森先木易
2024 年12 月 5 日 16:52
#1
【 使用环境 】生产环境
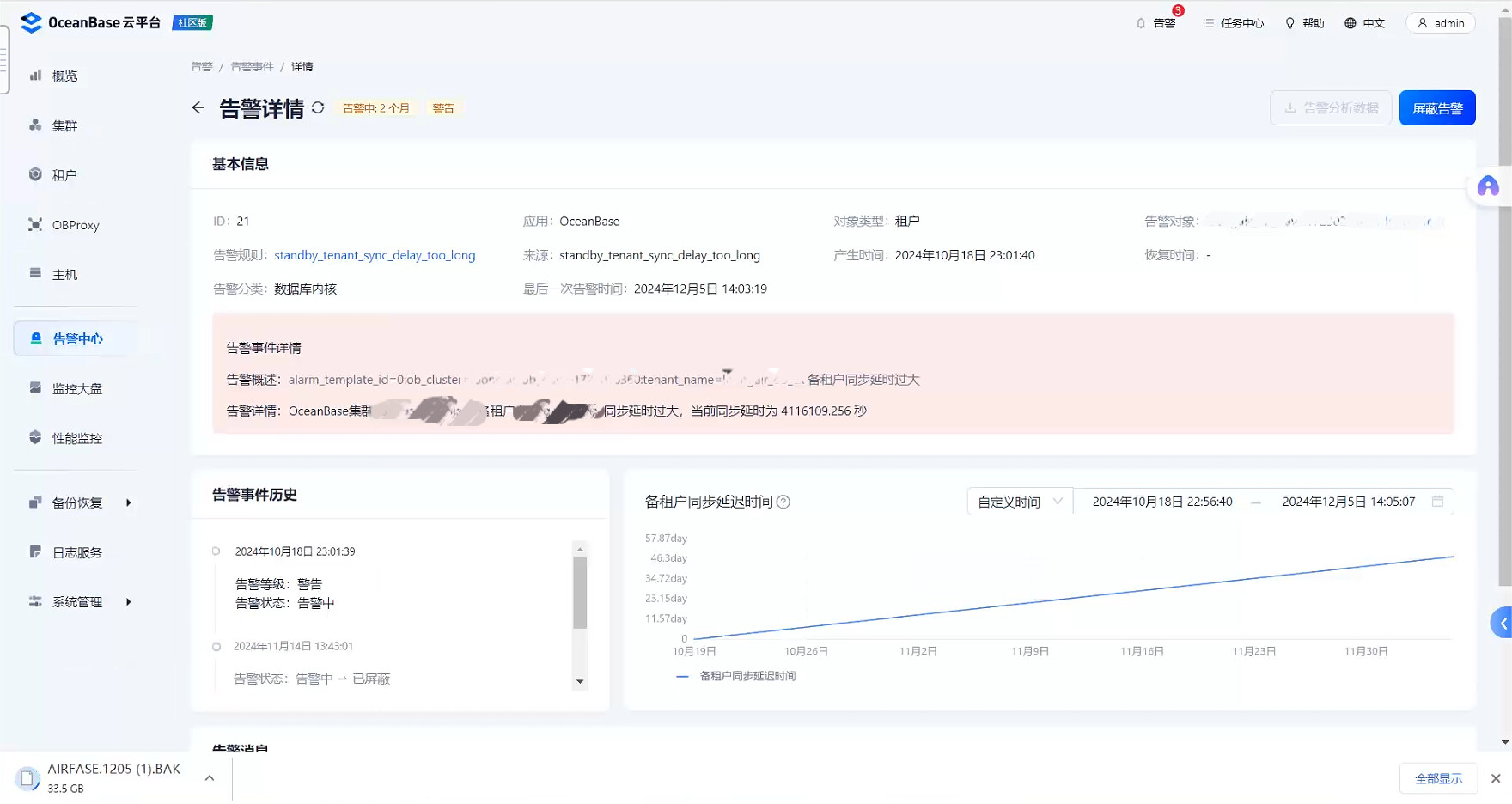
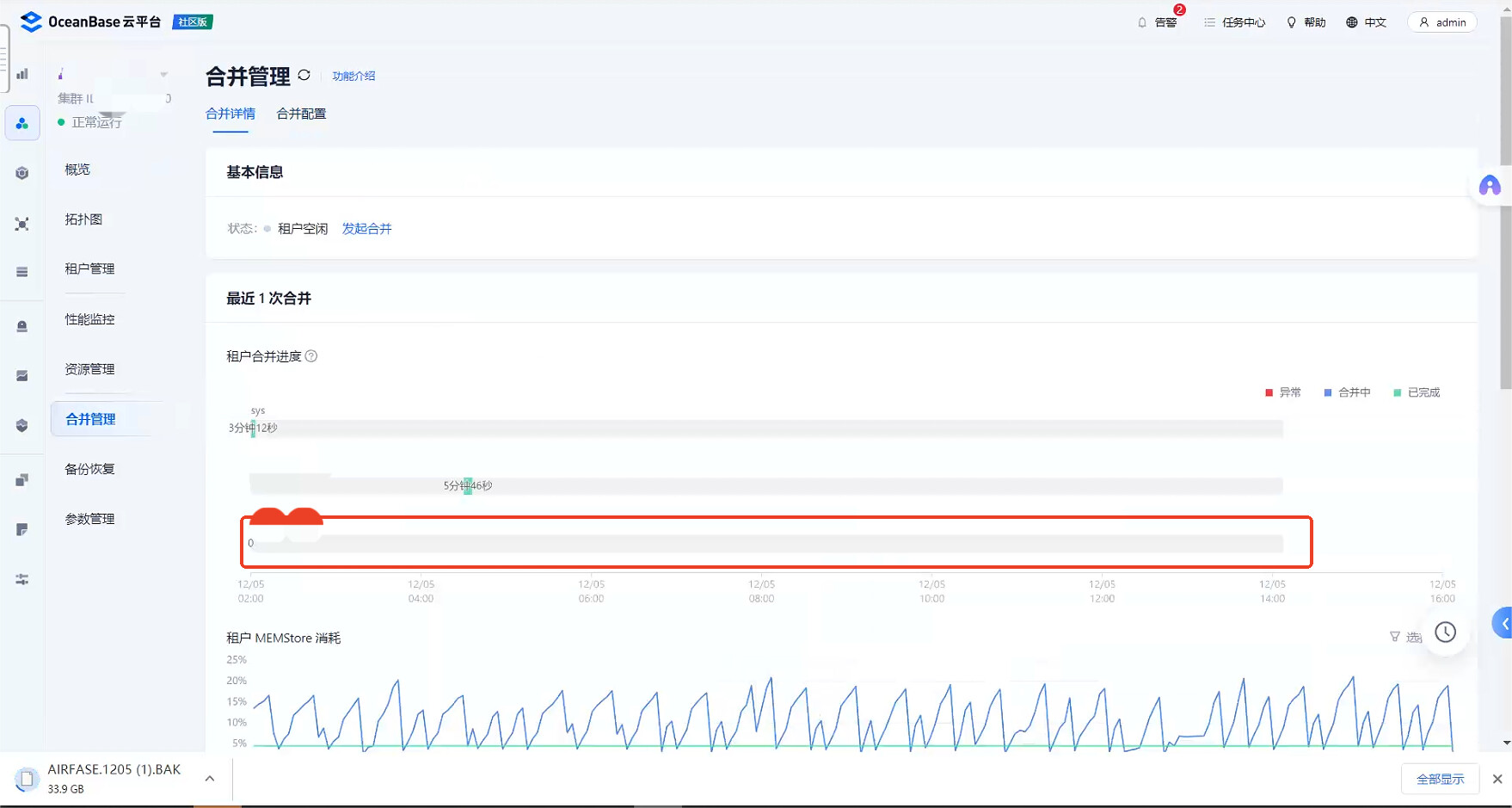
怀疑是因为备租户冻结异常导致的同步延迟,所以查询了下合并状态。
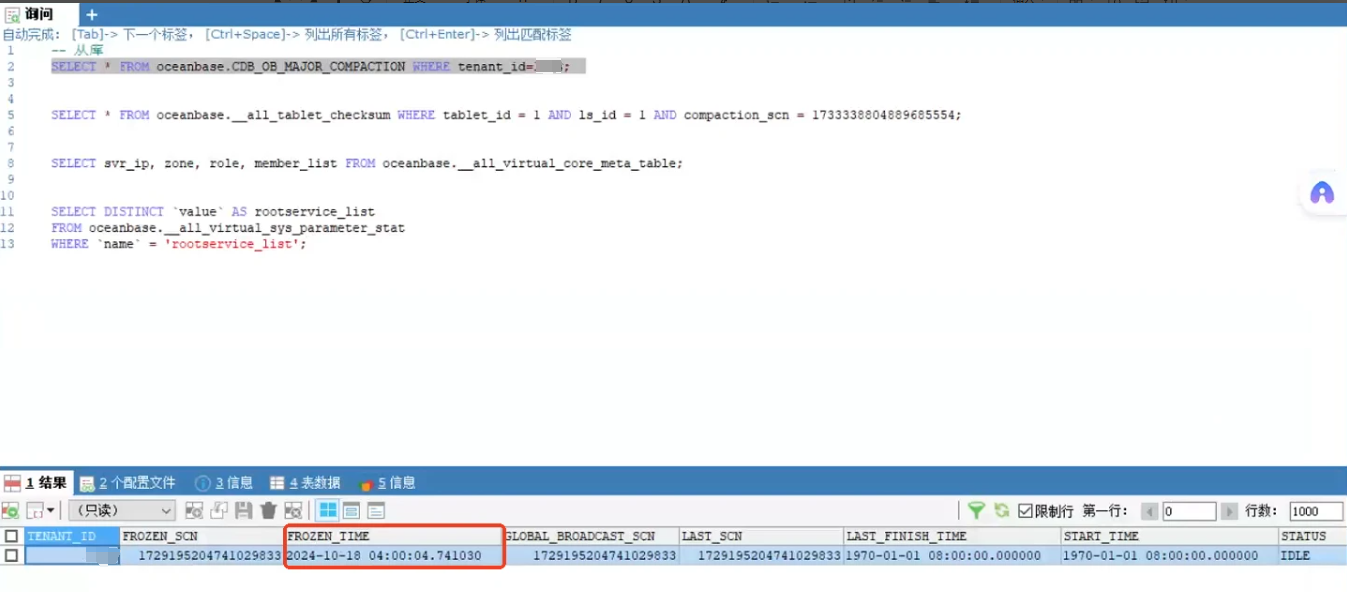
可以看到出现告警的备租户,是没有合并记录的,黑屏查询呢,它的最近一次合并发起的时间 是10 月18号,这个不正常。
https://ask.oceanbase.com/t/topic/35605619
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手 ] 即可召唤小助手,欢迎试用!
3 个赞
论坛小助手
2024 年12 月 5 日 16:53
#3
根据您提供的信息和文档库中的信息,备租户延迟过大的问题可能与以下几个方面有关:
合并状态 :
您提到的备租户没有合并记录,这可能是导致同步延迟的原因之一。根据文档片段1,从V4.0.X版本开始,合并将采用统一合并策略,即租户的所有Zone同时开始执行合并,且所有Zone均完成合并后,才表示该租户完成合并。如果备租户没有合并记录,可能意味着它从未启动过合并,或者合并过程中出现了问题。
您可以通过以下步骤检查和处理合并问题:
日志恢复源 :
根据文档片段4,备租户通过日志恢复源来拉取上游的日志。如果日志恢复源为空或被损坏,会导致备租户卡住。您可以检查以下几点:
确认日志恢复源是否正确配置:SHOW PARAMETERS LIKE 'log_archive_dest';
检查主租户的状态和日志流状态是否匹配:SELECT * FROM oceanbase.__all_tenant WHERE tenant_name = '<主租户名称>';
