

SELECT COUNT(id) FROM device_coll_param
1 个赞
建议使用obdiag进行一下sql解析分析
SQL性能问题, 此处env中的trace_id对应gv$ob_sql_audit的trace_id
obdiag gather scene run --scene=observer.perf_sql --env “{db_connect=’-hxx -Pxx -uxx -pxx -Dxx’, trace_id=‘xx’}”
trace id获取方法:
1)设置trace信息
SET ob_enable_show_trace=‘ON’;
2)执行sql。
3)获取上个命令的trace
select last_trace_id();
1 个赞
每次插入完数据是否做过合并?
1 个赞
可能有几个问题;
1、缺乏统计信息
2、读放大
3、执行计划异常
1 个赞
不明觉厉!支持!
1 个赞
看下执行计划呢,有没有走上索引
如何做合并
单表8亿数据量,这种查询SQL一般预期多少时间能响应 数据库配置32C64G 3台集群 SELECT llj_cumulative_flow, DATE_FORMAT(dcp.coll_time, ‘%Y-%m-%d %H:%i:%s’) AS coll_time FROM device_coll_param dcp WHERE 1=1
AND dcp.coll_key = ‘393_1’ AND dcp.coll_time BETWEEN ‘2024-11-10 16:11’ AND ‘2024-11-13 18:23’ ORDER BY coll_time
建议使用obdiag进行一下sql分析,将分析报告发出来看一下
帮忙看下 什么原因
