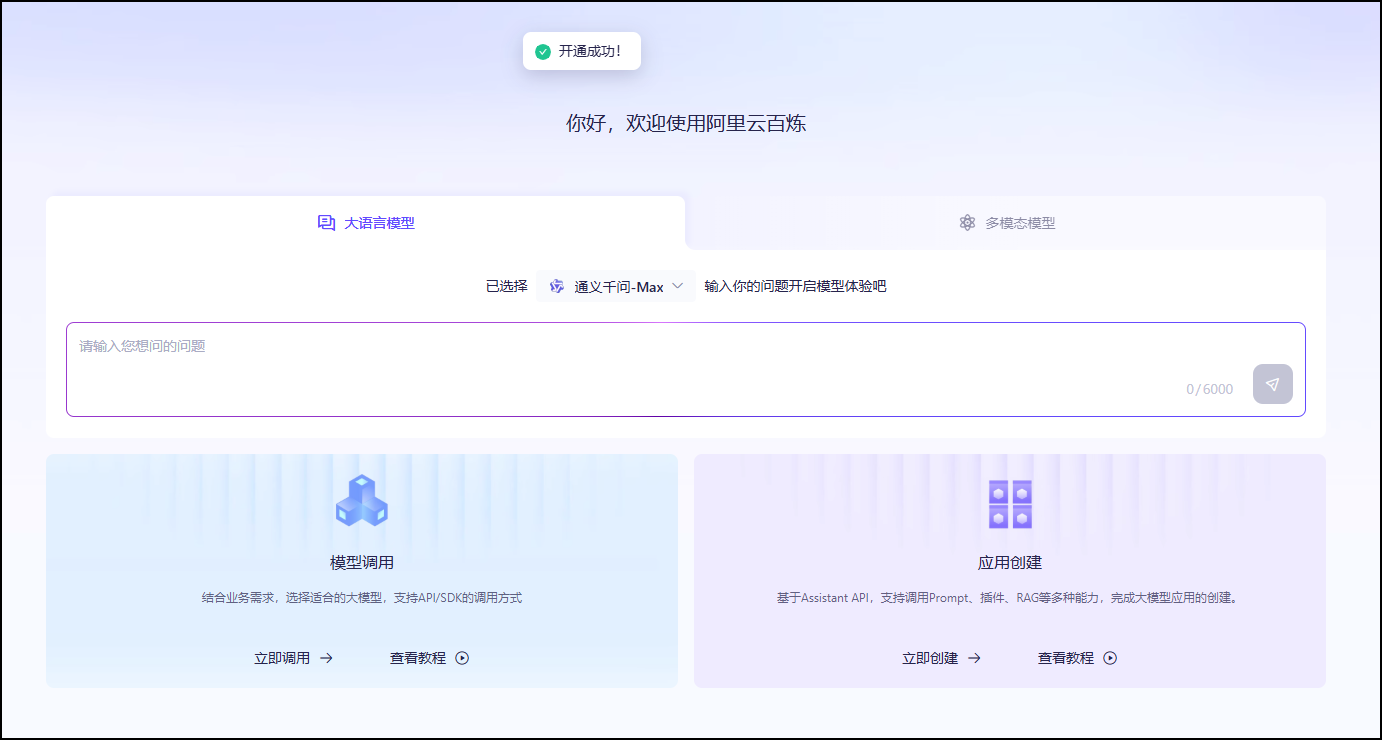
接下来,我们获取API-KEY。

创建API KEY。

记录并保存下来。

3.11 设置模型供应商和系统模型
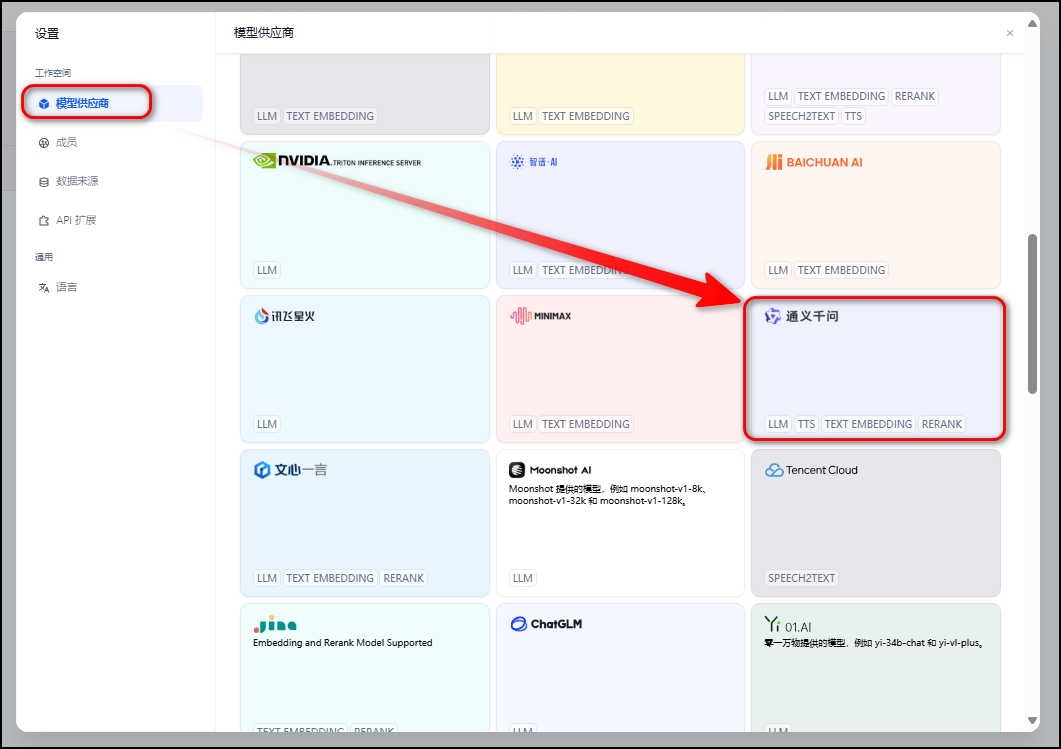
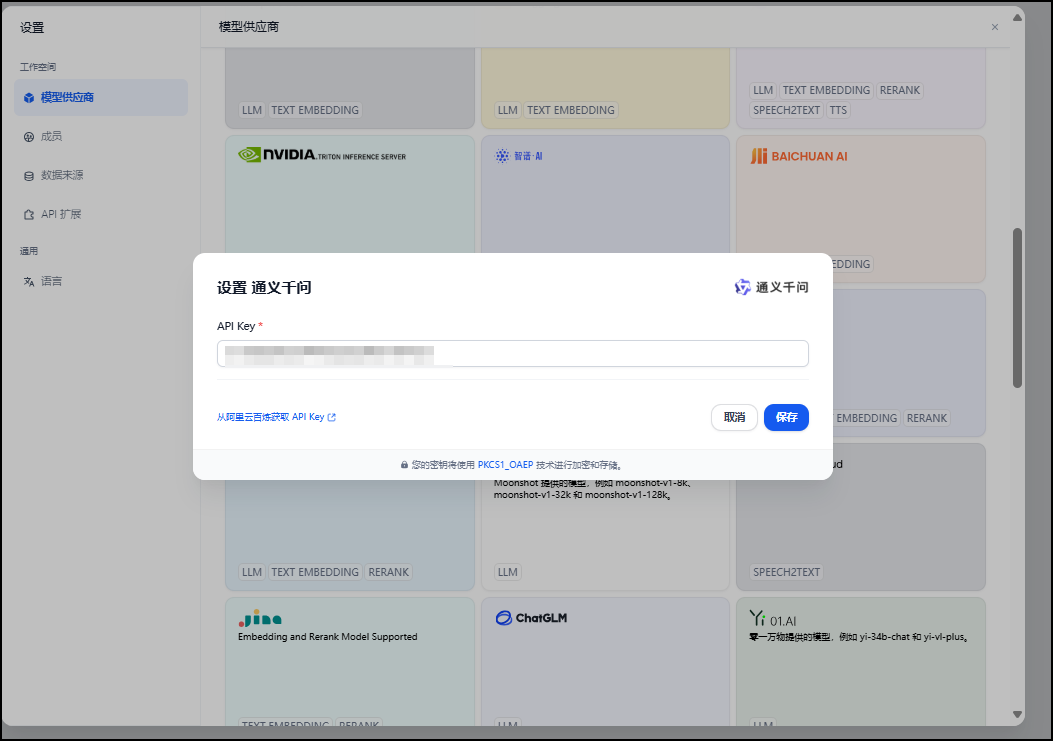
设置完成模型供应商之后刷新网页,再向通义千问模型供应商中添加模型qwen-turbo-2024-11-01,如下图所示。
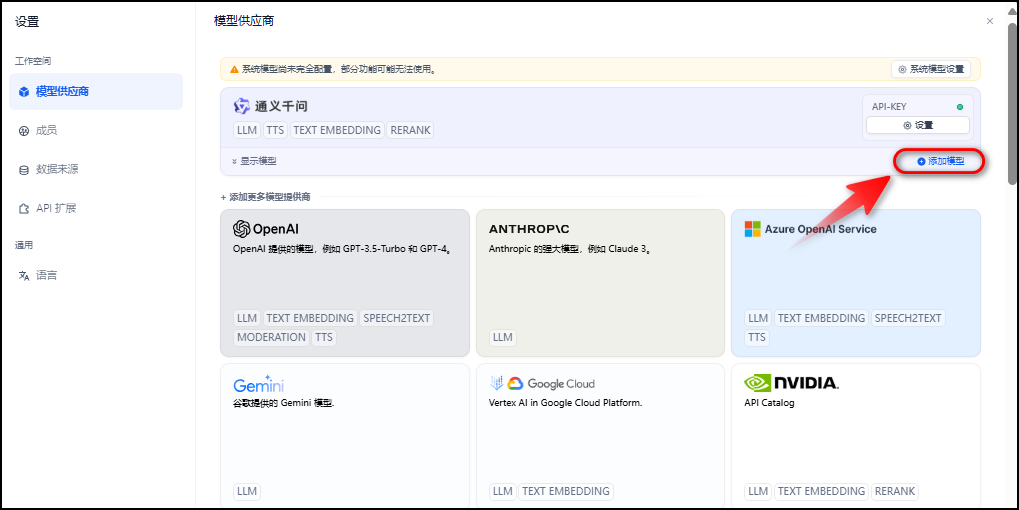
设置完成模型供应商之后刷新网页,再向通义千问模型供应商中添加模型qwen-turbo-2024-11-01