SELECT * FROM oceanbase.__all_log_archive_status WHERE tenant_id = <主租户ID>;
如果发现日志恢复源有问题,可以重新配置日志恢复源:ALTER SYSTEM SET log_archive_dest='LOCATION=<归档目录>' FOR TENANT <备租户名称>;
租户长时间未发起冻结 :
其他可能的原因 :
网络问题 :检查主租户和备租户之间的网络连接是否正常。
资源不足 :检查备租户的CPU、内存等资源是否充足,是否存在资源瓶颈。
配置问题 :检查备租户的配置参数是否合理,特别是与日志恢复和合并相关的参数。
综上所述,建议您按照上述步骤逐一排查和处理,以解决备租户延迟过大的问题。如果问题仍然存在,建议联系OceanBase的技术支持团队获取进一步的帮助。
更多信息请查看:
手动控制合并 OceanBase Sysbench 高性能部署和问题分析 4000 ~ 4499 物理备库同步过程中卡住 租户请求队列积压 监控告警 4500 ~ 4999 9000 ~ 9499
4 个赞
森先木易
2024 年12 月 5 日 16:56
#4
问题处理需求:
2 个赞
靖顺
2024 年12 月 5 日 16:59
#5
2 个赞
淇铭
2024 年12 月 5 日 16:59
#6
持续有延迟
查看备租户是否有同步延迟
明确备租户同步延迟较大的LS
SELECT MIN(SYNC_SCN) FROM CDB_OB_LS WHERE TENANT_ID=10XX;
3 个赞
淇铭
2024 年12 月 5 日 17:02
#7
你发了两个帖子 统一在这个帖子回复你 按照上面的排查步骤 排查一下
【 使用环境 】生产环境
