【 使用环境 】生产环境
【 OB or 其他组件 】
【 使用版本 】
社区版本4.3.4
【问题描述】清晰明确描述问题
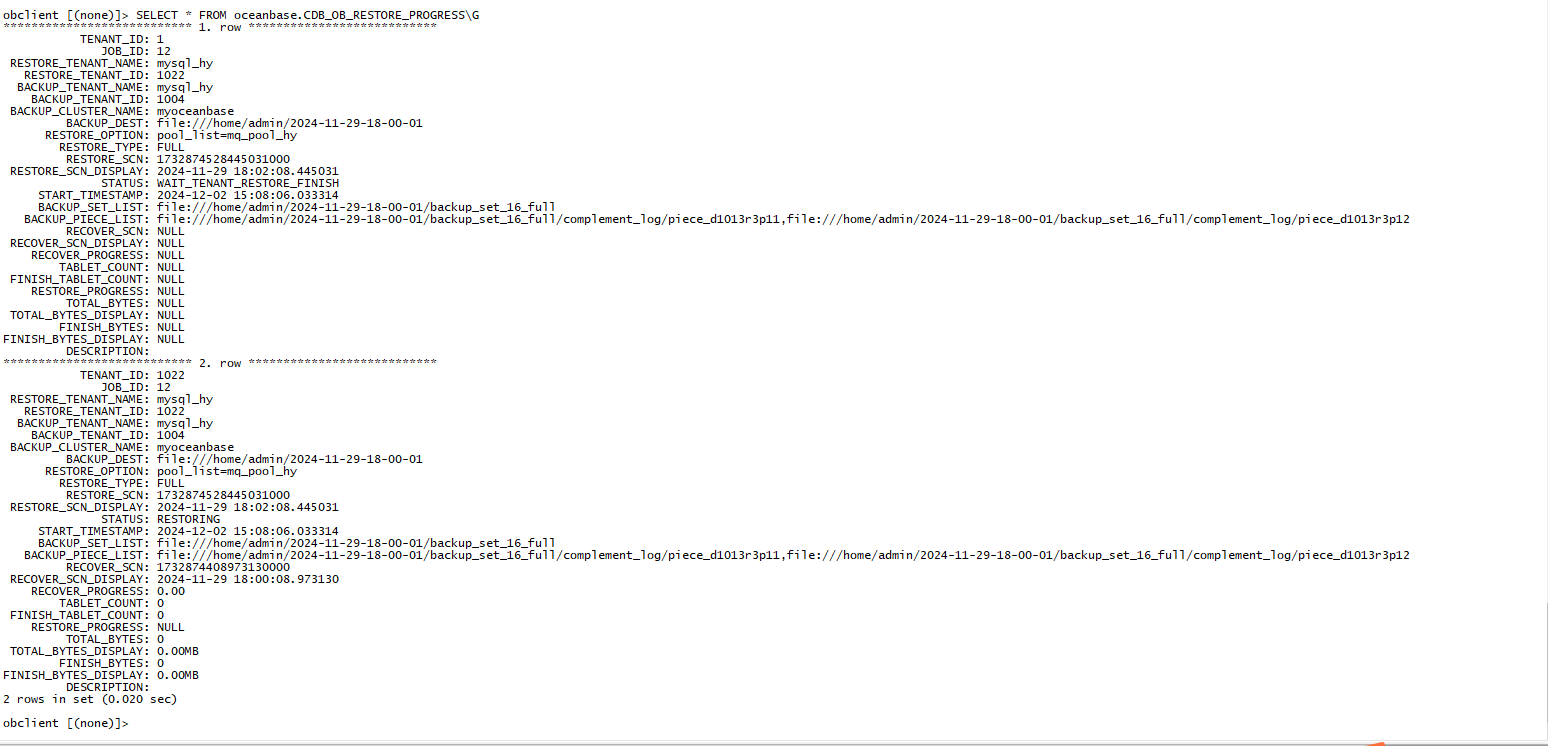
200M的数据恢复了一小时,还是一直处于RESTORING,进度一直不变化
rootservice.log 如下

【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转
【 使用环境 】生产环境
【 OB or 其他组件 】
【 使用版本 】
社区版本4.3.4
【问题描述】清晰明确描述问题