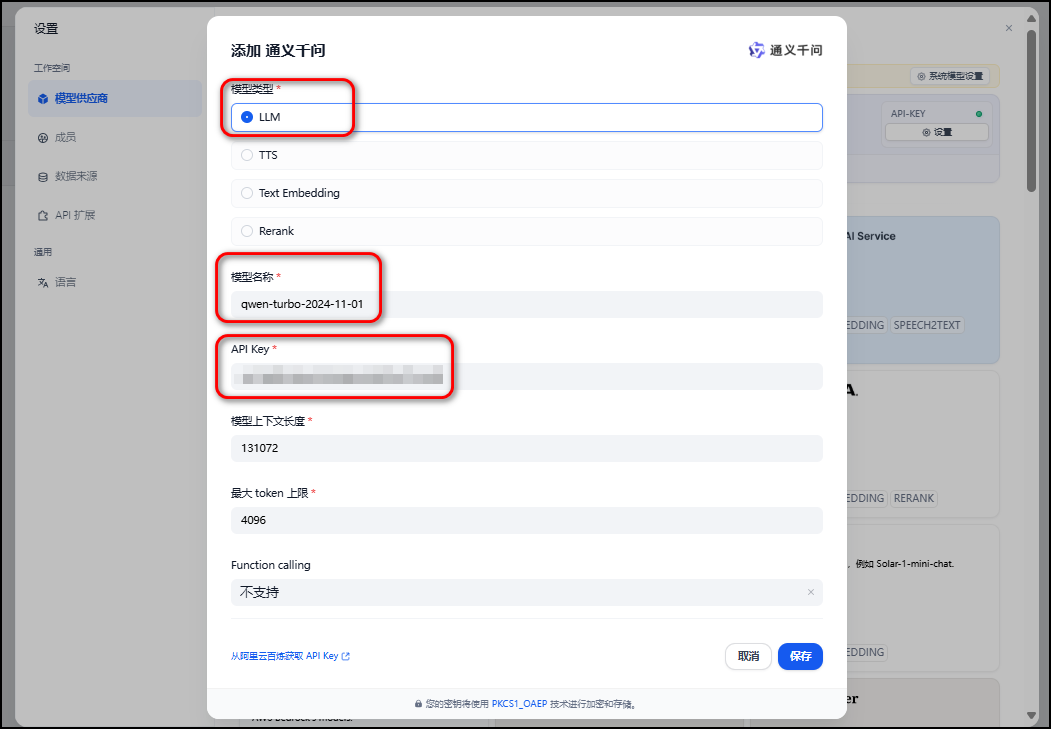
完成系统模型设置,将系统推理模型设置为qwen-turbo-2024-11-01,Embedding 模型设置为text-embedding-v3,最后点击保存。

3.12 创建知识库并上传文档
- 克隆文档仓库
将 OceanBase 数据库的开源文档仓库克隆下来,作为数据来源。
git clone --single-branch --branch V4.3.4 https://github.com/oceanbase/oceanbase-doc.git ~/oceanbase-doc
