rocH
#1
【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】OB
【 使用版本 】4.2.1-8BP
【问题描述】
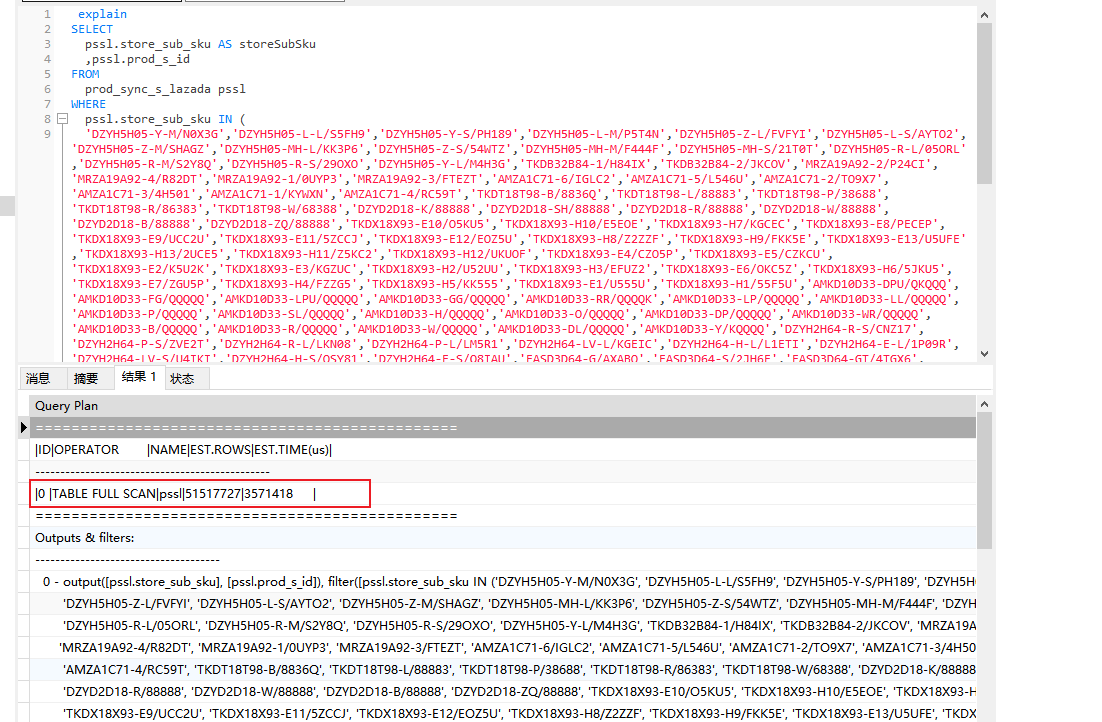
生产有张数据表 prod,数据量超过30G。 有个varchar(200)的字段 sku, 建了个前缀索引, sku(16)
当执行以下查询,执行器不会使用索引,而是全表扫描
【
select * from prod
where sku in ( 超过10个样本).
】
而如果in(10个以内的样本)就会走索引。
如何不通过代码侵入的方式, 优化执行器的逻辑。 4.3版本会有这个问题吗
8 个赞
旭辉
#3
麻烦使用obdiag分别收集下in内参数10个以上和10个以下的sql执行信息
obdiag gather scene run --scene=observer.perf_sql [options]
https://www.oceanbase.com/docs/common-obdiag-cn-1000000001768268
4 个赞
banjin
#4
2 个赞
rocH
#5
我把索引改成了 整个字段索引。 然后多查询了一个 prodSId字段。
解释器也不使用索引。
这种大表,但凡触发回表的,有索引都不走索引了。 这个逻辑也太不友好了···
3 个赞
旭辉
#7
可以将我上面发的信息收集下,如果分析结果是优化器的缺陷,会排期修复的
1 个赞
rocH
#8
执行 obdiag gather plan_monitor --trace_id 命令收集如下信息
以下是in查询 7个sku的收集信息
obdiag_gather7.zip (173.4 KB)
以下是in查询 1000个sku的收集信息
obdiag_gather1000.zip (184.2 KB)
2 个赞
淇铭
#10
执行计划explain extended sql的时候 绑定一下hint /*+monitor */ obdiag收集的时候 没有什么信息 重新用obdiag分别收集下in内参数10个以上和10个以下的sql执行信息
obdiag gather scene run --scene=observer.perf_sql --env “{db_connect=’-hxx -Pxx -uxx -pxx -Dxx’, trace_id=‘xx’}”
2 个赞
rocH
#11
in查询4个
obdiag_gather4.zip (288.5 KB)