【 OB or 其他组件 】 OBserver
【 使用版本 】 4.2.1.7
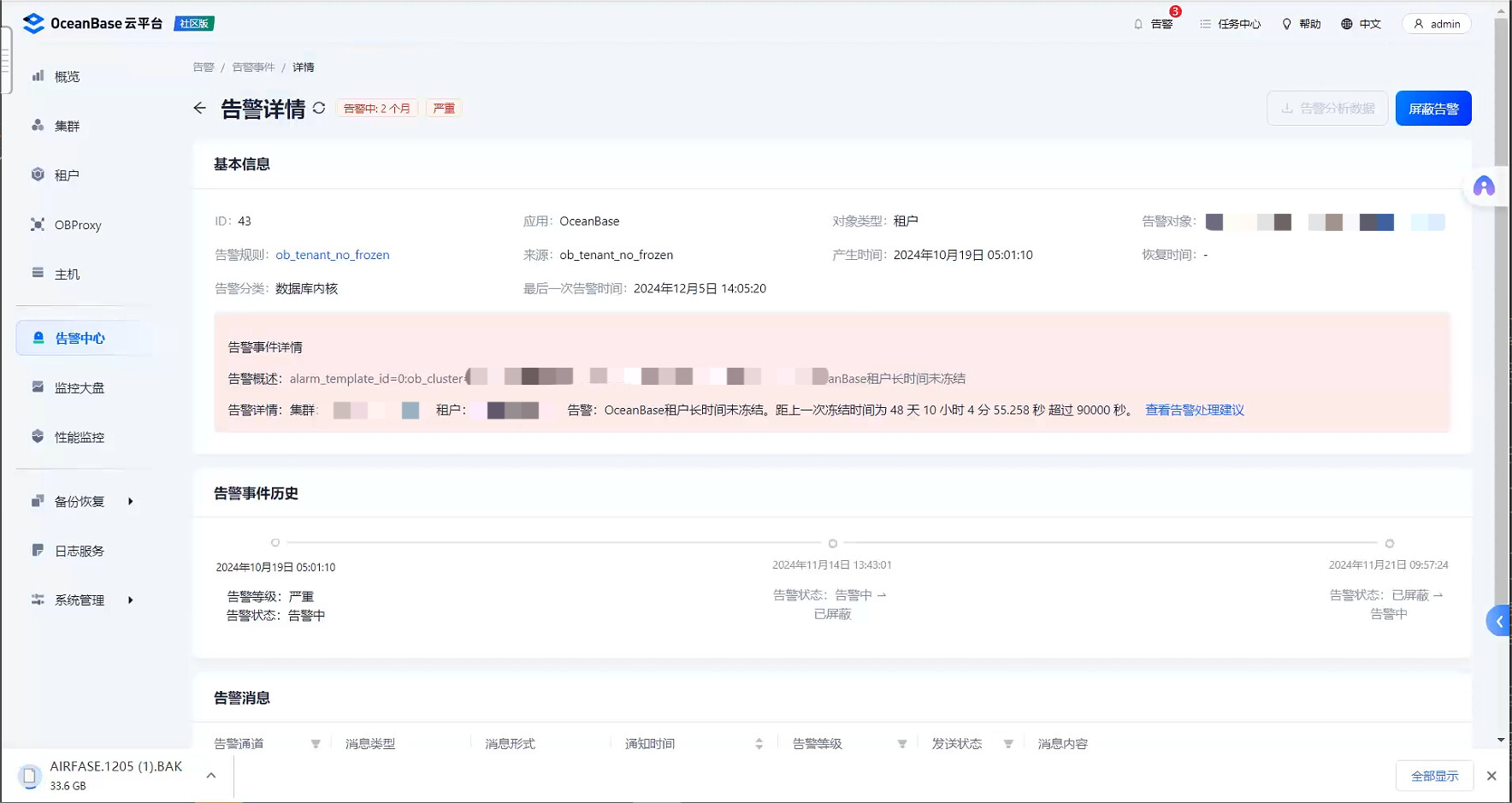
【问题描述】OCP告警中心发现有二个长时间的活跃告警,一个是备租户同步延迟过大,一个是租户长时间未发起冻结。
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
告警事件:
【SOP系…
2 个赞
论坛小助手
2024 年12 月 5 日 17:04
#8
根据您提供的信息和文档库中的内容,我们可以从以下几个方面分析告警原因并给出相应的解决方案:
合并状态异常 :
您提到的备租户没有合并记录,这可能是导致同步延迟的主要原因之一。根据文档片段4,备租户通过日志恢复源来拉取上游的日志。如果备租户没有合并记录,可能意味着它从未启动过合并,或者合并过程中出现了问题。
检查合并状态 :SELECT * FROM oceanbase.__all_tenant_major_freeze_info WHERE tenant_id = <备租户ID>;
检查日志恢复源 :SHOW PARAMETERS LIKE 'log_archive_dest';
检查主租户的状态和日志流状态 :SELECT * FROM oceanbase.__all_tenant WHERE tenant_name = '<主租户名称>';
SELECT * FROM oceanbase.__all_log_archive_status WHERE tenant_id = <主租户ID>;
网络问题 :
检查主租户和备租户之间的网络连接是否正常。可以使用网络工具(如ping、traceroute)来检查网络连通性和延迟。
资源不足 :
检查备租户的CPU、内存等资源是否充足,是否存在资源瓶颈。可以使用OCP或其他监控工具来查看资源使用情况。