# 如果您访问 Github 仓库速度较慢,可以使用以下命令克隆 Gitee 的镜像版本
git clone --single-branch --branch V4.3.4 https://gitee.com/oceanbase-devhub/oceanbase-doc.git ~/oceanbase-doc
- 将指定文档上传到知识库中
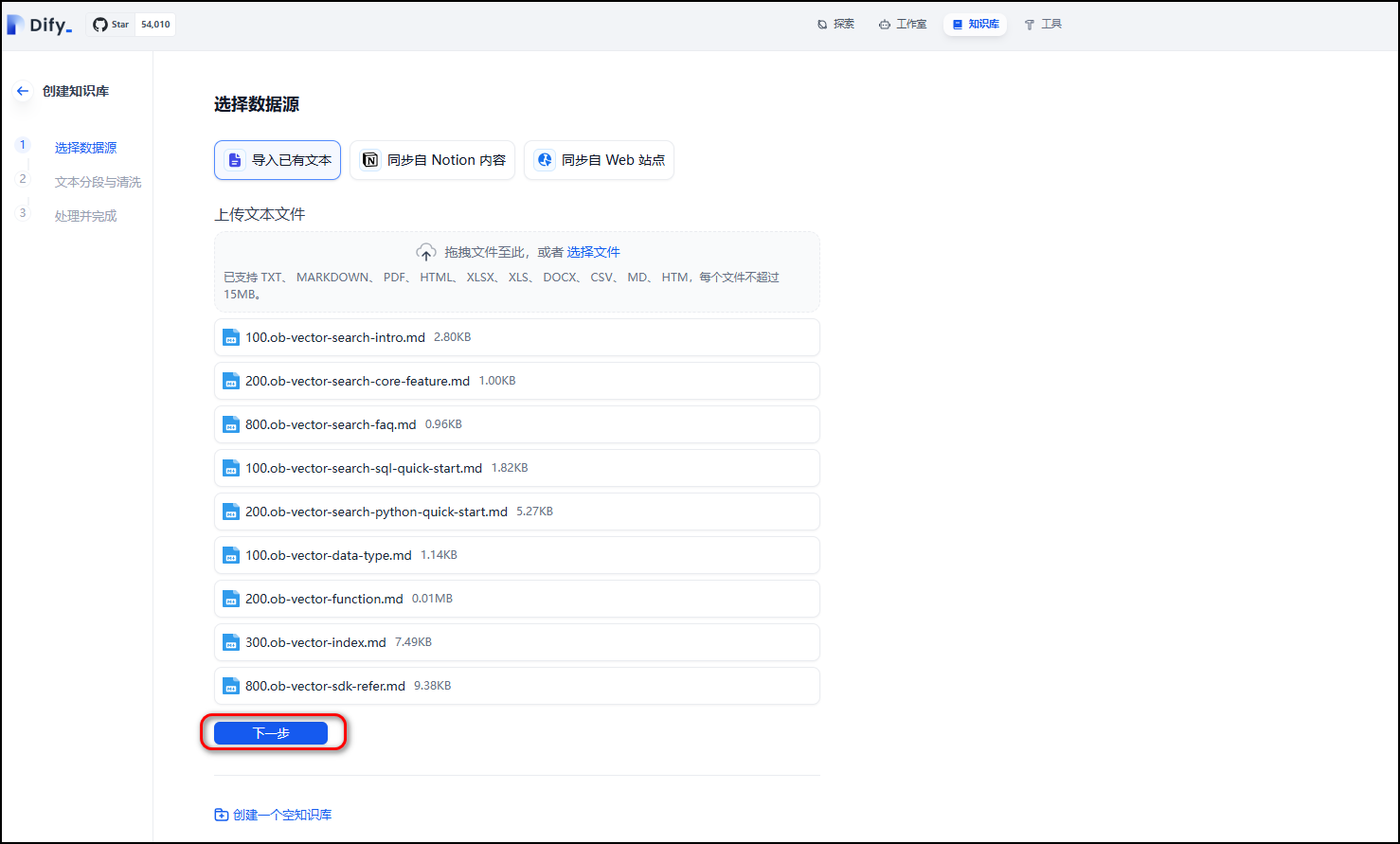
回到首页,顶端中部的“知识库”标签页,进入知识库管理界面,点击创建知识库。

为了节省时间和模型服务调用量,仅处理 OceanBase 向量检索有关的几篇文档,这些文档相对于oceanbase-doc目录的相对路径是zh-CN/640.ob-vector-search,需要将这个目录下面所有的文档都上传。
