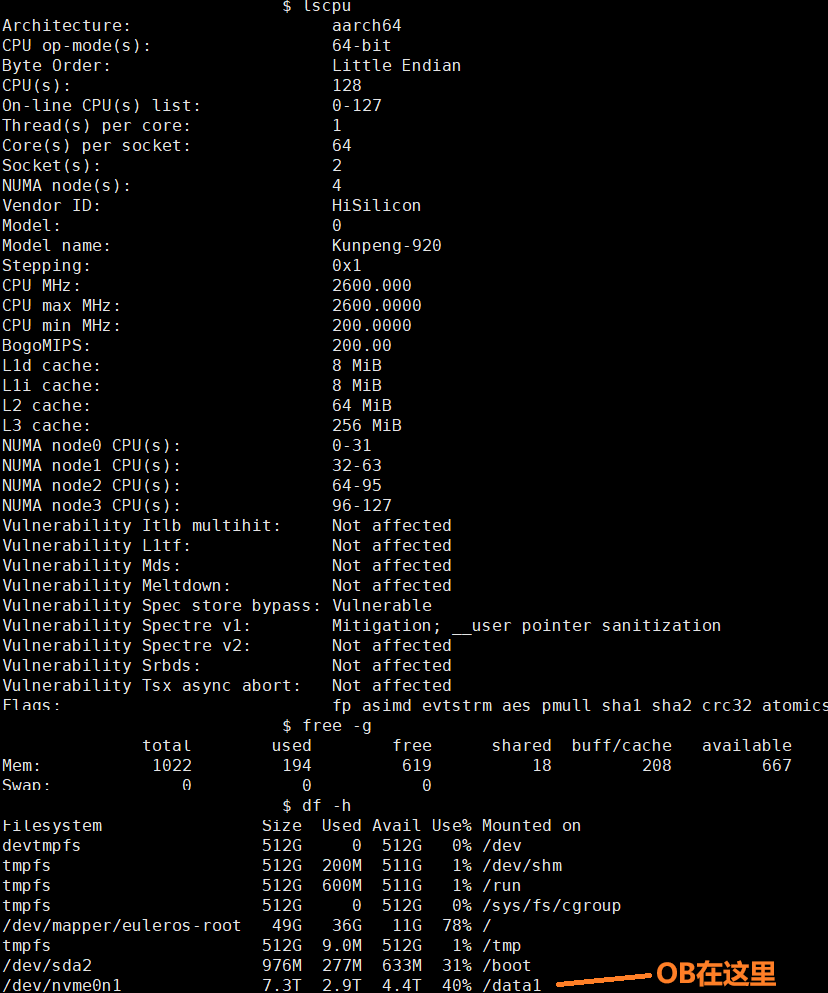
【 使用环境 】测试环境,单机all-in-one部署demo集群,单机规格128核+1T内存+磁盘单盘5T
【 使用版本 】社区版 V4.3.3
【问题描述】按照官方文档操作 https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000001428761
在导入数据步骤超时
$ python load.py // 2024-10-24 晚上8点多开始执行
(0, ‘’)
(0, ‘Tables_in_tpch\ncustomer\nlineitem\nnation\norders\npart\npartsupp\nregion\nsupplier’)
(0, ‘’)
(1, ‘ERROR 4012 (HY000) at line 1: Timeout\n[127.0.0.1:2882] [2024-10-25 06:00:22.146796] [YB427F000001-0006253762A7B79F-0-0]’)
(0, ‘’)
(提问时load.py还在执行中,6点timeout的是lineitem表)
各tbl大小如下:
2.3G customer.tbl
75G lineitem.tbl
2.2K nation.tbl
17G orders.tbl
12G partsupp.tbl
2.3G part.tbl
389 region.tbl
137M supplier.tbl
【obd cluster edit-config demo】
oceanbase-ce:
global:
appname: demo
max_syslog_file_count: 4
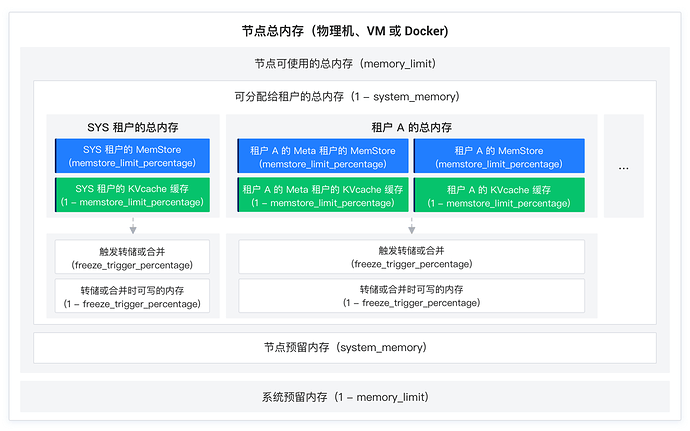
memory_limit: 300G // 自定义配置
production_mode: false
__min_full_resource_pool_memory: 1073741824
system_memory: 20G // 自定义配置
cpu_count: 128 // 自定义配置,初始值为126
datafile_size: 2G
datafile_maxsize: 8G
datafile_next: 2G
log_disk_size: 512G // 自定义配置
(未加“自定义配置”注释 和 未列出的其他参数均为默认值)
【sys租户SET】
ALTER SYSTEM SET system_memory=‘15g’;
ALTER RESOURCE UNIT sys_unit_config memory_size =‘15G’;
ALTER SYSTEM SET trace_log_slow_query_watermark=‘100s’;
ALTER SYSTEM SET enable_sql_operator_dump=True;
ALTER SYSTEM SET _hash_area_size=‘3g’;