检查和修复合并状态 :
检查和配置日志恢复源 :
优化网络连接 :
使用网络工具检查主租户和备租户之间的网络连接,确保网络连通性和低延迟。
增加资源 :
如果备租户的资源不足,可以增加CPU、内存等资源,确保备租户有足够的资源进行同步。
检查和完成上一轮合并 :
调整合并触发时间 :
检查配置参数 :
检查租户的其他配置参数,确保它们合理且不会影响合并过程。
通过以上分析和解决方案,您可以逐步排查和解决备租户同步延迟过大和租户长时间未发起冻结的问题。如果问题仍然存在,建议联系OceanBase的技术支持团队获取进一步的帮助。
更多信息请查看:
手动控制合并 OceanBase Sysbench 高性能部署和问题分析 4000 ~ 4499 物理备库同步过程中卡住 租户请求队列积压 监控告警 4500 ~ 4999 9000 ~ 9499
具体信息可参考以下文档:
分析诊断&决策流程 监控告警 数据库应急概述 Agent 升级检查
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
2 个赞
森先木易
2024 年12 月 5 日 17:46
#10
1.查看备租户是否有同步延迟
from DBA_OB_TENANTS
where TENANT_TYPE=‘USER’ and TENANT_ID=100x
2.明确备租户同步延迟较大的LS
select SCN_TO_TIMESTAMP(min(end_scn)),current_timestamp(6), ls_id, svr_ip,svr_port
from GV$OB_LOG_STAT
where TENANT_ID=100X and role=‘LEADER’;