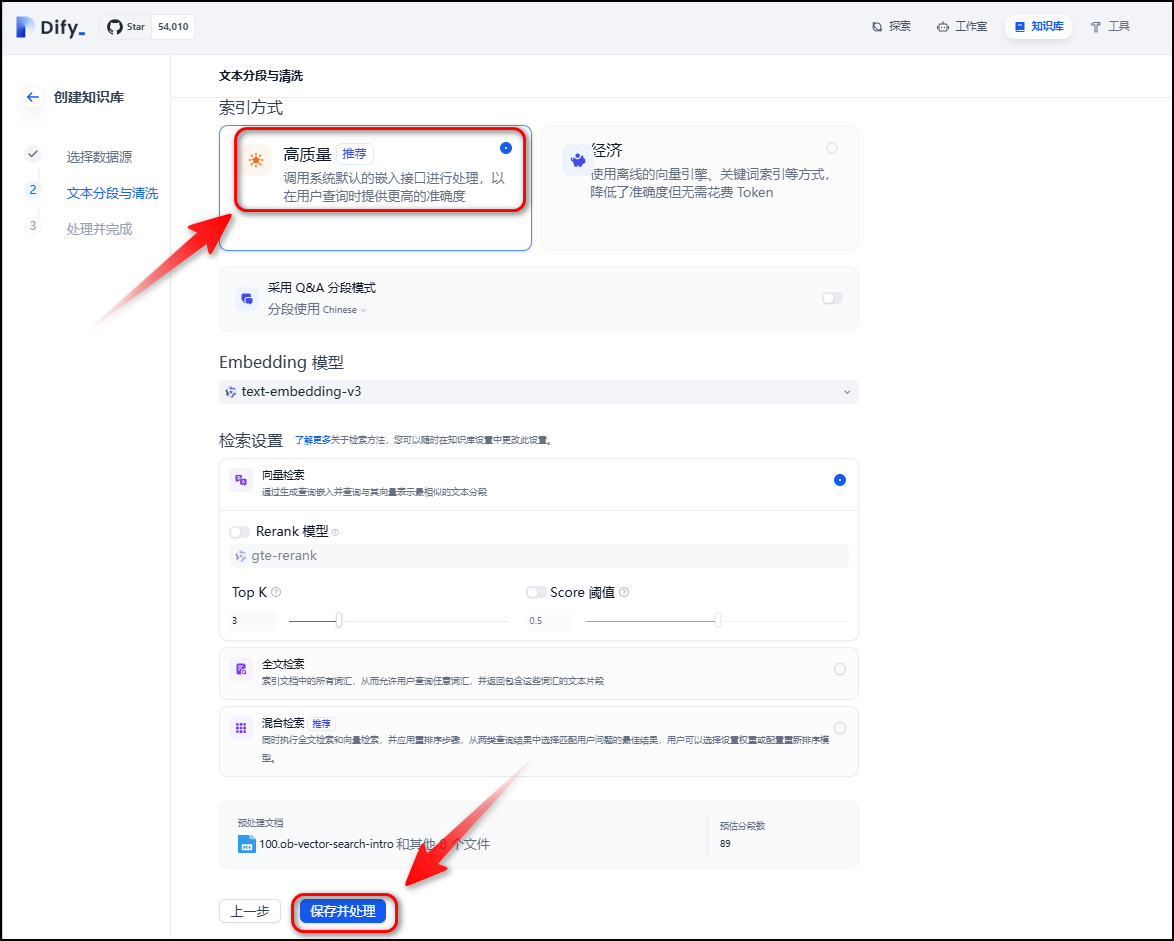
索引方式选择“高质量”,点击“保存并处理”。
Dify 会提示知识库“已创建”,后续可能会看到某些文档已经在此处理完成。点击“前往文档”。
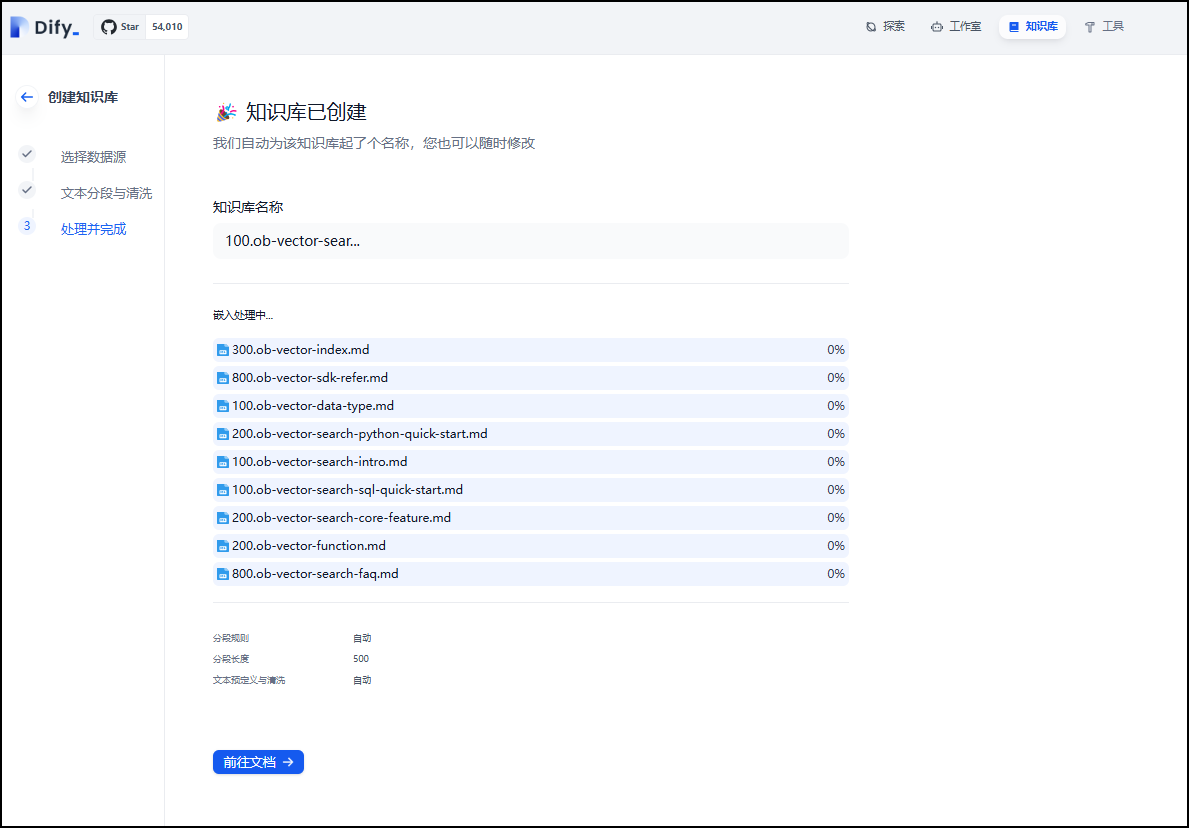
等待数据处理完成。
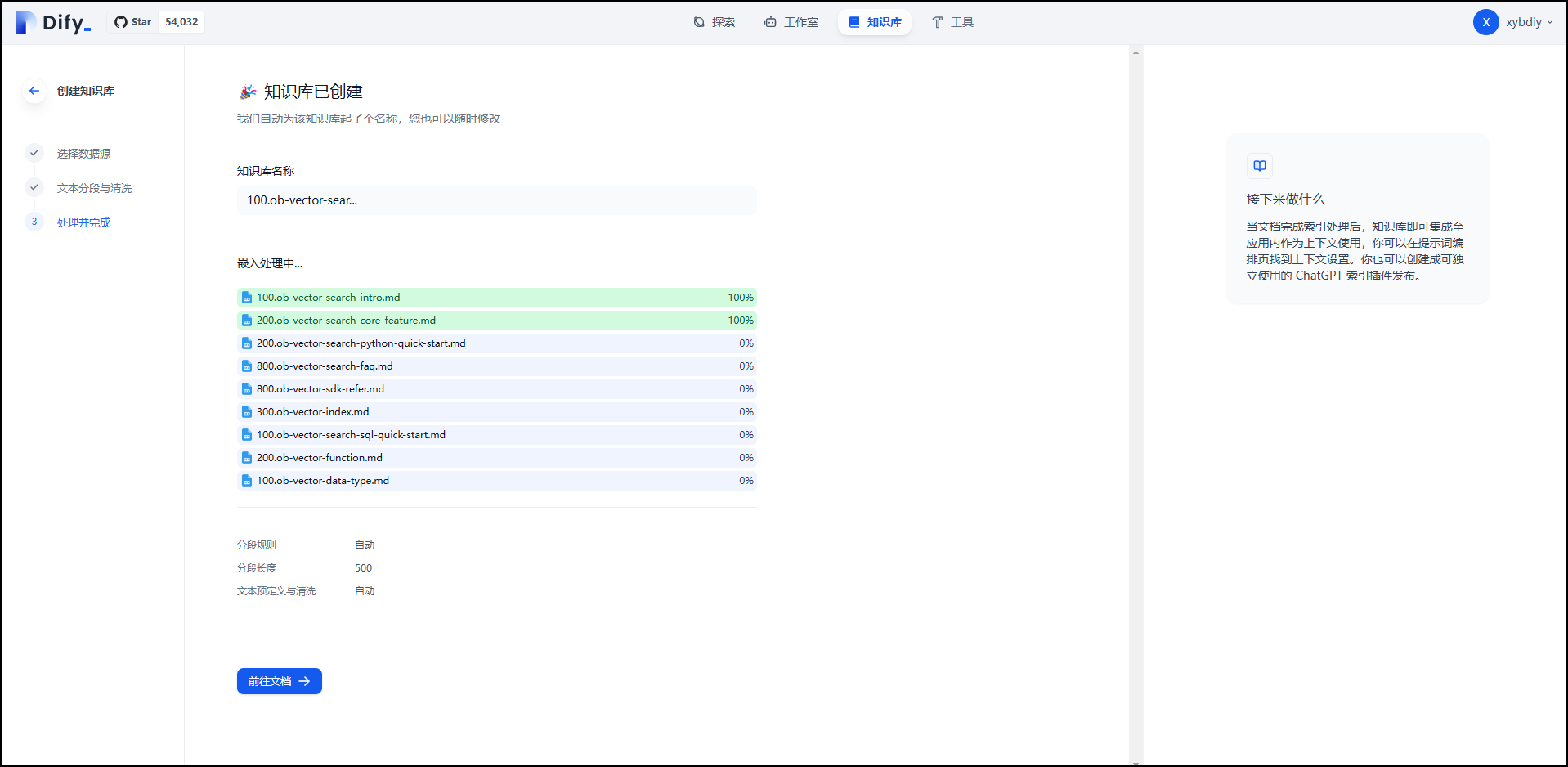
点击“前往文档”后会看到该知识库中的文档列表。
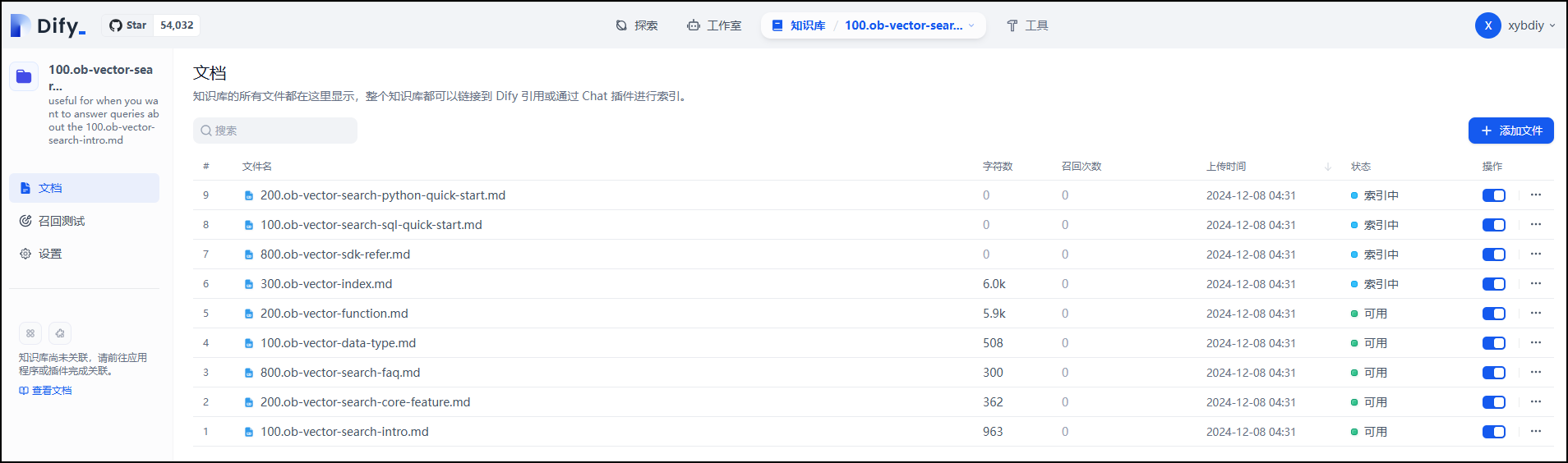
完成。