看obdiag拿回来的报告中实际的执行计划走了索引coll_time,并且有大量的回表数据。但实际返回行数却只有1000行
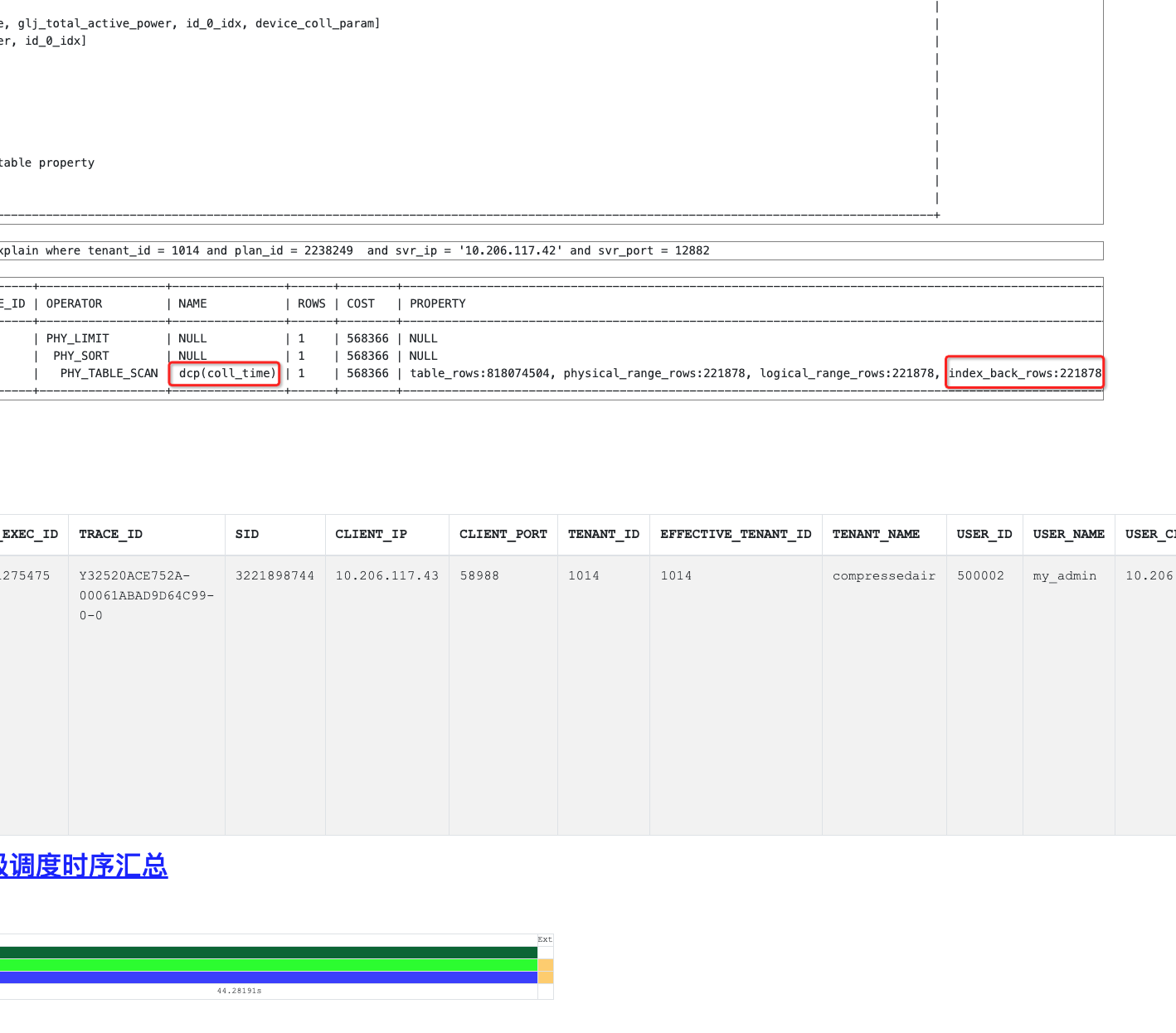
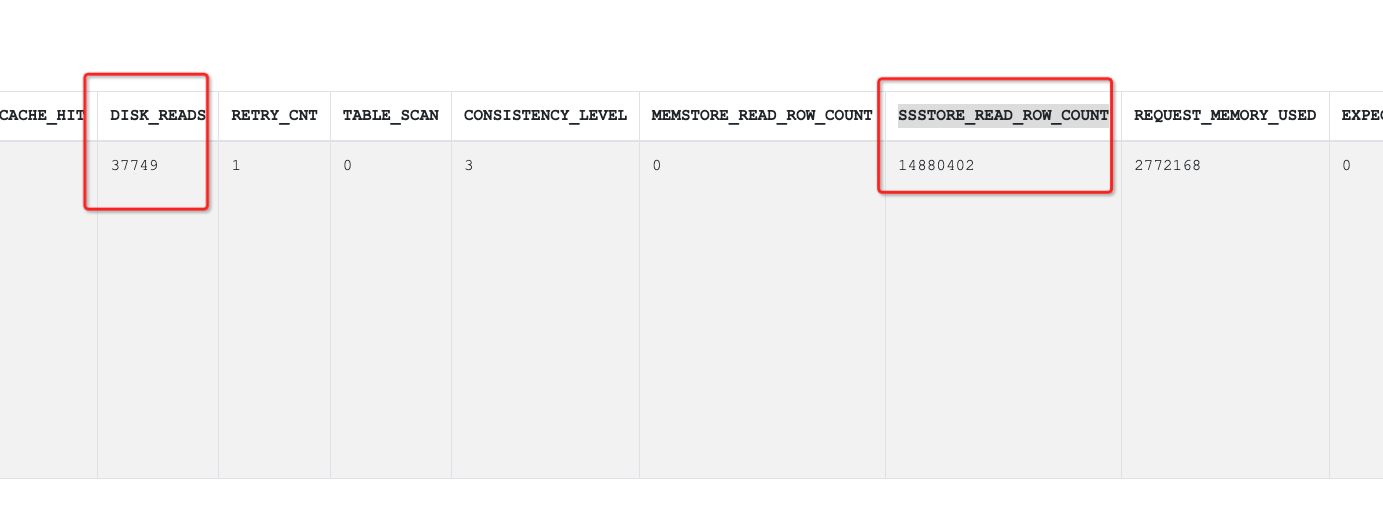
在看sql_audit中的数据,有大量的物理读和SSSTORE_READ_ROW_COUNT,这个是走磁盘,比较耗费时间的。
最后再看你的表结构里面的索引

结合你的查询语句,可以做的优化有两种方式:
方式一:试试直接通过hint指定走coll_key索引,走等值查询过滤;(推荐)
方式二:试试增加一个组合索引,coll_key, coll_time,然后绑定这个索引试试
SELECT llj_cumulative_flow, DATE_FORMAT(dcp.coll_time, ‘%Y-%m-%d %H:%i:%s’) AS coll_time FROM device_coll_param dcp USE INDEX (coll_key, coll_time) WHERE
dcp.coll_key = ‘393_1’ AND dcp.coll_time BETWEEN ‘2024-11-10 16:11’ AND ‘2024-11-13 18:23’ ORDER BY coll_time 这样查询吗?也比较慢
hint指定走coll_key索引试试,把上面USE INDEX (coll_key, coll_time) 方式的执行计划发出来看看
USE INDEX (coll_key, coll_time) USE INDEX (coll_key)都只走了coll_key索引, 我尝试增加一个组合索引试试,但这个过程会比较慢
