

oceanbase 向量数据库 查询时,谓词条件中同时出现 向量和标量 ,此时过滤的先后顺序是什么?
1、先向量后标量?
2、能否指定谓词执行的先后顺序呢?
谓词的执行顺序通常由数据库的查询优化器决定,它会根据统计信息和成本估算来选择最优的执行计划。
如果需要控制谓词执行的顺序,可以考虑以下两种方法:
-
使用子查询:通过将一部分谓词放在子查询中,可以间接控制谓词的执行顺序。例如,先在一个子查询中应用向量相关的过滤条件,然后再在外层查询中应用标量的过滤条件。
SELECT *
FROM (
SELECT *
FROM table_name
WHERE vector_condition
) AS subquery
WHERE scalar_condition; -
使用 Hint:可以尝试使用其他 Hint 来影响查询计划,例如 /*+ LEADING / 或 /+ INDEX */ 等,以达到控制执行顺序的目的。
背景是这样的:
假设有这样的一个场景:前置标量过滤,就是先指定某个用户uid的数据里面再用特征向量搜索。
但是看了向量数据库的标量过滤主要是后置过滤,就是先按向量搜索了结果再通过标量来过滤数据返回。
所以 是不是可以这样理解? 如果数据库底层分片的向量数据库(按标量分片分区的),是不是都是标量前置搜索呢?
标量过滤后置,向量索引是全局的,并不能按照某个标量划分之后再建向量索引。可能会出现标量过滤之后搜索不出数据的问题。
CREATE TABLE t1(
c1 INT,
c2 VECTOR(3),
PRIMARY KEY(c1),
VECTOR INDEX idx1(c2) WITH (distance=L2, type=hnsw)
);
INSERT INTO t1 VALUES(1, '[0.203846, 0.205289, 0.880265]');
INSERT INTO t1 VALUES(2, '[0.735541, 0.670776, 0.903237]');
INSERT INTO t1 VALUES(3, '[0.327936, 0.048756, 0.084670]');
--------------------------------------------------
查询结果返回一行:
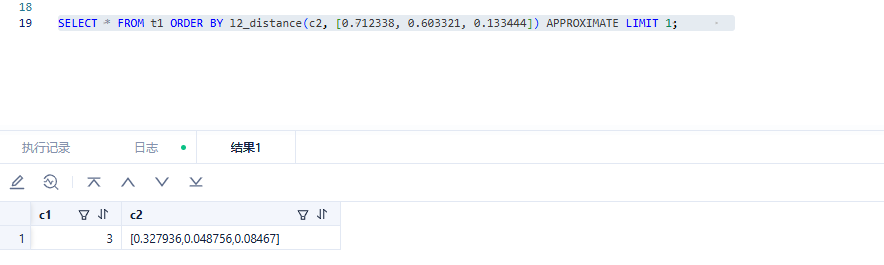
--------------------------------------------------
查询结果返回三行:
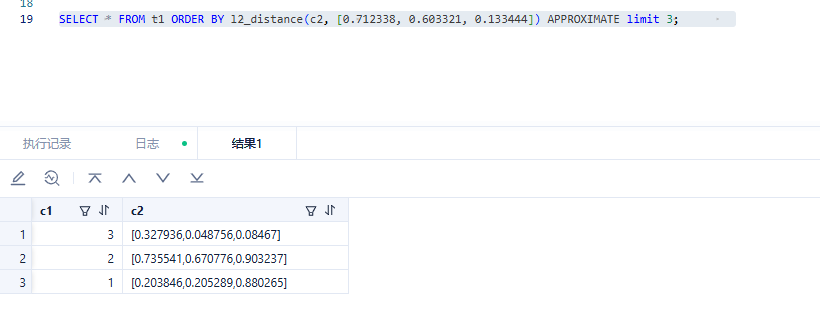
--------------------------------------------------
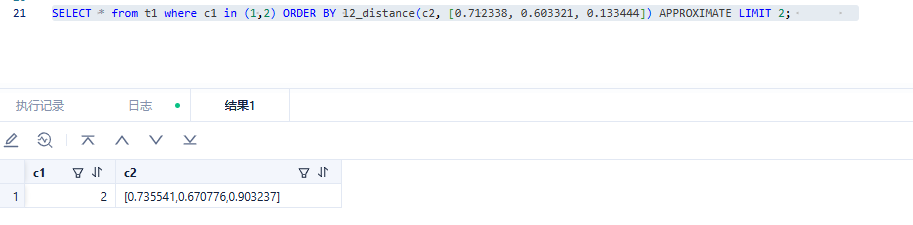
--------------------------------------------------
而如下语句查询是空,但是我的意思想查询c1为1或者2的,如上,理论上也会有返回才对(c1=2的记录)。但是这样好像有维度切割。
SELECT * from t1 where c1 in (1,2) ORDER BY l2_distance(c2, [0.712338, 0.603321, 0.133444]) APPROXIMATE LIMIT 1;
不知道 这个场景是不是在向量查询中 是不允许的?就是想标量前置过滤。
我咨询下这块的老师,有进展会尽快回复你
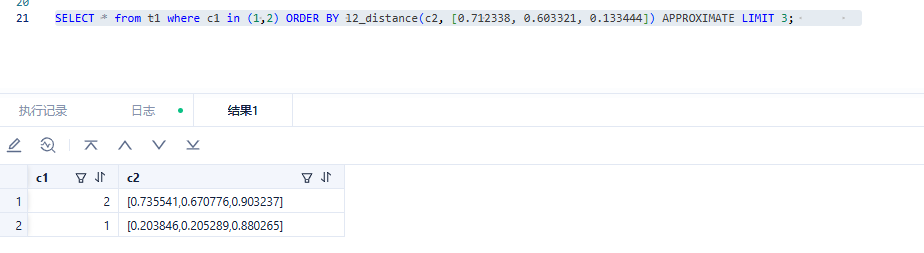
当前需要扩大limit数量,pre-filter可以解决这个问题,在435bp1会解决这个问题
例如:
obclient [test]> SELECT * from t1 where c1 in (1,2) ORDER BY l2_distance(c2, [0.712338, 0.603321, 0.133444]) APPROXIMATE LIMIT 2;
±—±-----------------------------+
| c1 | c2 |
±—±-----------------------------+
| 2 | [0.735541,0.670776,0.903237] |
±—±-----------------------------+
1 row in set (0.008 sec)
这个case是知道c1=2后,才 APPROXIMATE LIMIT 2 查询出想要的结果,是一个预设场景,但是在实际开发中,这个预设场景是不可能存在的。
这里是在435bp1内测环境查询的,435bp1会解决这个问题