3.13 创建对话应用并选中知识库
点击“工作室”标签页,进入应用管理界面,点击“创建空白应用”。按照下图指引一步一步操作,创建出应用出来。

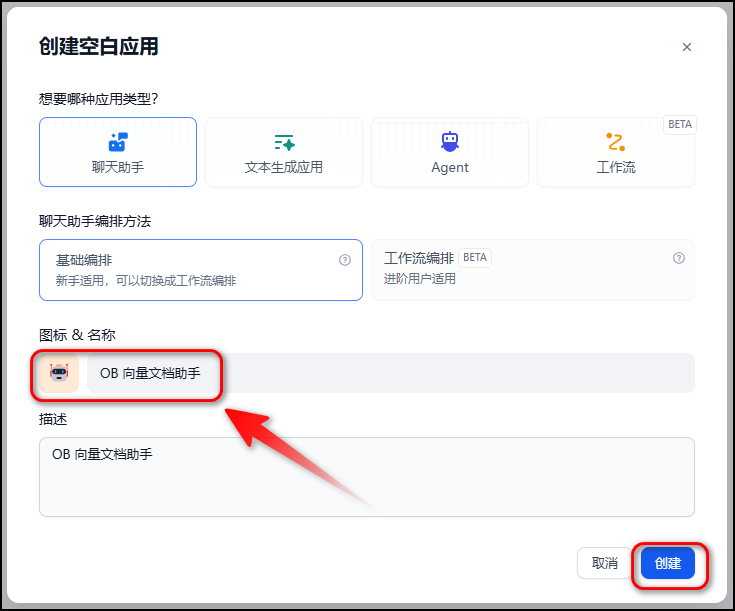
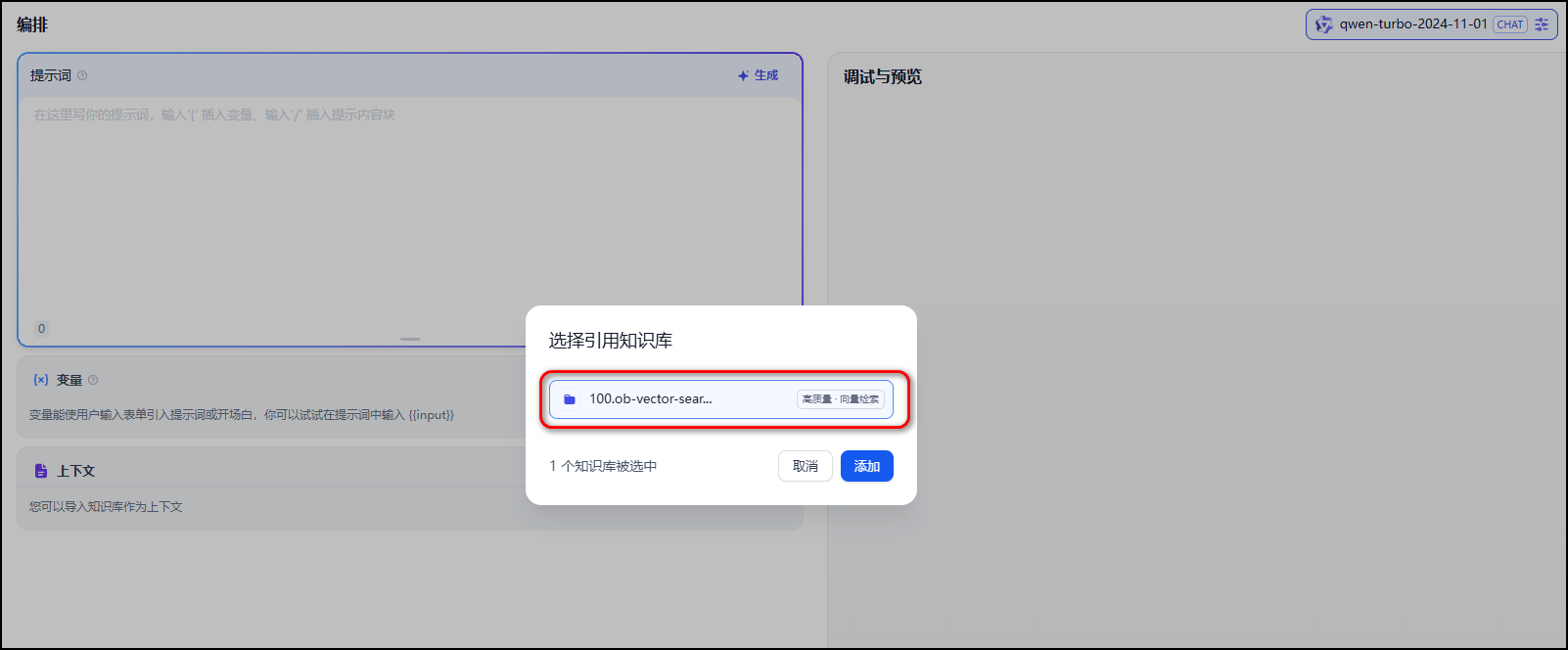
点击“上下文”卡片中的“添加”按钮,选中刚才我们创建的知识库并点击“添加”按钮。

在提示词的输入框中填写如下的提示词:
你是一个专注于回答 OceanBase 社区版问题的机器人。
你的目标是利用可能存在的历史对话和检索到的文档片段,回答用户的问题。