SELECT MIN(SYNC_SCN) FROM CDB_OB_LS WHERE TENANT_ID=10XX;
在主租户查看对应日志流的归档状态
a. 在主租户的sql 客户端上执行如下查询,查看租户归档是否正常
SELECT * FROM V$OB_ARCHIVE_DEST_STATUS WHERE TENANT_ID = 10XX;
b. 在主租户的sql 客户端上执行如下查询,查看租户日志流归档是否正常
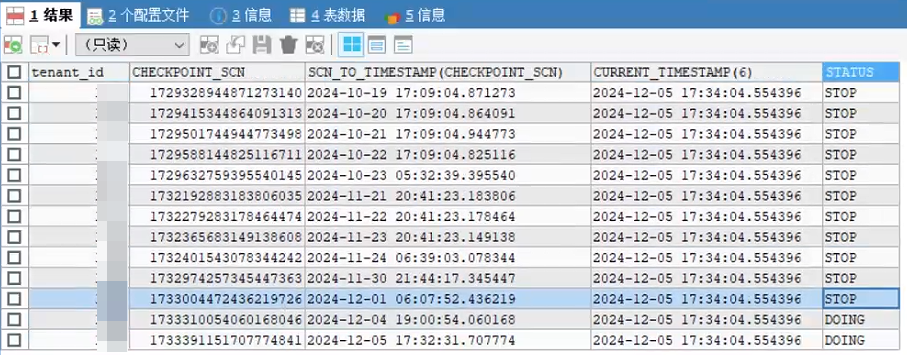
select tenant_id,CHECKPOINT_SCN,SCN_TO_TIMESTAMP(CHECKPOINT_SCN), current_timestamp(6),STATUS
from CDB_OB_LS_LOG_ARCHIVE_PROGRESS
where LS_ID=10XX and TENANT_ID = 10XX;
是否主备租户规格不同导致恢复日志慢,在步骤2中找到最落后日志所在observer,查看恢复日志线程日志
grep T100X_RFL observer.log
a. 有如下日志打印 “clog disk is not enough, just wait”,表明clog盘满无法提交日志
这个我就没查了,因为集群中还有另一个备租户的合并都是正常的。
2 个赞
淇铭
2024 年12 月 6 日 10:31
#12
你的主备租户什么时候搭建的? select * from DBA_OB_TENANTS;
2 个赞
森先木易
2024 年12 月 6 日 11:16
#13
这种重搭备租户理论上是可以恢复的吧。这个备租户并非我搭建的,不确定是不是从搭建初就有这个问题;登录客户远程环境有点麻烦,看下能不能一次多取些信息呢。
1 个赞
淇铭
2024 年12 月 6 日 13:45
#14