in查询1000个
obdiag_gather1000.zip (308.1 KB)
2 个赞
淇铭
#13
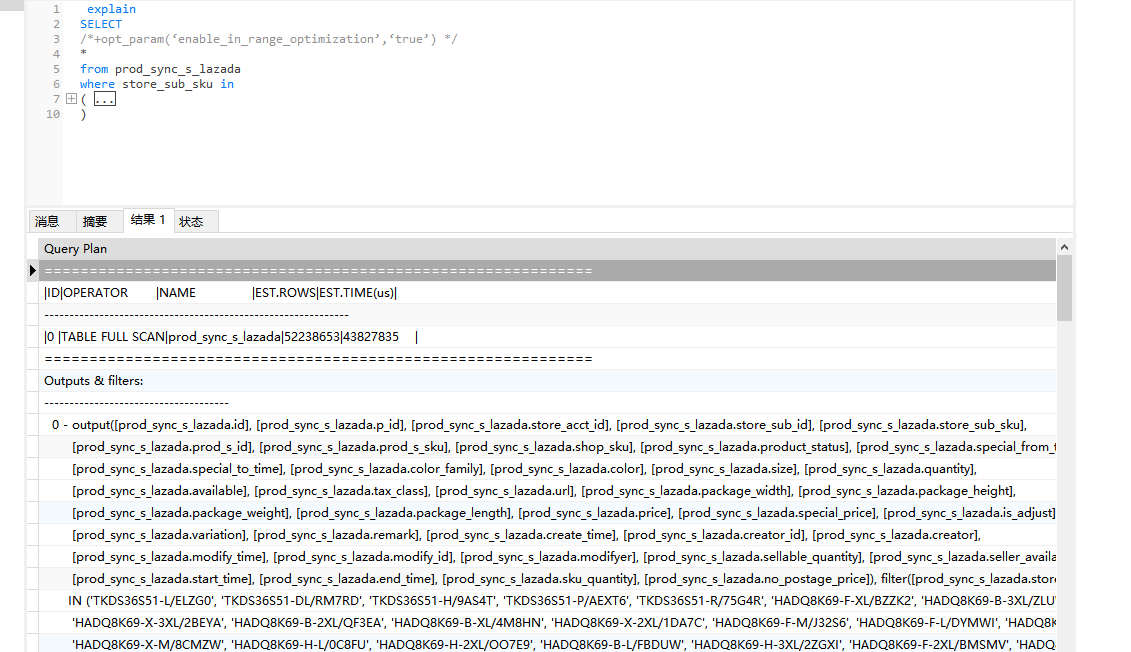
1、大in的时候 多次执行 也是很慢么?绑定一下这个hint /*+opt_param(‘enable_in_range_optimization’,‘true’) */ 看一下执行计划 explain extended 执行一下
2、查一下下面的信息
select * from GV$OB_PLAN_CACHE_PLAN_STAT where SQL_ID=‘5E28DD60FAB109DE0850912259704429’ and PLAN_ID=‘43358462’\G;
2 个赞
rocH
#14
1、多次查询也很慢
2、
新建 XLSX 工作表 (2).zip (9.7 KB)
2 个赞
淇铭
#16
你查询一下 这样是多久查询完 看你的查询 磁盘读很多 数据从磁盘加载到缓存里 时间消耗比较大 表行比较大 如果走索引了 会造成回表 可能比全表扫还要慢
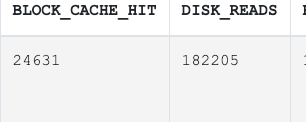
这个语句你是手工执行了一次是么 我看计划缓存并没有去命中 磁盘读消耗的很大

rocH
#17
实际情况是, 走索引会立马出结果。 这个表太大了。加载到内存不太现实。
我们其中一个租户,这张表 200G。
一个租户30G。
200G的那个,查询短时间出不来结果。
30G大概需要80s左右出结果。
但是强制走索引的话,是秒出结果的
几十甚至几百G的表。 执行器是怎么判断,把表全部缓存,然后逐行扫描更快的···
这个sql问题。 导致整个集群的 磁盘读写一直居高不下
rocH
#18
加这个/*+opt_param(‘enable_in_range_optimization’,‘true’) */ 。
执行需要80s左右
rocH
#19
根据其他几张大表。并且建有 字符串前缀索引的。 发现都是一样的情况。
当我把字符串索引改为 全索引。然后重新收集一遍统计信息, 大in查询就会走索引了。
其他同样数据量的表,当索引不是前缀索引。 大in查询是会正常走索引的
淇铭
#20
你是执行的200g的还是30G的 sql加hint的
淇铭
#21
前缀的索引 你字符串长度计算过没有 根据长度的计算 过滤数据比例
淇铭
#22
回表代表着是走索引 才会回表的 如果执行计划的回表 代价比较高 可能就会不走索引了 直接全表扫了