200M的数据恢复了一小时,还是一直处于RESTORING,进度一直不变化
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转
麻烦发下恢复租户的资源池配置以及恢复操作的命令,操作系统类型及版本,完整的observer.log,rootservice.log
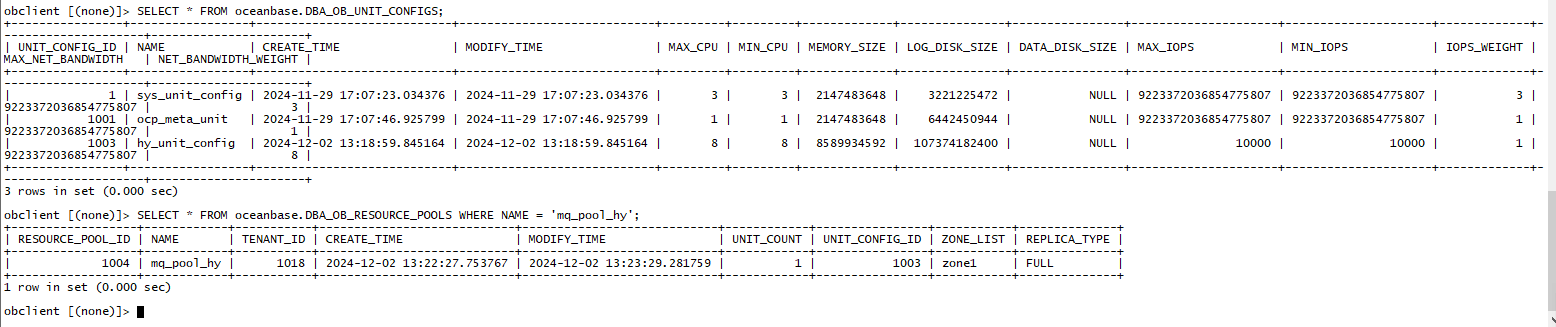
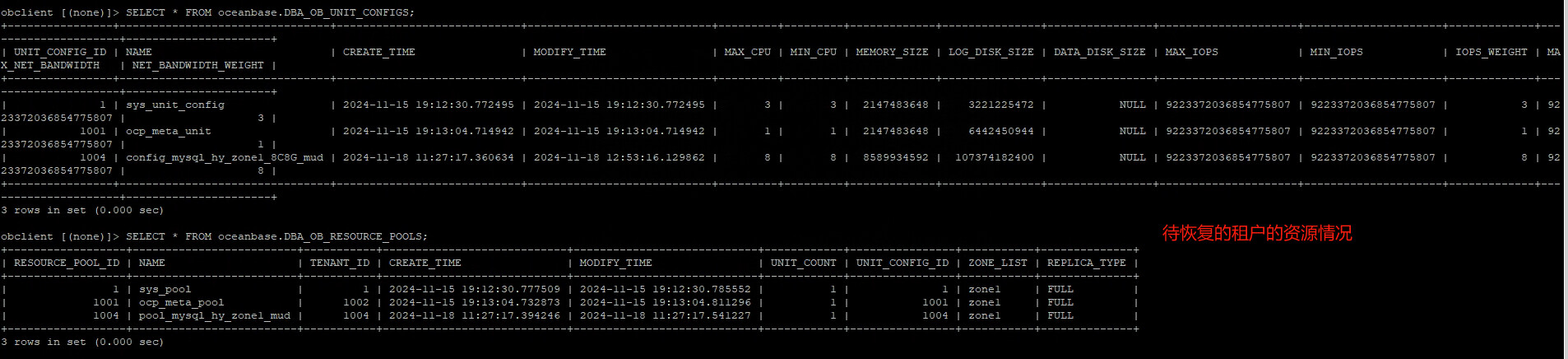
待恢复的目标服务器上新建的恢复租户的资源信息如下
现在恢复完成了吗?