ALTER SYSTEM SET memstore_limit_percentage=50;
ALTER SYSTEM SET enable_rebalance=False;
ALTER SYSTEM SET memory_chunk_cache_size=‘0M’;
ALTER SYSTEM SET major_compact_trigger=5;
ALTER SYSTEM SET cache_wash_threshold=‘30g’;
ALTER SYSTEM SET syslog_level=‘ERROR’;
ALTER SYSTEM SET max_syslog_file_count=100;
ALTER SYSTEM SET enable_syslog_recycle=‘True’;
【测试租户创建语句】
资源规格:
CREATE RESOURCE UNIT unit_tpch
MEMORY_SIZE = ‘200G’,
LOG_DISK_SIZE = ‘300G’,
MAX_CPU = 120;
资源池:
CREATE RESOURCE POOL pool_tpch
UNIT = ‘unit_tpch’,
UNIT_NUM=1,
ZONE_LIST = (‘zone1’);
租户:
CREATE TENANT IF NOT EXISTS tenant_tpch
PRIMARY_ZONE=‘zone1’,
RESOURCE_POOL_LIST =(‘pool_tpch’)
set OB_TCP_INVITED_NODES=’%’;
【测试租户SET】
SET GLOBAL ob_sql_work_area_percentage=80;
SET GLOBAL optimizer_use_sql_plan_baselines = true;
SET GLOBAL optimizer_capture_sql_plan_baselines = true;
ALTER SYSTEM SET ob_enable_batched_multi_statement=‘true’;
SET GLOBAL ob_query_timeout=36000000000;
SET GLOBAL ob_trx_timeout=36000000000;
SET GLOBAL max_allowed_packet=67108864;
SET GLOBAL secure_file_priv="/";
SET GLOBAL parallel_servers_target=1000;
【其他】
load.py中的 load data 语句并行度为120:load data /*+ parallel(120) */
1.customer表(2.3G)可以正常导入
2.lineitem表(75G)导入超时
用top观察,load lineitem表时,前几分钟的CPU占用率为6000左右,之后一直在100上下,和observer的CPU占用相当,观察表数据发现6000的时候没有数据,100的时候在持续导入数据
测试租户是Mysql模式,使用root登录的,求问是不是有什么配置不对,并行度怎么上不去?