任务描述:根据可能存在的历史对话、用户问题和检索到的文档片段,尝试回答用户问题。如果用户的问题与 OceanBase 无关,则抱歉说明无法回答。如果所有文档都无法解决用户问题,首先考虑用户问题的合理性。如果用户问题不合理,需要进行纠正。如果用户问题合理但找不到相关信息,则表示抱歉并给出基于内在知识的可能解答。如果文档中的信息可以解答用户问题,则根据文档信息严格回答问题。
回答要求:
- 如果所有文档都无法解决用户问题,首先考虑用户问题的合理性。如果用户问题不合理,请回答:“您的问题可能存在误解,实际上据我所知……(提供正确的信息)”。如果用户问题合理但找不到相关信息,请回答:“抱歉,无法从检索到的文档中找到解决此问题的信息。请联系OceanBase的人工答疑以获取更多帮助。基于我的内在知识,可能的解答是……(根据内在知识给出可能解答)”。
- 如果文档中的信息可以解答用户问题,请回答:“根据文档库中的信息,……(严格依据文档信息回答用户问题)”。如果答案可以在某一篇文档中找到,请在回答时直接指出依据的文档名称及段落的标题(不要指出片段标号)。
- 如果某个文档片段中包含代码,请务必引起重视,给用户的回答中尽可能包含代码。请完全参考文档信息回答用户问题,不要编造事实,尤其是数据表名、SQL 语句等关键信息。
- 如果需要综合多个文档中的片段信息,请全面地总结理解后尝试给出全面专业的回答。
- 尽可能分点并且详细地解答用户的问题,回答不宜过短。
可以在右侧聊天框里进行应用调试,例如询问“请介绍一下 OceanBase 的向量功能”。
