

【 使用环境 】生产环境
【 OB or 其他组件 】OB
【 使用版本 】4.2.1-8BP
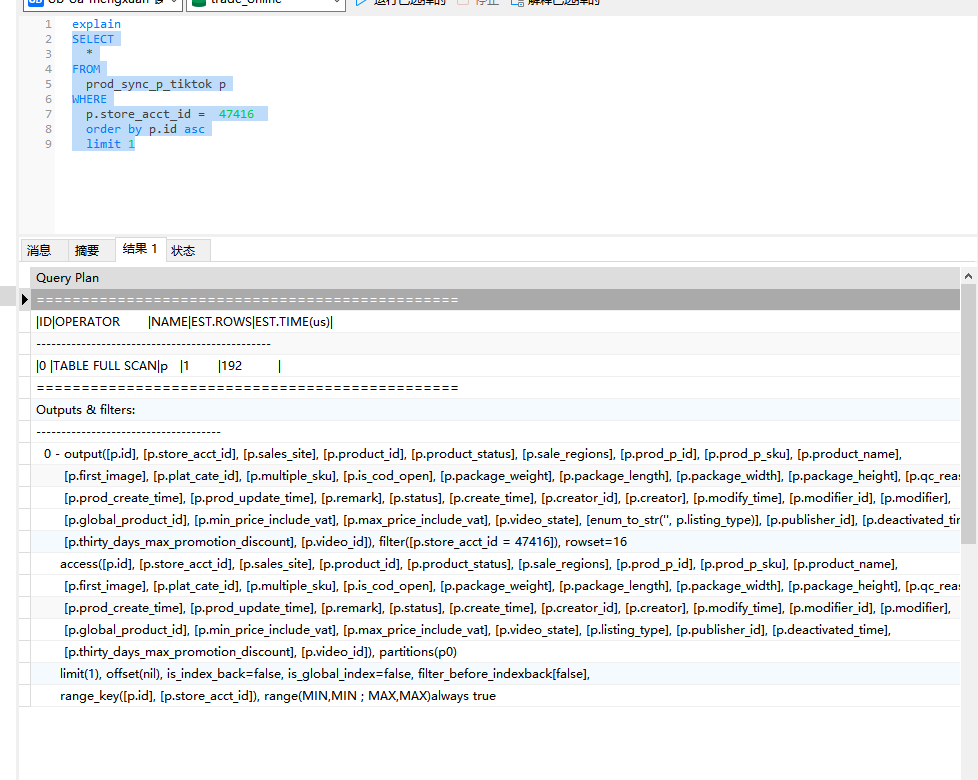
表store_acct_id 字段是有索引的,且该字段能筛选掉99.9%的数据
执行如下sql, 执行器不走索引。
SELECT
*
FROM
prod_sync_p_tiktok p
WHERE
p.store_acct_id = 47416
order by p.id asc
limit 1
表结构发一下呢,都有哪些索引呢
用 诊断工具 obdiag 收集一下gather plan_monitor,里面有排查SQL问题所需要的全部信息,可节省交互的时间。
https://www.oceanbase.com/docs/common-obdiag-cn-1000000001768240
要结合表结构一起看下,select * 肯定会触发回表,回表消耗的代价 比 全表扫描的代价 多 优化器选择了全表扫描 ?
1、表结构发一下
2、详细的explain extended 执行计划发一下 保存在文本里
3、不过确实如楼上所说 没有覆盖索引 select * 会造成回表
···这个表几千万行数据。 回表消耗怎么大过 全表扫。。 最近好多类似的问题。。都在说走索引需要回表消耗大过全表扫, 就不用索引了。。 都不看数据量和索引筛选掉的数据量问题。我升级个 4.2.1-10BP看看还存不存在这个问题吧··· 表结构很简单。估计这个问题随便建个表都能复现。
而且生产上,更注重的是性能稳定性。 即使确实计算出全表加载进内存扫描,有时候比走索引回表快那么1s的。 但是这个性能波动太大。数据分布特殊点, 就可能需要更多时间。 对于业务的感受来说,就是服务怎么突然卡了。。。
而且如果所有类似的有索引不走, 全表扫。 这是不是得加载全表数据进内存作为缓存。 然后淘汰掉其他的查询缓存内容。。 对于整体其他查询来说, 得重新加载表数据到缓存。 这是不是就拖慢了整体的性能了。 如果不想发生这样的事情。 不就得加大机器的内存,同时磁盘还得上pcie接口的高性能磁盘,不然扛不住io压力。 ob就走上了需要高性能机器才能高效运转的集群道路了。
灌个水
你可以看看关于order by配合常量过滤的优化点:
1、当复合索引的最左前缀列为过滤条件的常量过滤时,order by字段配合常量过滤字段满足最左前缀时可以使用复合索引进行排序优化。
2、过滤字段不是复合索引中的常量,但是order by列满足最左前缀是可以使用覆盖索引
3、一些情况不能使用复合索引扫描排序的情况
#一列为升序一列为降序
#order by列引用了一个不在索引中的字段
#无法组合成索引的最左前缀
#存在范围查询
是不能把全部的数据加载的缓存里 但是怎么建立索引避免回表、全表扫或者计划不能选择最优的索引 我们可以在建立的索引的时候 也要有考量