如果没有完成,可以先终止掉,然后麻烦按如下步骤提供下日志
1.开启 Trace 功能
SET ob_enable_show_trace=ON;
2.执行SQL
3.获取SQL trace_id
SELECT last_trace_id() FROM DUAL;
4.登录对应 OBServer 节点,进入到日志文件所在目录
cd /home/admin/oceanbase/log
5.获取trace_id对应的日志
grep xxxxxxx observer.log --填写第3步获取的trace_id
grep xxxxxxx rootservice.log --填写第3步获取的trace_id
[root@localhost log]# grep YB42C0A800AF-000628430C9EF362-0-0 observer.log
[2024-12-02 14:00:03.692200] WDIAG begin (ob_hashtable.h:954) [2320098][T1_L0_G0][T1][YB42C0A800AF-000628430C9EF362-0-0] [lt=18][errcode=-4006] hashtable not init, backtrace=0x11ab55d8 0xec3e43c 0xea3fb64 0xd6f8c68 0x11aa29f0 0xfe97a38 0x11745b64 0x115ba780 0x114db018 0x114d8de4 0x11662ad4 0x11489e80 0x1147a620 0x11474c34 0x11473364 0x11464dc0 0xbad89ec 0x1b954c24 0xffff86b92508 0xffff86bf9cdc
[root@localhost log]# grep YB42C0A800AF-000628430C9EF362-0-0 rootservice.log
[root@localhost log]# grep YB42C0A800AF-000628430C9EF362-0-0 rootservice.log
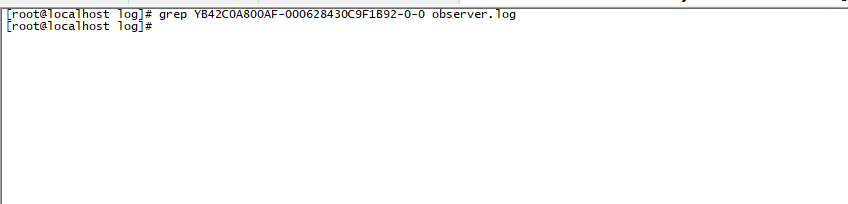
第二条grep没有返回数据
这个日志不全,可以先终止掉原先的恢复,然后按上面的步骤取下日志吗
1.上面我上传的日志文件,也不全么2.终止恢复后,在重新执行恢复,在截取日志么3.您上面说的2执行sql的意思是运行这条语句么ALTER SYSTEM RESTORE mysql_hy FROM ‘file:///home/admin/2024-11-29-18-00-01’ WITH ‘pool_list=mq_pool_hy’;
是的,终止后再次执行恢复,然后获取日志,
另外200M的数据到现在还没恢复完 应该就恢复不完了 大概率哪里有问题了