好的 我统一发给你
2 个赞
森先木易
2024 年12 月 6 日 16:01
#15
obinfo.txt (236.5 KB)
1 个赞
淇铭
2024 年12 月 6 日 17:22
#16
看着时间是10.18号创建的备租户 从查询的同步延迟的信息看 一直都没有做同步呀 位点一直没有往前推 是不是当时配置的有问题呀
1 个赞
淇铭
2024 年12 月 6 日 17:36
#17
淇铭:
SCN_TO_TIMESTAMP
备租户上查询一下这些信息https://www.oceanbase.com/knowledge-base/oceanbase-database-1000000000832367?back=kb
1 个赞
森先木易
2024 年12 月 9 日 10:30
#18
关于这些信息,请查看附件:obinfo1obinfo1.txt (3.5 KB)
关于备租户配置是否有问题,这个存疑,这个正常的备租户也是一样配置创建的。
我现在想了解下这个解决方案:
1、重启集群是否有效,因为还有一个租户是正常的,我不确定当前集群重启能不能起来,起来后能不能恢复;
1 个赞
淇铭
2024 年12 月 9 日 11:24
#20
你在排查一下 这个问题
在备租户对应日志流的 leader 所在 OBServer上,查询 remote fetch log 模块是否工作正常。
grep T100X_RFL observer.log
1 个赞
淇铭
2024 年12 月 9 日 16:13
#21
你好 10.18号创建的备租户 没有位点推进信息 当时没有ocp没有告警么?时间比较长了 clog日志也应该覆盖了 建议是删除备租户 重新搭建备租户 在进行主备租户同步
1 个赞
森先木易
2024 年12 月 9 日 17:33
#22
当前日志里看到就是这个。
1 个赞