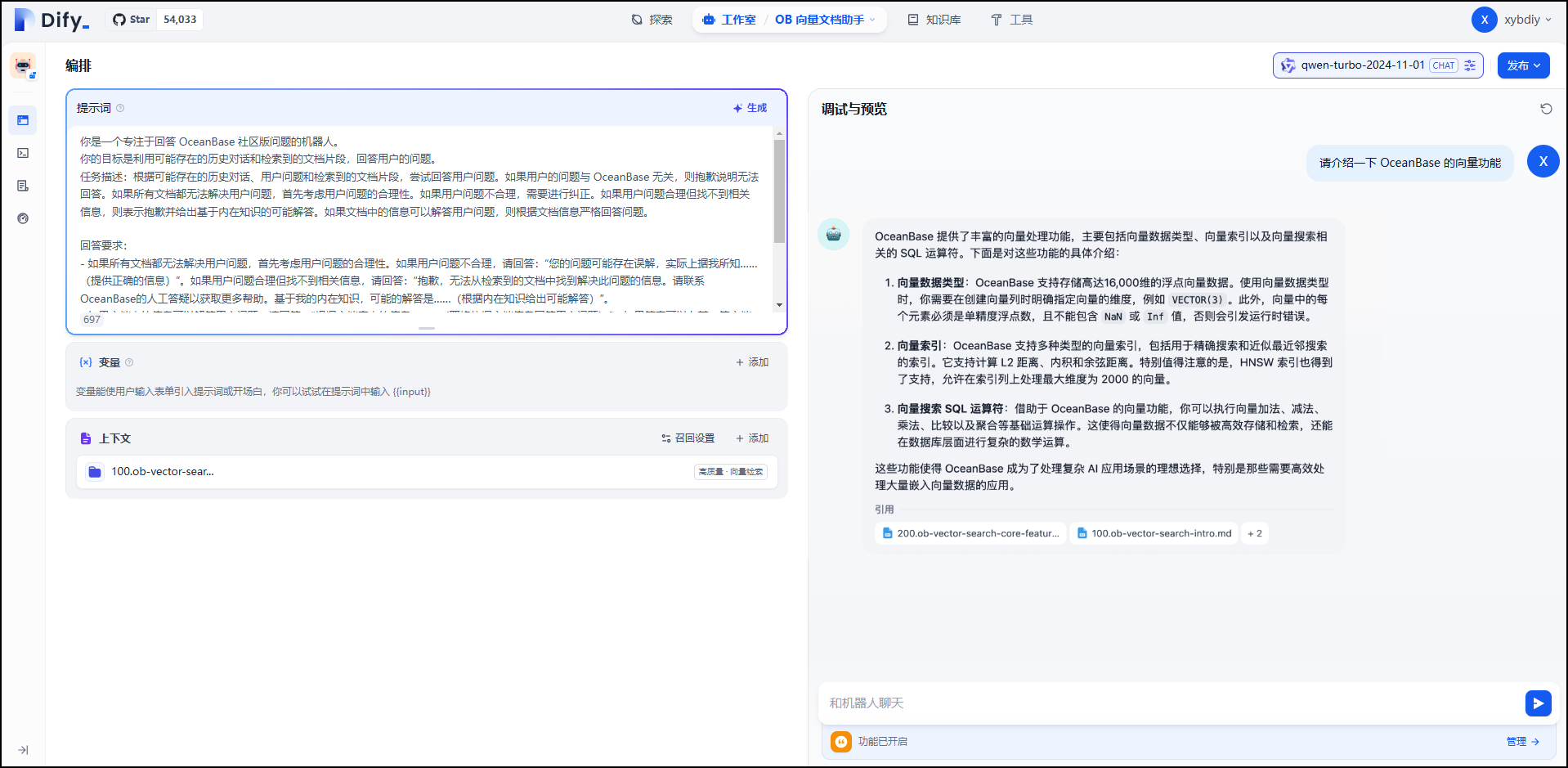
点击应用详情右上角的“发布”下面的“运行”按钮,打开该应用的专属页面。
至此,通过 Dify + OceanBase 搭建属于自己的AI专属伴侣。
四、参考链接
[1] https://docs.docker.com/compose/install/standalone/
[2] docs/dify@oceanbase-workshop.md · oceanbase-devhub/dify - Gitee.com
[3] https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000001790535