是的,步骤2就是执行restore那条SQL
好的 上面就是先停止,在执行恢复,trace的日志,麻烦看下吧
上面日志是正常的,再根据上面的traceid获取下最新日志发下,看看有没有报错出来
grep xxxxxxx observer.log --填写第3步获取的trace_id
grep xxxxxxx rootservice.log --填写第3步获取的trace_id
1.是的,rootservice日志没有变化,observer.log grep出来为空是指生成了新的observer.log 然后grep出来为空是吧?
2.另外备份租户和恢复租户的集群版本一致吗?都是4.3.4吗?
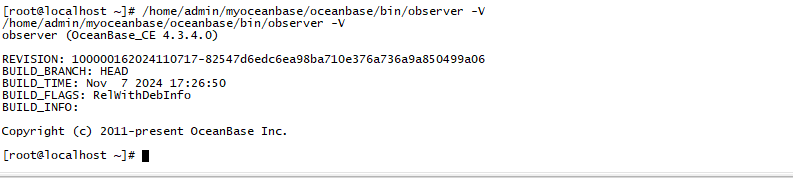
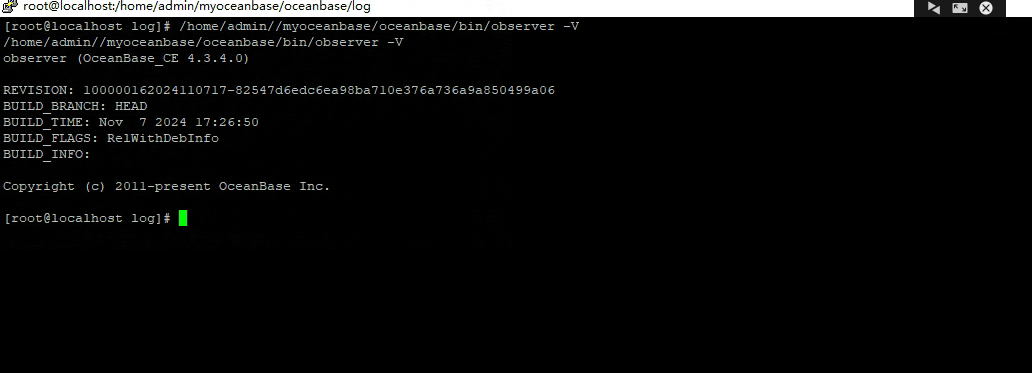
/home/admin/oceanbase/bin/observer -V 看下,根据安装的实际路径修改
3.你这里备份是通过 PLUS ARCHIVELOG 方式发起的吗?,若是是通过 PLUS ARCHIVELOG 方式发起的只需要填一个路径即可,否则需要分别输入数据备份和日志归档至少 2 个路径,例如:‘file:///backup/archive, file:///backup/data’
1.observer.log打印的太快了,5分钟,就切片了,现在的日志找不到这个Trace_id的日志了
2.版本一直,用的同一个离线包安装的,刚才确认了下,是一致的
3.用的是ALTER SYSTEM BACKUP DATABASE PLUS ARCHIVELOG;打开的备份
好的,/home/admin/oceanbase/bin/observer -V 麻烦发下具体版本号,
你是在15:08发起的restore,2~3小时后再grep rootservice.log 发下
是的,rootservice.log也会滚掉,可以调整保留日志个数,调整这个参数max_syslog_file_count,生产环境建议在空间允许的情况下尽量多保留observer的日志
https://www.oceanbase.com/knowledge-base/oceanbase-database-1000000001300755?back=kb
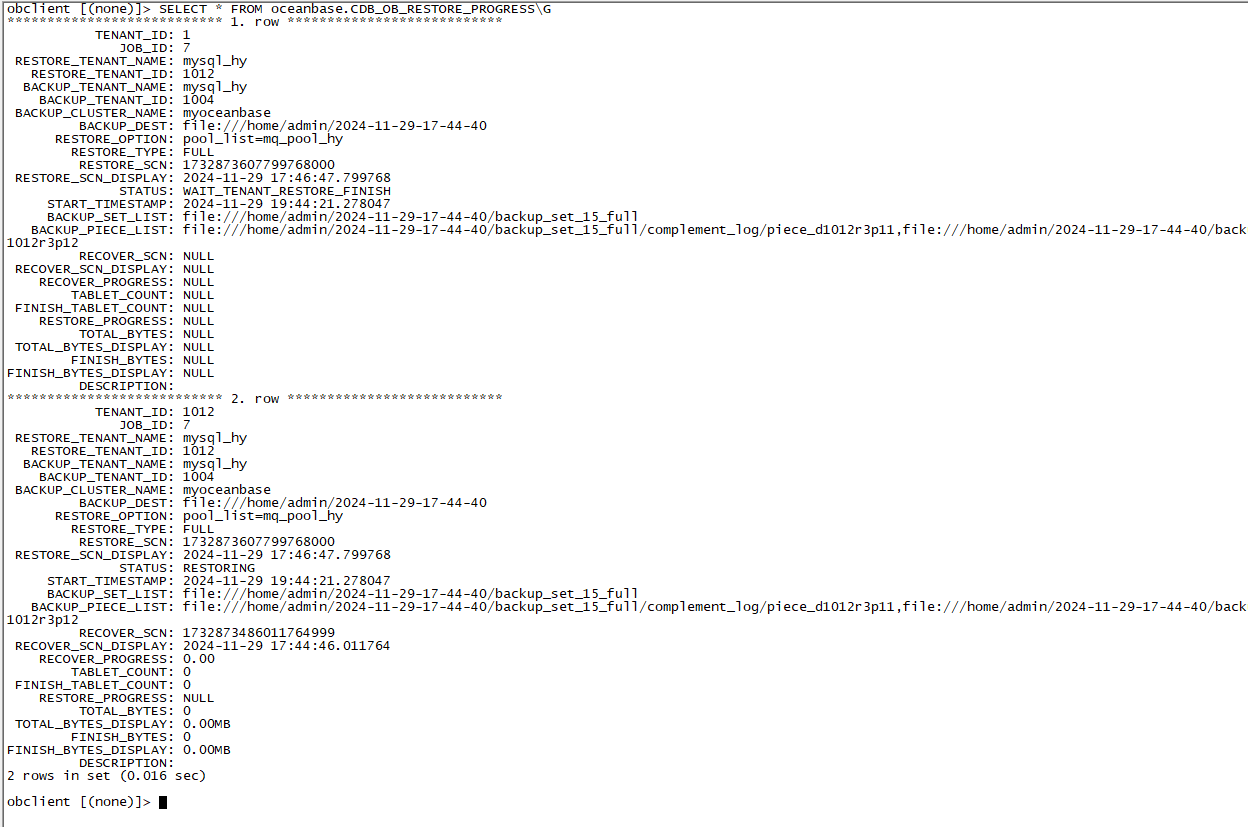
查看恢复进度
SELECT * FROM oceanbase.CDB_OB_RESTORE_PROGRESS\G
查看物理恢复结果
SELECT * FROM oceanbase.CDB_OB_RESTORE_HISTORY\G
1.我没配置保留策略,但是现在只有一个rootservice.log文件,而且最新的时间是16.02的,之前的找不到了
我咨询下这块的研发老师,有进展尽快回复你